[ Paper ] https://arxiv.org/pdf/2305.12972.pdf
[ Github ] https://github.com/huawei-noah/VanillaNet
GitHub - huawei-noah/VanillaNet
Contribute to huawei-noah/VanillaNet development by creating an account on GitHub.
github.com
1. Introduction
최근 몇 년간 인공 신경망은 신경망의 complexity가 증가하면 성능이 향상된다는 생각을 바탕으로 layer를 깊게 쌓는 방향으로 발전해 왔습니다. 12개의 layer로 구성되어 있는 AlexNet을 시작으로 shortcut connection 을 이용하여 더 깊이 layer를 쌓은 ResNet도 등장하였습니다. 이렇게 신경망의 complexity가 증가함에 따라 신경망이 추출하는 feature들이 정확해져 표현력이 향상되었고 높은 성능을 달성할 수 있었습니다. 이 외에도 성능 향상을 위해 NLP분야의 transformer architecture를 vision task에 적용한 ViT가 등장하기도 했습니다.
복잡하고 깊은 신경망은 다양한 분야에서 높은 성능을 달성할 수 있도록 해주었지만, 휴대폰과 같은 하드웨어에는 배포가 어렵다는 한계점이 존재합니다. 신경망을 깊게 쌓으려면 ResNet의 shortcut과 같은 모듈이 필수적인데(shortcut이 없다면 기울기 소멸 문제로 인해 34 layer가 18 layer보다 성능이 낮습니다. ) shortcut connection 의 경우에는 'off-chip memory traffic'을 많이 소비합니다.
이러한 문제점을 해결하고자 본 논문에서는 고성능의 간결한 새로운 신경망인 VanillaNet을 제안합니다. 본 논문에서 제안하는 VanillaNet의 이점은 다음과 같습니다 : )
- 깊지 않은 layer, shortcut, self-attention 과 같은 구조를 피하면서 높은 성능을 달성하고 제한된 환경에서도 학습이 가능
- 간단한 구조를 이용해 생길 수 있는 challenge를 포괄적으로 분석
- "deep training" 제안 : inference 속도 유지, non-linear(비선형) layer 제거, series-based function 사용
2. A Vanilla Neural Architecture
VanillaNet 역시 기존 deep CNN의 보편적인 구조를 따릅니다. 대부분의 신경망들은 이미지를 입력으로 받아, feature map의 채널수는 늘리고 width와 height는 감소시켜가며 feature를 추출하고, 마지막의 fully connected layer로 분류합니다. 이를 다시 정리해 보면 아래와 같습니다.
▶ stem block : 입력 이미지의 RGB 3채널을 여러 채널로 변환
▶ main body : 유용한 정보를 학습, feature map의 채널수는 늘리고 width와 height는 감소시켜가며 feature를 추출하는 부분 => 4개의 stage로 구성
▶ fully connected layer : 최종 분류 결과를 출력
이러한 구조를 바탕으로 하는 ResNet32, ResNet50, ViT 62 layer등의 신경망이 많이 사용되고 있습니다. 딥러닝의 빠른 연산을 위해 GPU의 성능도 많이 좋아졌지만 이 신경망들을 real-time용으로 사용하기에는 여전히 speed면에서 한계가 있습니다.
그래서 VanillaNet은 이러한 문제를 해결하기 위해 main body의 각 stage를 하나의 layer로만 구성했습니다. 아래 그림은 6 layer의 VanillaNet의 구조도 입니다.
