728x90
반응형
논문 링크: https://arxiv.org/pdf/2105.08194v2.pdf
github: https://github.com/herobd/FUDGE
GitHub - herobd/FUDGE: Code for the ICDAR2021 paper "Visual FUDGE: Form Understanding via Dynamic Graph Editing"
Code for the ICDAR2021 paper "Visual FUDGE: Form Understanding via Dynamic Graph Editing" - GitHub - herobd/FUDGE: Code for the ICDAR2021 paper "Visual FUDGE: Form Understanding via...
github.com
Introduction
- 이전 연구에서는 대규모 pre-train 언어 모델에 의존했다.
- OCR 결과가 좋지 않거나 데이터가 적으면 잘 탐지가 되지 않는 문제가 발생한다.
- 따라서, 본 논문에서는!
- 언어 정보를 필요로 하지 않는 순수한 visual 솔루션을 제시하고,
- Reasoning 동안 그래프 구조가 변화하는 GCN을 이용하여 text간의 관계를 탐지한다. 그래프 구조를 사용함으로써 제한된 수용영역에 의존할 필요가 없어 여러 줄에 걸쳐있는 text entity 또한 가능하게 한다.
Architecture
Visual FUDGE
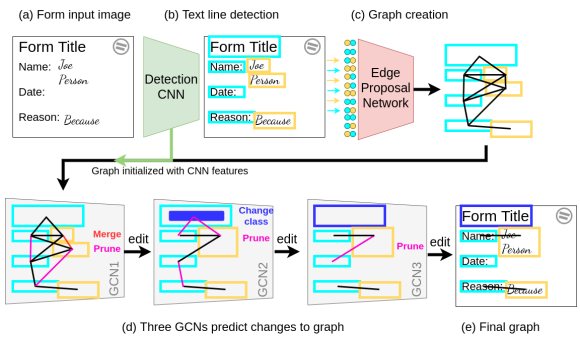
- Text line Detection
- YOLO detector를 사용한다.
- Edge Proposal
- 가능한 쌍들의 feature를 받고, edge로 연결될 가능성이 있는지 예측한다. 이때, 과분할된 text, 같은 entity의 일부인 text, 관계가 있는 text가 연결된다.
- 사용되는 feature는 두 bbox의 x와 y좌표의 차이, 중심좌표, 높이, 너비, 정규화된 좌표이다.
- Feature Extraction
- spatial feature와 visual feature를 이용한다.
- 초기 그래프의 Node feature: detection confidence, normalized height, normalized width, and class prediction, CNN feature.
- 초기 그래프의 Edge feature: normalized height of both entities, normalized width of both boxes, the class predictions of each entity, and distance between the corner points of the two entities, CNN feature.
- Iterated graph editing with GCN
- Reasoning 동안 그래프 구조가 변화하는 GCN을 이용한다.
- GCN의 각 노드는 text entity의 클래스를 예측한다.
- GCN의 각 엣지는 아래 4가지를 예측한다.
- edge를 가지치기 할지,
- entity를 하나로 합칠지,
- oversegment된 행이고 하나로 합칠지,
- true relationship 인지,
Dataset
- FUNSD dataset
- NAF dataset

결과 이미지
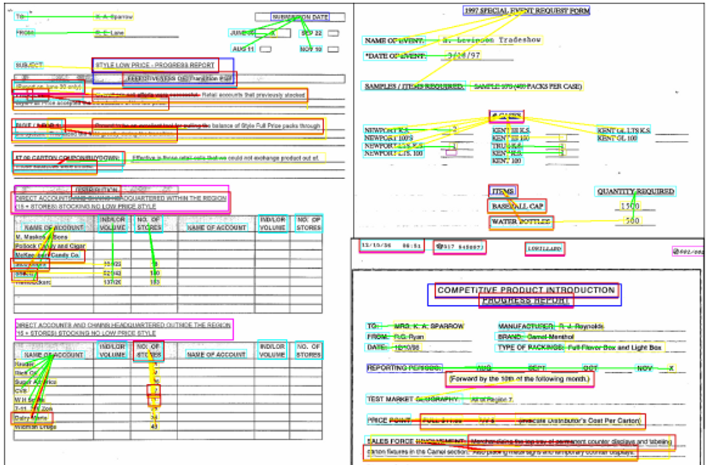
Conclusion
- Visual feature 사용에 의존하고, 복잡한 문서에 적용가능하지만,
- GCN 그래프 생성 전에 key와 value가 분류되어 있어야 하는 단점이 존재한다.
- 사용해보고자 하는 dataset에는 key, value가 아직 구분되어 있지 않아 논문에서 제안하는 GCN 모델을 사용하기 힘들다.
728x90
반응형