논문 링크 : https://arxiv.org/abs/1801.07455
Github : https://github.com/yysijie/st-gcn
GitHub - yysijie/st-gcn: Spatial Temporal Graph Convolutional Networks (ST-GCN) for Skeleton-Based Action Recognition in PyTorch
Spatial Temporal Graph Convolutional Networks (ST-GCN) for Skeleton-Based Action Recognition in PyTorch - GitHub - yysijie/st-gcn: Spatial Temporal Graph Convolutional Networks (ST-GCN) for Skeleto...
github.com
<Intorduction>
이 논문은 행동 인식에 관한 논문입니다.
행동 인식 위해 사용하는 정보들에는 크게 RGB 영상, depth 영상, optical flow(각 픽셀의 움직임 방향 표시), skeleton data가 있습니다. 이 중 논문에서는 skeleton data를 이용한 행동인식 방법을 제안합니다. skeleton data는 사람의 관절의 위치를 표현한 것으로, 시간축에 따라 나타낼 수 있습니다. skeleton data를 이용한 이전의 다른 연구들은 한 frame에서의 관절의 위치 값들을 하나의 feature vector로 나타내고 학습을 시켰습니다. 그러나, 이러한 방식은 행동인식에서의 관절 간의 관계성이 갖는 중요한 정보를 이용할 수 없고, 따라서 학습에 이러한 정보들이 포함되지 않습니다. 본 논문에서는 이러한 문제점을 개선하고 관절들 사이의 시간적,공간적 관계성을 찾아내기 위해 GCN을 이용하였습니다.
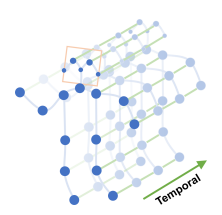
GCN은 그래프 구조의 데이터를 입력으로 받기 때문에 GCN을 사용하기 위해서는 데이터셋을 그래프 모양으로 프로세싱해야 합니다.. 기존의 GCN을 사용한 행동인식의 다른 연구들은, 특정 탐색 규칙 혹은 hand-craft part assignment가 필요했습니다. 본 논문에서는 그런 과정을 생략하고 성능을 향상 시켰을 뿐만 아니라 서로 다른 데이터셋에서 적용해 일반화 시킬 수 있도록 했습니다.
<Model>
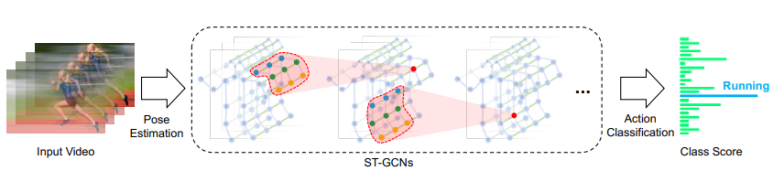
1. Skeleton 추출
동영상으로부터 인물의 skeleton 정보를 추출합니다.
2. 그래프 구조 생성
1에서 추출한 skeleton data를 그래프 형태로 프로세싱합니다. 각각의 관절(joint)들은 노드가 되고, 각각의 노드가 이어지는 부분(공간, 시간)을 edge로 연결합니다. 모든 frame에서 추출한 skeleton의 joint들이 하나하나의 vertex로 구성되고 한 frame 내에서의 주변 joint들과 edge로 연결됩니다(Spatial). 또한 frame 사이에서 같은 joint 끼리도 edge로 연결됩니다(Temporal). 이러한 그래프 구조는 dataset의 종류와 관계없이 모두 동일하게 적용 가능합니다. 그래프에서 노드 집합은 다음과 같이 표기됩니다. T는 frame의 개수, N은 한 skeleton에서 joint의 개수를 의미합니다.

edge의 경우 두 종류(Spatial, Temporal)로 나뉘는데 한 frame 안에서 joint의 edge는 다음과 같습니다. 먼저 spatial은 아래와 같습니다.
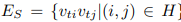
Temporal은 아래와 같습니다.
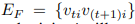
3. feature 추출
총 9개의 ST-GCN 모듈을 통해 feature를 추출합니다. Spatial GCN에 대해 설명하기에 앞서 먼저 기본적인 GCN은 아래와 같은 수식을 갖습니다.
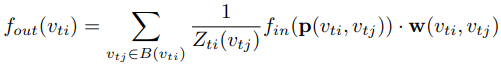
f_in은 그래프의 feature map으로 f_in안의 위치에 있는 값을 갖고옵니다. p는 sampling function을, w는 weight function, Z는 normalize function을 의미합니다.
- Sampling function
이미지의 2D convolution에서 한 픽셀을 기준으로 주변 픽셀들의 정보를 가져오는 함수입니다. 그래프에서는 설계자가 얼마만큼 멀리 있는 이웃에서까지 정보를 가져올지 설정하는데 정해진 룰에 따라 가져올 수 있는 픽셀의 범위가 넓어질 수도 있습니다. 예를 들어 D=1인 거리를 갖는다면, 한 노드의 주변 픽셀은 해당 노드와 바로 연결되어있는 노드들이 되는 것입니다.
-Weight function
위의 sampling function을 통해 얻어진 정보에 weight를 더하는 함수입니다. 그래프의 경우 인접한 것들 사이에 어떤것이 더 가깝고 멀고를 정할 수 없기 때문에 그에 해당하는 weight를 줍니다.
위의 두개의 function을 정리하면 다음과 같습니다.
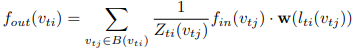
그래프의 시간적 측면을 모델링하는 수식은 아래와 같습니다.
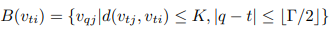
Saptial 과 Temporal 정보를 모두 합치면 아래와 같은 수식이 도출됩니다.
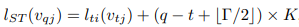
* 논문에서 제안하는 이웃노드를 정의하는 방식
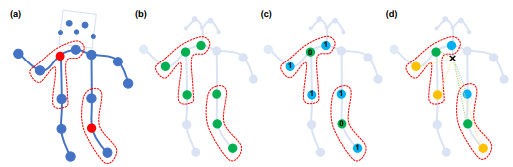
(a) 예시 skeleton graph
(b) Uni-labeling : 거리가 1인 모든 노드를 이웃 노드로 정의
(c) Distance : path의 길이에 따라 weight를 주어 이웃 노드 정의
(d) Spatial configuration : 해당 노드로 부터 중심노드(이미지에서 X표시 된 부분)와의 거리 순으로 weight를 주어 이웃 노드 정의
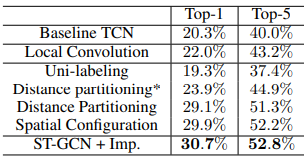
=> 실험을 통해 (d)가 가장 좋은 성능을 내는것을 알 수 있었습니다.
4. 분류하기
softmax 함수를 이용하여 행동을 분류합니다.