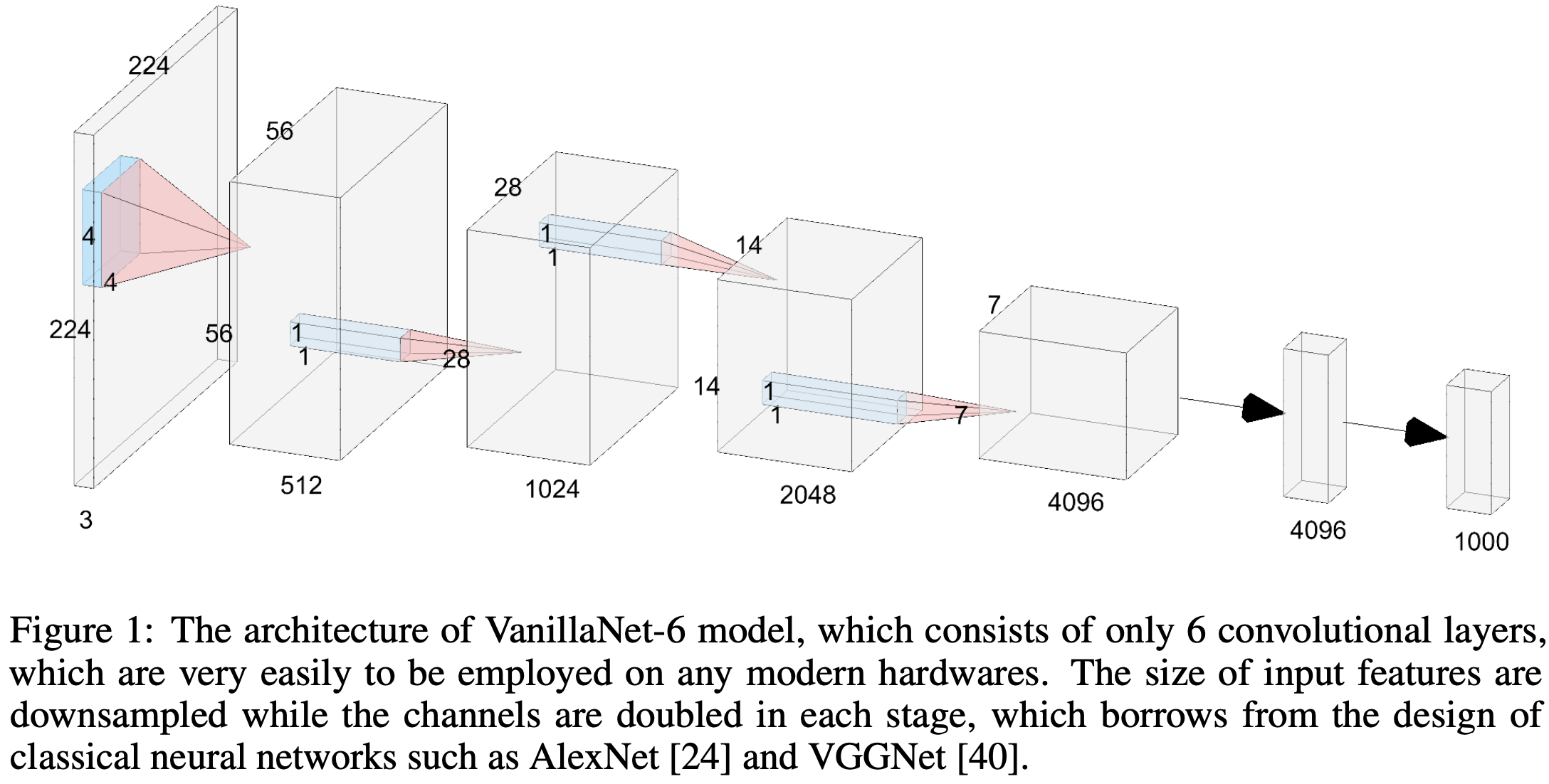
VanillaNet의 stem block, main body는 다음과 같이 구성되어 있습니다 : )
▶ stem block
stride 4 만큼의 크기를 가지고 4 * 4 * 3 * C의 layer로 RGB 3채널을 깊이 C로 확장합니다.
▶ main body
stage 1, 2, 3 : stride는 2만큼의 크기를 가지고, max pooling으로 feature map의 사이즈를 감소시킵니다. 채널수는 2배씩 증가합니다.
stage 4 : 채널수는 유지하고 average pooling으로 사이즈를 감소시킵니다.
▶ fully connected layer
분류 결과를 출력합니다. calculation cost를 최소로 하면서 feature map 의 정보를 유지하기 위해 kernel size는 1로 설정합니다. 또한 batch normalization도 각 layer뒤에 추가됩니다.
서론에서도 설명 했듯이 VanillaNet에는 shortcut 모듈이 존재하지 않습니다. 물론 단순히 이렇게만 네트워크를 구성하게 되면 신경망의 non-linearlity(비선형성)가 약해지기 때문에 성능이 제한 될 수 있습니다. 이러한 문제를 해결하기 위해 본 논문의 3장에서는 여러 기술을 제안합니다.
3. Training of Vanilla Networks
3.1 Deep Training Strategy
Deep Training Strategy의 핵심은 아래 3가지로 기술할 수 있습니다.
- 학습 시작 시에 single convolution layer 대신 2개의 convolution layer와 activation function을 적용하여 학습합니다.
- 이때, activation function 은 epoch이 증가함에 따라 identity mapping으로 점점 감소하게 됩니다.
- 학습이 끝나면 두 개의 convolution layer를 하나의 convolution layer로 merge하여 inference time을 감소시킬 수 있습니다.
