프로그래머스에서 제공하는 머신러닝 사전과제 연습 '채용 공고 추천' 입니다.
데이터는 아래 주소에서 과제를 응시한 후 다운 받을 수 있습니다!
https://programmers.co.kr/skill_check_assignments/1
프로그래머스의 채용 공고 페이지를 방문한 이용자들의 방문/지원 기록을 이용하여, 각 이용자가 해당 공고에 지원할지 안할지를 분류하는 문제입니다.
구글 colab에서 진행하였습니다.
▶ 필요 라이브러리 import
import pandas as pd
from google.colab import drive
drive.mount('/content/drive')
▶ 데이터 읽어오기
job_companies=pd.read_csv('job_companies.csv') ## (733, 3)
job_tags=pd.read_csv('job_tags.csv') ## (3477, 2)
tags=pd.read_csv('tags.csv') ## (887, 2)
user_tags=pd.read_csv('user_tags.csv') ## (17194, 2)
train=pd.read_csv('train.csv') ## (6000, 3)
test=pd.read_csv('test_job.csv') ## (2435, 2)
▶ 데이터 구조 확인하기
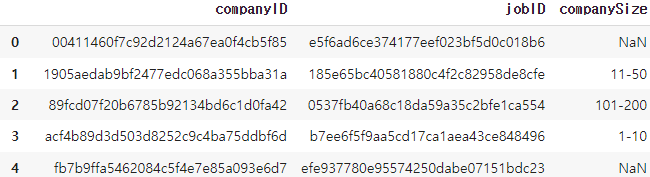
1. job_companies.csv
job과 관련된 회사가 어디인지에 대한 정보를 담고 있습니다. 회사의 규모를 보여주는 필드는 NaN값이 존재하기도 합니다.
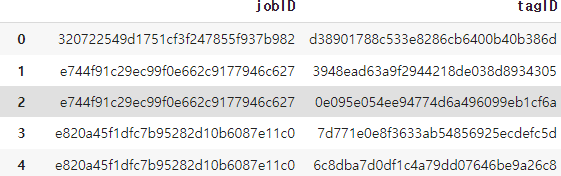
2. job_tags.csv
각 job의 키워드를 나타냅니다. 하나의 job에 여러개의 키워드가 존재할 수 있습니다.
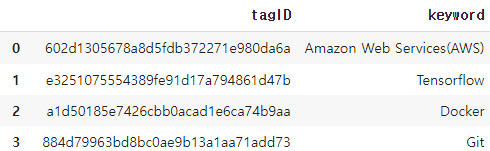
3. tags.csv
tagID가 실제로 무엇을 나타내는지에 대한 정보입니다.
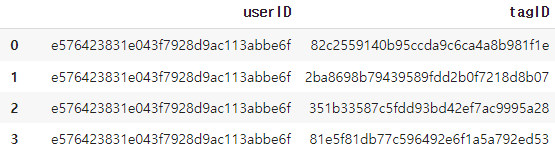
4. user_tags.csv
user가 관심사로 등록한 키워드들을 나타냅니다. 한 명의 user가 여러개의 키워드를 등록할 수 있습니다.
5. train.csv
첫번째는 개발자의 ID, 두번째는 job의 ID, 세번째는 지원 여부를 나타냅니다.
6. test.csv
최종 예측 모델의 입력이 되는 파일입니다.
▶ Feature Engineering
- train과 test 에 'jobID'를 기준으로 'companySize'를 이어붙여 줍니다.
train=train.merge(job_companies[['jobID', 'companySize']], on='jobID')
test=test.merge(job_companies[['jobID', 'companySize']], on='jobID')
trainmerge 함수에 on을 설정해주면 데이터가 같은 행들을 기준으로 병합됩니다. (설명보러가기!)

- 범주형 변수인 ''companySize'를 숫자 값으로 바꿔주기 위해 먼저 데이터를 파악합니다. 추가로 Nan 값의 갯수도 확인해줍니다.
train['companySize'].value_counts()
train['companySize'].isna().sum() ## NAN 값 개수 확인 => 655개
test['companySize'].isna().sum() ## NAN 값 개수 확인 => 248개
1-10, 11-50처럼 범위로 되어있는 값들을 중간 값으로 바꿔주고 Nan 값은 중간값으로 처리해줍니다.
def midd(data):
if data=='1000 이상': return 1000
data=data.split('-')
return (int(data[0])+int(data[1]))//2
train['companySize']=train['companySize'].apply(lambda x:midd(x) if type(x)==str else x)
test['companySize']=test['companySize'].apply(lambda x:midd(x) if type(x)==str else x)
train_mid = train['companySize'].median()
test_mid = test['companySize'].median()
train['companySize']=train['companySize'].fillna(train_mid)
test['companySize']=test['companySize'].fillna(test_mid)
- 매칭률 계산
user가 관심 키워드로 등록한 태그와 job에서 등록한 태그의 매칭률을 계산해주었습니다.
