728x90
반응형
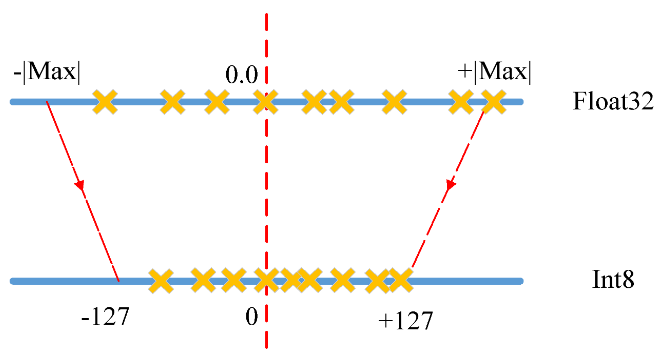
- Quantization (양자화) 란?
딥러닝 모델의 파라미터를 낮은 bit(Float32 => Int8)로 변환하여 계산 시간과 메모리 접근 속도를 높이는 경량화 기법입니다. 보통 부동소수점 연산인 Float32를 정수인 Int8 로 변환하는 방식이 많이 사용됩니다.
- ONNX로 모델 양자화 하기
onnxruntime.quantization에서 제공하는 quantize_dynamic 함수를 이용하면 됩니다.
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'model.onnx'
model_quant = 'model_quant.onnx'
quantize_dynamic(model_fp32, model_quant, weight_type=QuantType.QUInt8)양자화 후의 모습입니다.
아래 명령어를 통해 변환 전,후의 onnx 파일의 용량을 확인해보면
ls -alh아래 사진에서 확인할 수 있듯이 양자화 후 onnx 파일의 용량이 감소한 것을 알 수 있습니다 : )

728x90
반응형
'ONNX' 카테고리의 다른 글
| [ONNX] ONNX Model Visualization(Netron) (0) | 2023.04.04 |
|---|---|
| [ONNX] ONNX 변환모델에 메타데이터 추가하기 (0) | 2023.04.01 |
| [ONNX] ONNX Runtime에서 실행하기 (0) | 2023.03.31 |
| [ONNX] Pytorch 모델을 ONNX 모델로 변환하기 (0) | 2023.03.30 |