위 3가지 모두 보편적인 CNN에서 많이 사용된다고 합니다!
본 논문에서 제안하는 activation function 은 아래 수식으로 정의 할 수 있습니다.
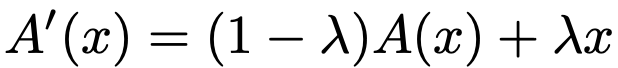
A(x)는 ReLU나 Tanh같은 activation function을 나타냅니다. 본 논문에서는 이 함수를 identity mapping으로 결합합니다. λ는 수정된 함수의 non-linearlity 밸런스를 맞추기 위한 파라미터입니다. e는 현재의 epoch을 E는 전체 epoch을 나타내는 기호로 설정해주고 λ를 e/E로 설정하여 주면 λ가 0이 됐을 때(학습 초반부) 가장 강한 non-linearity를 가지고, 학습 후반부에 수렴이 되면 activation function 이 없으므로 로 수렴하게 됩니다. 즉, convolution layer 중간에 activation function이 없는 것이죠.
이제 두 개의 convolution layer를 어떻게 하나로 합치는지 알아보겠습니다.
먼저 batch normalization 과 그 앞의 layer를 하나의 convolution layer로 합칩니다.
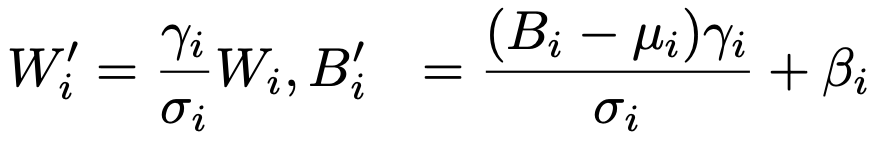
W, B : convolution kernel의 weight와 bias
: batch normalization의 scale, shift, mean, variance
i : i 번째 output channel
다음 두 개의 1*1 convolution 을 합쳐줍니다. 이 부분의 수식은 아래와 같습니다.
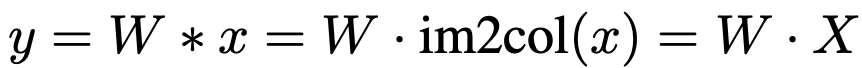
* : convolution 연산
X , Y : input, output feature
img2col : 다차원의 데이터를 행렬로 변환
최종적으로 다음과 같은 수식으로 정의 할 수 있습니다.
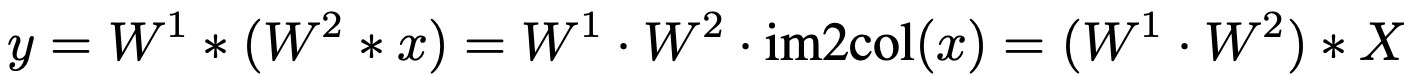
W1, W2 : 두 convolution의 weight
3.2 Series Informed Activation Function
ReLU, PReLu, Swish등등 많은 activation function 들이 등장했지만 대부분은 깊고 복잡한 네트워크의 성능을 높이는데 중점을 둔 함수들입니다.
앞서 설명했듯이 얕고 단순한 네트워크들은 non-linearity가 좋지 않습니다. 이를 개선하는데는 non-linear activation layers를 추가적으로 더 쌓거나 각 activation layer의 non-linearity를 높이는 방법 두 가지가 있습니다. 기존의 많은 deep CNN들은 전자의 방법을 선택했지만 VanillaNet은 후자의 방법을 선택합니다.
그래서, 제안하는 가장 간단한 방법은 activation function을 stacking 하는 것 입니다. 연속적으로 stacking 하는 것이 기존 CNN의 특징이었다면 본 논문에서는 concurrent(동시에)하게 stacking합니다. 이를 수식으로 나타내면 아래와 같습니다.
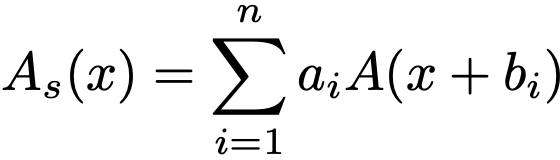
A(x) : activation function
n : stack 된 activation function의 갯수
a , b : 단순한 축적을 피하기 위한 scale과 bias
이러한 방식을 사용하면 activation function의 non-linearity를 상당히 증가시킬 수 있다고 합니다.
또한, approximation ability를 풍부하게 하기 위해 series based function이 입력을 이웃들로 부터 다양하게 하여 global한 정보도 배울 수 있게 했습니다. 이는 BNET과 유사하다고 하네요. 이 부분의 수식은 아래와 같습니다. h, w, c는 input feature의 높이, 너비, 채널 수 입니다.