def tag_match(data):
tag = []
user=data['userID']
job=data['jobID']
for u, j in zip(user, job):
# user_tags에서 현재 user와 일치하는 userID의 tagID만 가져옵니다.user의 관심사 키워드를 가져옵니다.
user_tag=user_tags[user_tags['userID']==u]['tagID'].values
# job_tags에서 현재 user의 job과 일치하는 jobID의 tagID만 가져옵니다. job의 키워드를 가져옵니다.
job_tag=job_tags[job_tags['jobID']==j]['tagID'].values
job_tag_total=len(job_tag) # job의 해당 키워드가 총 몇개인지
cnt=0
for i in user_tag:
# user의 관심 키워드가 job의 키워드와 일치한다면 cnt를 1증가시켜 줍니다.
if i in job_tag: cnt+=1
# job의 전체 키워드중 몇개가 user의 관심사 키워드와 일치했는지 비율을 계산해줍니다.
tag.append(cnt/job_tag_total)
return tag
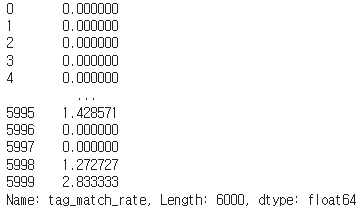
train['tag_match_rate']=tag_match(train)
test['tag_match_rate']=tag_match(test)train['tag_match_rate']를 출력해보면 아래와 같이 생성되었습니다.
- jobID와 userID 라벨 인코딩 하기
from sklearn.preprocessing import LabelEncoder
import numpy as np
le = LabelEncoder()
train['jobID'] = le.fit_transform(train['jobID'].values.reshape(-1, 1))
# test데이터에 unseen label을 처리해주기 위해 추가해주었습니다.
for label in np.unique(test['jobID']):
if label not in le.classes_: le.classes_=np.append(le.classes_,label)
test['jobID']=le.transform(test['jobID'].values.reshape(-1, 1))
train
le2 = LabelEncoder()
train['userID'] = le2.fit_transform(train['userID'].values.reshape(-1, 1))
test['userID']=le2.transform(test['userID'].values.reshape(-1, 1))
▶ EDA
연속형 변수인 companySize와 위에서 구한 tag_match_rate의 분포를 시각적으로 알아보겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
sns.kdeplot(train['companySize'])
sns.kdeplot(train['tag_match_rate'])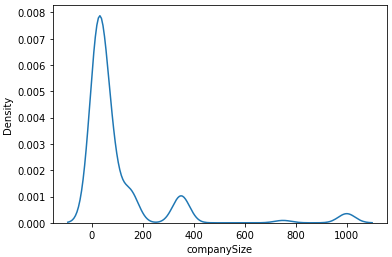
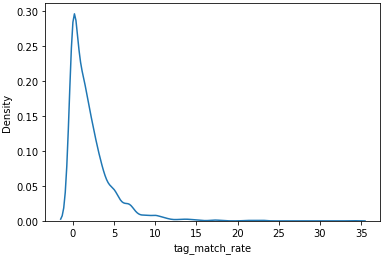
두 값 모두 왼쪽으로 치우쳐진 분포를 갖고 있음을 확인했습니다. 이를 어느정도 보완해주기 위해 log변환을 해보겠습니다.
f, ax = plt.subplots(1, 2, figsize=(12,3))
train['companySize']=train.companySize.apply(lambda x: np.log(x, where =(x!=0)))
train['tag_match_rate']=train.tag_match_rate.apply(lambda x: np.log(x) if x!=0 else x)
test['companySize']=test.companySize.apply(lambda x: np.log(x, where =(x!=0)))
test['tag_match_rate']=test.tag_match_rate.apply(lambda x: np.log(x) if x!=0 else x)
sns.kdeplot(train['companySize'], ax=ax[0])
sns.kdeplot(train['tag_match_rate'], ax=ax[1])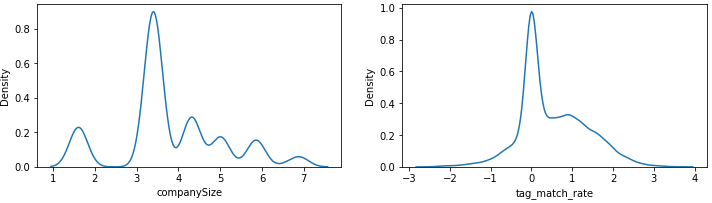
log 변환 후 데이터를 describe()함수를 이용해 확인해주겠습니다.
