▶ 손실 함수(Loss Function == Cost Function)란?
손실함수는 신경망 성능의 '나쁨'을 나타내는 지표입니다. 정답과 비교했을 때 신경망이 학습 데이터를 얼마나 잘 처리했는지, 못 처리했는지를 나타냅니다. 이 값이 높을수록 모델이 좋지 않다는 것을 의미합니다. 이 지표의 값을 바탕으로 학습을 하면서 모델의 적절한 가중치를 찾아 나갑니다. 손실 함수는 사용자가 임의의 함수를 정의해 사용할 수도 있지만 일반적으로는 '평균 제곱 오차'와 '교차 엔트로피 오차'를 사용합니다.
▶ 손실 함수를 설정하는 이유?
신경망 학습에서 '미분'의 역할을 생각해보면 됩니다. 신경망 학습에서 최적의 가중치를 찾을 때 손실 함수의 값을 가능한 작게 하는 매개변수 값을 찾습니다. 이때 매개변수의 미분을 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복합니다.
미분 값이 음수면, 그 가중치 매개변수를 양의 방향으로 변화시켜 손실함수 값을 줄이고 양수면 음의 방향으로 변화시킵니다.
그런데 만약 미분 값이 0이라면..?
가중치 배개변수를 어느 쪽으로 움직여도 손실 함수의 값은 달라지지 않고, 가중치 갱신은 거기서 멈춥니다. 정확도를 지표로 삼아 밉분 값을 구하면 대부분의 장소에서 0이 되게 됩니다. 또한 정확도는 연속적 값이 아닌 33%, 35%와 같이 불연속적인 값으로 변하기 때문에 민감하게 반응하지도 못합니다.
이러한 이유들로 신경망을 학습할 때 정확도를 지표로 삼지 않고 손실함수를 설정하여 그 값을 지표로 삼는것입니다.
▶ 다양한 손실 함수들
● 평균 제곱 오차(Mean Squared Error, MSE)
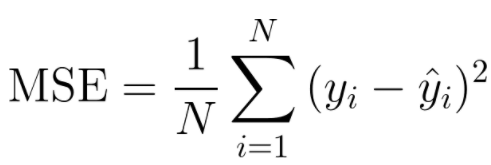
예측한 값과 실제 값 사이의 평균 제곱 오차를 정의합니다. 차가 커질수록 제곱 연산으로 인해서 값이 더 뚜렷해집니다. 이 함수는 주로 Regression(회귀)에 사용됩니다.
● 루트 평균 제곱 오차(Root Mean Squared Error, RMSE)

MSE에 루트를 씌운 함수로 기본적으로 MSE와 동일합니다. MSE는 오차의 제곱이기 때문에 실제 오차의 평균보다 더 커지는 특성이 있는데, 여기에 루트를 씌워 값의 왜곡을 줄여주었습니다.
● 교차 엔트로피 오차(Cross Entropy Error, CEE)

교차 엔트로피 오차는 실제 분포 q에 대해 알지 못하는 상태에서, 모델을 통해 구한 분포 p를 통해 q를 예측하는 것입니다. q와 p가 모두 들어가서 크로스 엔트로피라고 합니다.
머신러닝에서 실제 값(정답) q와 예측 값 p를 모두 알고 있는 경우가 있습니다. 모델은 x%의 확률로 예측했는데, 실제 확률은 몇%인지 알고 있을 때 사용합니다. 실제 값과 예측 값이 맞는 경우 0에 수렴하고 값이 틀리면 값이 커지기 때문에 실제값과 예측 값의 차이를 줄이기 위한 엔트로피라고 생각하면 됩니다.
● 바이너리 교차 엔트로피 오차(Binary Cross Entropy Error, BCEE)

만약 이진 분류기를 훈련한다면 이 함수를 사용하는 것이 적절합니다. 이진 분류기는 True/False 처럼 분류해야할 클래스가 두 개뿐인 분류기를 말합니다. 이 함수가 왜 이진 분류에 적합할까요?
예측값과 실제값이 모두 1로 같다면 손실 함수 값은 아래 처럼 0이 됩니다.
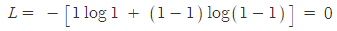

모델이 0을 출력하는 일은 거의 없기 때문에 0과 가까운 값을 출력했을 때 손실함수에서는 아주 큰 수가 나온다고 생각하면 됩니다. 이러한 특성을 갖고 있기 때문에 이진 분류에 적절히 사용될 수 있습니다.
이진 교차 엔트로피 오차는 로그 손실(Log Loss) 또는 로지스틱 손실(Logistic Loss)라고 불리며, 주로 로지스틱 회귀의 손실 함수로 사용됩니다.
● 카테고리컬 교차 엔트로피 오차(Categorical Cross Entropy Error, BCEE)

멀티 클래스 분류 문제에 주로 사용하는 함수입니다. 라벨은 원-핫 형태로 제공될 때 사용됩니다.
● Focal Loss
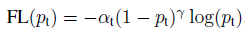
비교적 최근에 나온 손실 함수입니다. (논문 링크 => https://arxiv.org/pdf/1708.02002.pdf)
Focal Loss는 분류 에러에 근거해 Loss에 가중치를 부여합니다. 모델이 특정 클래스의 데이터를 이미 올바르게 분류 했다면 그 클래스에 대한 가중치는 낮아집니다. 즉, 좀 더 문제가 있는 loss에 더 집중하는 방식으로 불균형한 클래스 문제를 해결하였습니다.
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] 최적화 함수(optimizer)의 이해 - 최적화 함수의 정의와 다양한 종류들 (0) | 2023.03.03 |
|---|---|
| [딥러닝 기본지식] 경사 하강법(Gradient Descent)의 이해 - 정의 (0) | 2023.03.03 |
| [딥러닝 기본지식] 활성화 함수(Activation Function)의 이해 - 다양한 활성화 함수의 종류들 (0) | 2023.03.03 |
| [딥러닝 기본지식] 활성화 함수(Activation Function)의 이해 - 활성화 함수란? (0) | 2023.03.03 |
| [Pytorch-기초강의] 경쟁하며 학습하는 GAN (0) | 2023.03.03 |