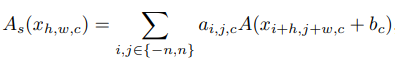
수식에서 알 수 있듯이, n=0이라면 A(x) 가 일반적인 activation function과 동일합니다. 이 내용들의 연산량은 다음과 같습니다.
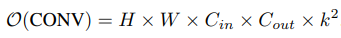
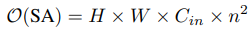
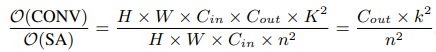
4. Experiments
먼저 activation function 개수에 따른 성능 결과입니다.
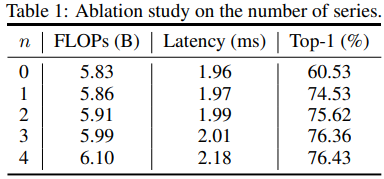
activation function을 stacking 할 수록 성능이 좋아지는 것을 확인할 수 있습니다.
다음은 backbone 별로 deep training과 series activation function을 적용한 결과입니다.
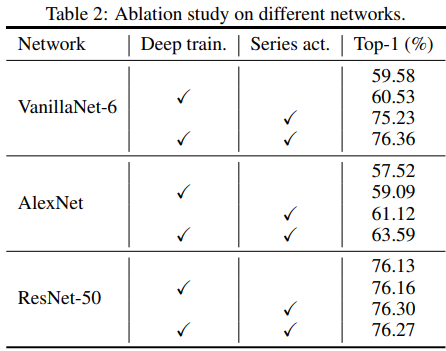
역시 두 가지 모두를 적용했을 때 가장 높은 성능을 달성했습니다.
다음은 VanillaNet에 shortcut 적용여부에 따른 성능입니다.
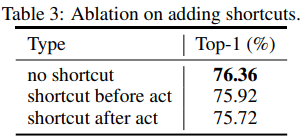
shortcut을 적용하지 않았을 때 가장 성능이 높네요. VanillaNet의 bottleneck은 다른 CNN들과 다르게 identity mapping이 아니기 때문에 , shortcut을 추가하는 것이 성능향상에 도움이 되지 않는다고 설명하고 있습니다. shortcut을 추가하더라도 activatioin function단계에서 건너뛴다면 non-linearity가 감소되어 결국 얕은 신경망의 단점을 고스란히 갖게 되기 때문입니다.
다음은 ResNet과 activation map 시각화 결과 비교입니다.

VanillaNet에서 activation이 잘 되는 것을 확인 할 수 있습니다.
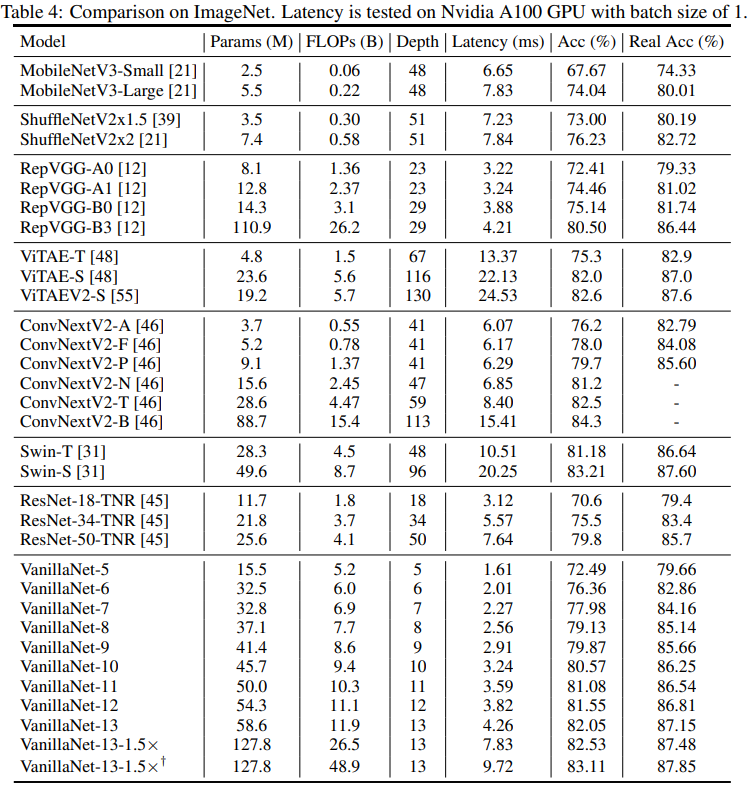
마지막으로 다른 모델들과 비교한 결과입니다.