[Paper] https://arxiv.org/pdf/2405.12970
[Github] https://github.com/FaceAdapter/Face-Adapter
GitHub - FaceAdapter/Face-Adapter
Contribute to FaceAdapter/Face-Adapter development by creating an account on GitHub.
github.com
1. Introduction
기존의 face reenactment와 swapping 은 GAN 모델을 많이 사용했습니다. 최근에는 GAN 대신 diffusion 모델을 많이 사용하는 추세인데요, 하지만 diffusion은 아래와 같은 여러 문제점이 존재합니다.
- 학습이 힘들다.
- 큰 pose 변화와 학습 중 배경에 대한 정보 부족으로 인한 blurry
- text를 사용한 attribute 설정에 중점을 둠() => image spatial control 약화, 얼굴과 자세를 제어하는데 많은 제약을 둠
이러한 문제점을 해결하기 위해 본 논문에서는 pre-trained diffusion 모델을 사용하여 high-precision, high-fidelity 를 갖는 Face-Adapter를 제안합니다. 이 Face-Adapter 는,
- 정확한 landmark와 background 를 제공하는 Spatial Condition Generator
- face embedding을 transformer decoder를 통해 text space 로 전환하는 Plug-and-play(즉시 시작) Identity Encoder
- spatial condition과 세부 속성들을 통합하는 Attribute Controller
를 포함합니다. 각 구성 요소 별 자세한 설명은 다음 절을 참고해주세요!
2. Method
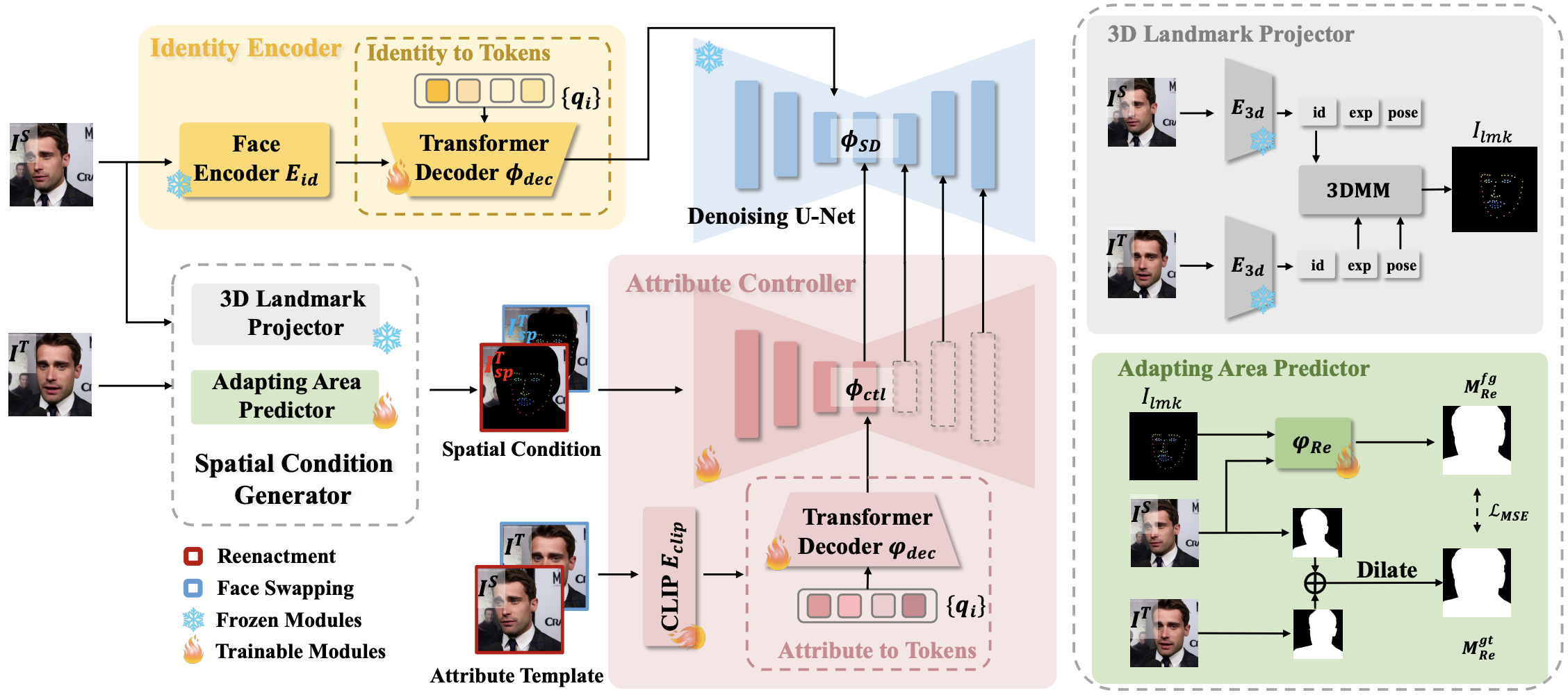
본 논문에서 제안하는 Face-Adpater는 target 이미지의 motion에 해당하는 포즈, 표정, 시선을 기반으로 조명, 배경, 머리카락 등의 속성을 template이미지에 identity를 통합하는 것을 목표로 합니다.
본격적인 설명에 앞서 본 논문에서 face reenactment와 swapping 에서 정의하는 source와 target은 아래와 같습니다.
- face reenactment : target 이미지에서 자세와 표정만 가져와 source 이미지를 변화시키는 것(이목구비, 배경, 머리는 유지)
