Github : https://github.com/arxrean/SGG_Ex_RC(unofficial)
<Introduction>
이 논문은 외부 지식 베이스를 이용해 장면 그래프를 생성하고 생성된 장면 그래프를 이용해 이미지를 복원하는 방법에 대한 논문입니다.(게시물에서는 장면 그래프 생성에 중점을 두어 설명하도록 하겠습니다.)
먼저 이 논문에서는 visual genome 데이터 셋의 한계에 대해서 설명합니다.

VG 데이터 집합은 위 그림에서 알 수 있듯이 특정 물체 및 관계에 편향되어 클래스들 간에 매우 심한 불균형이 존재합니다. 또한 이미지 내에 분명 존재하는 관계임에도 annotation되어 있지 않은 등 많은 문제점이 존재합니다.
본 논문에서는 이러한 한계점의 해결 방안으로 ConceptNet이라는 외부 지식 베이스에서 commonsense knowledge를 추출하여 사용합니다. 또한 생성된 장면 그래프를 이용하여 입력 이미지를 재구성한 후, 입력 이미지와 비교하여 패널티를 적용합니다.
<Model>
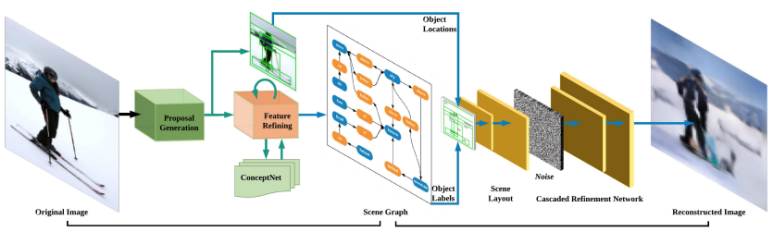
1) Proposal Generation
RPN을 이용하여 N개의 물체 영역을 제안한 후 약 N^2개의 물체 쌍을 생성합니다. 이때 계산상의 이점을 얻기 위해 Factorizable Net의 subgraph 방법을 이용합니다.
2) Feature Refining
이 과정에서 외부 지식 베이스인 ConceptNet이 사용됩니다. 지식 베이스로부터 필요한 지식을 추출하는 방법은 다음과 같습니다.
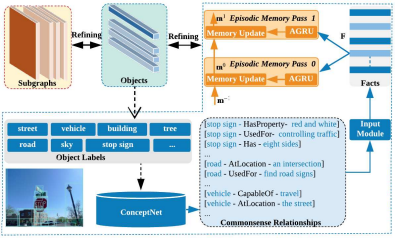
1의 과정에서 얻은 물체 영역의 feature를 이용하여 물체 라벨을 예측하고 예측된 라벨과 관련된 트리플 지식을 conceptnet으로 부터 추출합니다. 추출된 지식들 중 weight가 높은 상위 k의 지식들만 사용합니다.
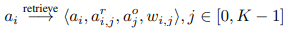
K의 지식들은 RNN-base encoder를 통해 임베딩해 하나의 벡터로 나타냅니다.

물체의 영역들마다 위 과정을 통해 지식이 추출되고 모든 영역들에 대해 추출된 지식을 하나로 합치는 과정은 Memory Network와 GRU를 이용합니다.
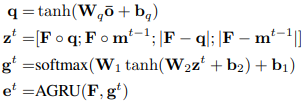
=> 위 과정들을 반복하며 물체 feature들을 여러번 갱신합니다.
3) Scene Graph Generation
최종적으로 갱신된 feature를 이용해 물체 클래스와 관계 클래스를 예측합니다.
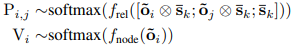
4) Image Generation
이미지 생성은 아래 그림과 같은 과정을 거쳐 이루어집니다.

모든 것을 예측하는 것이 아닌 물체 위치 바운딩 박스에 대한 layout정보가 주어지고 맞는 물체들을 채워 넣는 형식으로 이루어집니다.
<Result>
Dataset
- Visual Genome
- Visual Relationship Detection(VRD)
Metrics
- Phrdet: <subject-predication-object> 예측
- SGGen: 물체 영역, 종류, 관계 모두 예측
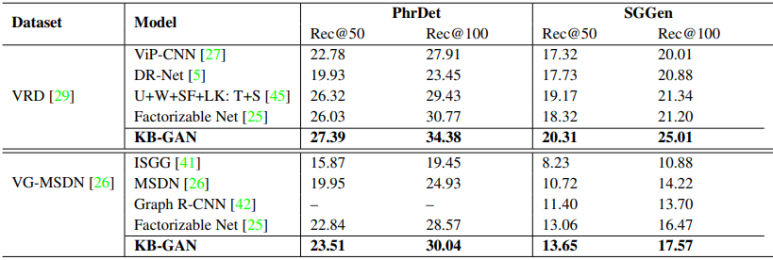
외부 지식 베이스를 사용하는 제안 모델이 가장 높은 성능을 보이고 있음을 확인할 수 있습니다.
<결론>
- 외부 지식 베이스인 conceptNet에서 추출한 지식들을 이용하여 장면 그래프를 생성하는 모델 제안
- 또한, 더 나아가 생성된 장면 그래프로부터 이미지를 복원하는 하나의 프레임워크 제안
'Paper Review > Image Scene Graph Generation' 카테고리의 다른 글
| [9] Relation Transformer Network (0) | 2023.03.07 |
|---|---|
| [8] Bridging Knowledge Graphs to Generate Scene Graphs (0) | 2023.03.07 |
| [6] Exploring the Semantics for Visual Relationship Detection (0) | 2023.03.07 |
| [5] Graph R-CNN for Scene Graph Generation (0) | 2023.03.07 |
| [4] Factorizable Net: An Ecient Subgraph-based Framework for Scene Graph Generation (0) | 2023.03.07 |