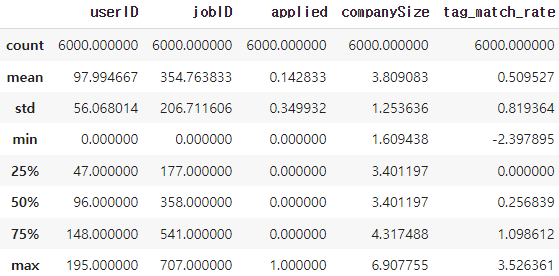
▶ preprocessing
companySize와 tag_match_rate에 대해 scaling을 해보겠습니다. 평균은 0, 표준 편차는 1이 되는 정규 분포의 성질을 갖는 Standard scaler를 이용합니다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
st_scaler1 = StandardScaler()
train['companySize']=st_scaler1.fit_transform(train['companySize'].values.reshape(-1,1))
test['companySize']=st_scaler1.transform(test['companySize'].values.reshape(-1,1))
st_scaler2 = StandardScaler()
train['tag_match_rate']=st_scaler2.fit_transform(train['tag_match_rate'].values.reshape(-1,1))
test['tag_match_rate']=st_scaler2.transform(test['tag_match_rate'].values.reshape(-1,1))
train.describe()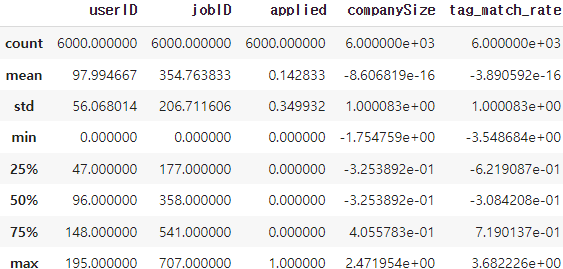
▶ Train and Predict
- 먼저 train데이터로 부터 정답 label을 분리해줍니다.
y=train['applied']
x = train.drop('applied', axis=1)- StratifiedKFold를 이용해 학습데이터와 검증데이터를 나눠주고, random forest를 이용해 학습시켰습니다.
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
n_splits = 10
skf = StratifiedKFold(n_splits=n_splits, shuffle=True)
val_scores = list()
# 모델 정의
clf = RandomForestClassifier()
for i, (trn_idx, val_idx) in enumerate(skf.split(x, y)):
x_train, y_train = x.iloc[trn_idx, :], y[trn_idx]
x_valid, y_valid = x.iloc[val_idx, :], y[val_idx]
# 모델 학습
clf.fit(x_train, y_train)
# 훈련, 검증 데이터 accuracy 확인
val_accuracy = accuracy_score(y_valid, clf.predict(x_valid))
print('{} Fold, train accuracy : {:.4f}4, validation accuracy : {:.4f}\n'.format(i, trn_accuracy , val_accuracy ))
val_scores.append(val_accuracy)총 10 개의 fold로 나눠주었습니다. 각 validation set에 대한 accuracy는 아래와 같습니다.

평균 accuracy 85%를 달성하였습니다. 학습 결과 feature 중요도를 출력해보겠습니다.
pd.Series(clf.feature_importances_, x.columns).sort_values().plot.barh()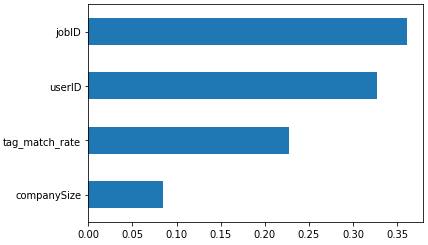
jobID와 userID가 높은 중요도를 갖고 companySize는 생각보다 적은 중요도를 갖습니다.
다음은 XGBoost로 학습한 결과입니다. 평균 accuracy 85.98%를 달성하였습니다. 마찬가지로 feature의 중요도를 출력해보겠습니다.
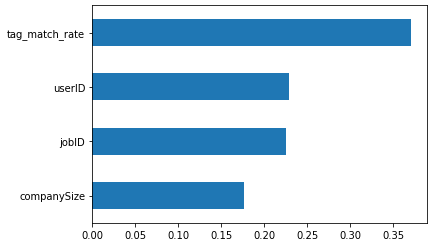
random forest에 비해 userID의 중요도가 감소했고 companySize의 중요도가 증가하였습니다.
▶Submission
성능이 조금 더 괜찮았던 XGBoost 모델로 test 파일에 대해 예측을 하고 제출 파일을 생성합니다.
final_predict=clf.predict(test)
submission = pd.DataFrame(final_predict, columns=['applied'])
submission
submission.to_csv('./rf_submission.csv', index=False)
최종 성능은 accuracy 82.34%입니다.
전체 코드는 저의 github 에서 확인할 수 있습니다!
신경망을 이용하는 방법도 따로 포스팅해보겠습니다!
아래 사이트의 코드를 변형하여 작성하였습니다!
'My Study > Project' 카테고리의 다른 글
| Apple Machine Learning Research 사이트 (0) | 2023.09.19 |
|---|---|
| 개인 프로젝트 - 채용 공고 추천(프로그래머스-신경망 ver) (0) | 2023.03.09 |
| 광고 전환 확률 예측 모델 구현(CVR Prediction) (0) | 2023.03.09 |