- source => 내가 쓸 이목구비, 배경, 머리스타일이 있는 이미지 / target => 표정, 자세를 가져올 이미지
- face swapping : target 이미지에서 얼굴만 바꾸는것, 배경 + 표정 + 자세+헤어는 target 이미지와 동일
- source => 이목구비 이미지 / target => 템플릿 이미지

2.1 Spatial Condition Generator
subsequent controlled generation을 보다 합리적이고 정확하게 생성하기 위한 모듈입니다. 본 모듈은 2개의 sub-module로 구성됩니다.
2.1.1 3D Landmark Projector
얼굴 형태 차이에 대한 문제를 해결하기 위해, 3D facial reconstruction 방법을 사용합니다. source 와 target 이미지에서 identity, expression을 개별적으로 추출하고 pose 계수를 구합니다. 그 다음, source의 identity 계수를 target의 expression 및 pose 계수와 재결합하고 새로운 3D 얼굴을 재구성한 후 projection하여 landmark를 획득합니다.
2.1.2 Adapting Area Prediction
아래 그림에서 알 수 있듯이 배경은 시시각각 변합니다.

만약 모델이 이러한 배경 변화에 대한 정보가 부족하다면 생성된 이미지들의 흐린 배경을 갖게 됩니다.
face swapping의 경우 target background를 제공해주면 environmental lighting 와 spatial references에 대한 정보를 모델에 제공해 줄 수 있습니다. 이렇게 배경에 제약 사항을 추가함으로써 모델 학습을 좀 더 쉽게 만들고 conditional inpainting 으로 task를 축소 할 수 있습니다. 이러한 방식을 사용함으로써 모델은 배경 일관성을 유지하고 배경 consistency과 완벽하게 통합되는 이미지를 생성하는 것이 가능해졌습니다.
2.2 Identity Encoder
IP-Adapter-FaceID 및 InstantID에서 주장하는바와 같이 높은 수준의 face embedding은 보다 강하게 identity를 보존 할 수 있습니다. 본 논문에서 주장하는바는 face reenactment에는 무거운 texture encoder나 추가적인 identity network가 필요하지 않습니다.
