Github : https://github.com/jgyy4775/AD-CVR-Prediction
GitHub - jgyy4775/AD-CVR-Prediction
Contribute to jgyy4775/AD-CVR-Prediction development by creating an account on GitHub.
github.com
- Dataset
https://ailab.criteo.com/criteo-sponsored-search-conversion-log-dataset/
Criteo Sponsored Search Conversion Log Dataset - Criteo AI Lab
Dataset release announcement for conversion modeling in sponsored products.
ailab.criteo.com
▶ 데이터 구조
총 23개의 정보로 구성
Sale, SalesAmountInEuro, Time_delay_for_conversion, click_timestamp, nb_clicks_1week, product_price, product_age_group, device_type, audience_id, product_gender, product_brand, product_category(1-7), product_country, product_id, product_title, partner_id, user_id
=> 이중 하늘색 Sale은 정답 라벨로 사용, 분홍색은 모델의 input 데이터로 사용
▶ read_csv 함수를 이용해 데이터를 읽음
self.data=pd.read_csv('CriteoSearchData', delimiter='\t', names=data_names, nrows=1500000)delimiter : 구분자
names : 변수 이름이 없는 파일을 불러올 때 이름 부여
nrows : 전체 데이터 중 몇개의 행만 사용할건지.
▶ Data Processing
1. time 정보는 day, hour, minute로 변경
self.data['click_timestamp'] = self.data["click_timestamp"].map(lambda x: int(x/1000)) # change second
self.data['day'] = self.data["click_timestamp"].map(lambda x: int(x/86400)) # get day
self.data['hour'] = self.data["click_timestamp"].map(lambda x: int(x%86400/3600)) # get hour
self.data['minute'] = self.data["click_timestamp"].map(lambda x: int(x%86400%3600/60)) # get minute(확실하지는 않지만.. )click_timestamp는 1970.01.01 부터 현재까지의 시간을 밀리초로 나눈것으로 판단=> 이걸 day, hour, minute으로 변경
2. product_age_group, device_type과 같은 정보들은 총 몇개의 클래스가 존재하는지 'a'라는 클래스가 몇번 라벨을 갖는지 모르기 때문에 이를 자동으로 매핑해주는 sklearn.preprocessing의 LabelEncoder()함수를 이용해 문자를 숫자로 매핑, 아래 처럼 사용
le = LabelEncoder()
self.data["열 이름"]=le.fit_transform(self.data["열 이름"])
3. sklearn.preprocessing의 MinMaxScaler() 함수를 사용해 0~1 사이로 normalize
mms = MinMaxScaler()
self.data[self.data.columns] = mms.fit_transform(self.data[self.data.columns])
▶ 모델 구성
간단하게 1계층으로만 구성
class CVRModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(CVRModel,self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, self.output_dim),
nn.Dropout(0.3),
nn.Sigmoid()
)
▶ 데이터 분할
- Train Set : 1,000,000
- Test Set : 500,000
▶ 하이퍼 파라미터 설정
BATCH = 20000
EPOCHS = 200
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
## loss 함수
loss=F.binary_cross_entropy(logits.squeeze(), y_train)
▶ Test 정확도
평가 지표 : Accuracy 사용
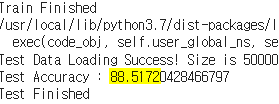
약 88.5172%의 성능을 기록
'My Study > Project' 카테고리의 다른 글
| Apple Machine Learning Research 사이트 (0) | 2023.09.19 |
|---|---|
| 개인 프로젝트 - 채용 공고 추천(프로그래머스-신경망 ver) (0) | 2023.03.09 |
| 개인 프로젝트 - 채용 공고 추천( 프로그래머스) (0) | 2023.03.09 |