구체적으로, 얼굴 이미지 I^S가 주어지면 pre-trained face recognition model인 E_id 를 통해서 face embedding f_id를 얻습니다. 그 다음, 3 layer transformer decoder인 ϕ_dec이용해 face embedding 값을 text semantic space에 projection 시켜 identity tokens을 구합니다. 이러한 과정을 거치기 때문에 pre-trained diffusion model인 U-Net을 face embedding 값을 얻기 위해 fine-tuning하지 않아도 됩니다.
2.3 Attribute Controller
2.3.1 Spatial Control
ControlNet에 맞춰 U-Net ф_Ctl의 복사본을 만들고 spatial control I_Sp를 조건 입력으로 추가합니다. spatial control 이미지들은 target motion landmarks인 I^T_lmk와 Adapting Area Predictor인 φ_Re를 통해서 얻은 non-adapting area를 결합하여 얻습니다.
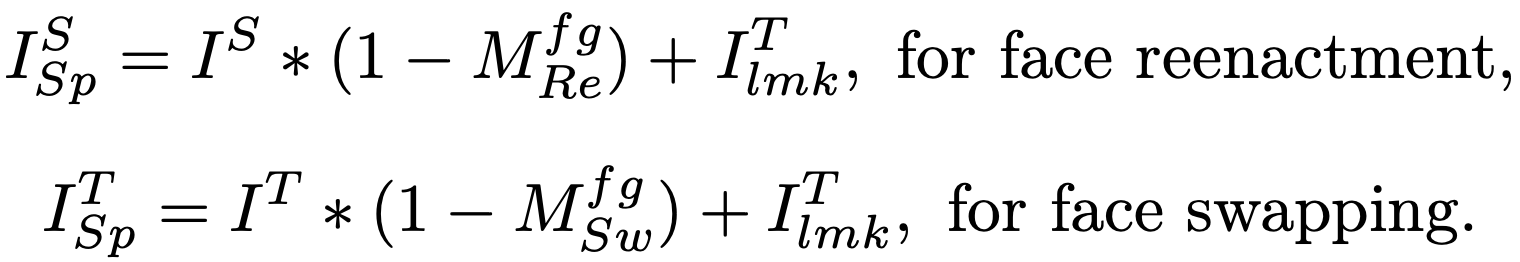
2.3.2 Attribute Template
배경에 대한 identity와 spatial control이 주어지면 attribute template은 조명, 배경, 머리카락을 포함하여 누락된 정보를 보완하도록 설계되었습니다. Attribute embeddings인 f_attr은 CLIP E_clip을 사용하여 attribute template에서 추출됩니다. 또한, loca/global feature를 모두 얻기 위해 patch token과 the global token을 모두 사용합니다.
2.4 Strategies for Boosting Performance
2.4.1 Training
1) Data Stream: face reenactmen와 face-swapping 모두 source와 target 이미지로 동일 인물의 서로 다른 pose 이미지 2장을 사용합니다. 하나의 모델로 두 개의 task가 가능하도록 하기 위해 50%의 확률로 두 개의 task에 해당하는 Data Stream을 선택하도록 합니다. Attribute Controller 의 spatial control 와 attribute template은 위 구조도의 각각 빨간색과 파란색으로 표시된 Data Stream을 사용합니다.
2) Condition Dropping for Classifier-free Guidance: drop되는 condition에는 U-Net 과 ControlNet 의 cross-attention에 입력되는 identity tokens 과 attribute token입니다. 이는 5% 확률로 진행됩니다.
2.4.2 Inference
1) Adapting Area Predictor : face reeancment 의 경우 input은 source 이미지와 수정된 landmark이고 output은 adapting area입니다. swapping은 input이 target image이고 output이 adapting area입니다.
2) Negative Prompt for Classifier-Free Guidance: face reeancment 의 경우 Negative Prompt에 아무것도 입력되지 않습니다. swapping은 target identity의 부정적인 영향을 줄이기 위해 target 이미지의 identity tokens을 Negative Prompt로 사용합니다.
3. Experiments
3.1 Cross-identity face reenactment results on Voxceleb2

3.2 Face swapping qualitative comparison results on Voxceleb2 test set
