[Github] https://github.com/IBM/CrossViT
GitHub - IBM/CrossViT: Official implementation of CrossViT. https://arxiv.org/abs/2103.14899
Official implementation of CrossViT. https://arxiv.org/abs/2103.14899 - GitHub - IBM/CrossViT: Official implementation of CrossViT. https://arxiv.org/abs/2103.14899
github.com
Abstract
최근 image classification 분야에서 CNN 보다 ViT가 더 나은 결과를 보이고 있습니다. 따라서 본 논문에서는 transformer모델이 multi-scale feature를 학습하는 방법을 제안합니다. 다양한 크기의 이미지 patch를 결합하는 dual-branch transformer를 제안하고 이때, 각각의 patch들이 가진 정보를 보완하기 위해 cross-attention을 사용합니다. 이러한 방법은 computational cost와 memory complexity를 선형정도로만 증가시키면서 높은 성능을 기록했다고 합니다.
1. Introduction
NLP분야에서 transformer가 큰 성공을 거두면서 vision 분야에서도 transformer가 CNN의 강력한 경쟁자로 떠올랐습니다. 이전의 대부분의 연구들은 self-attention과 CNN을 결합하는데 초점을 두었는데 이러한 방식은 계산에 scalability가 제한적입니다. 여러 연구 끝에 ViT(Vision Transformer)가 등장했는데 학습에 매우 큰 데이터 셋을 필요로 한다는 단점이 존재했습니다. 이 후에도 vision분야에 transformer를 적용하기 위한 노력이 연구가 계속되었습니다.
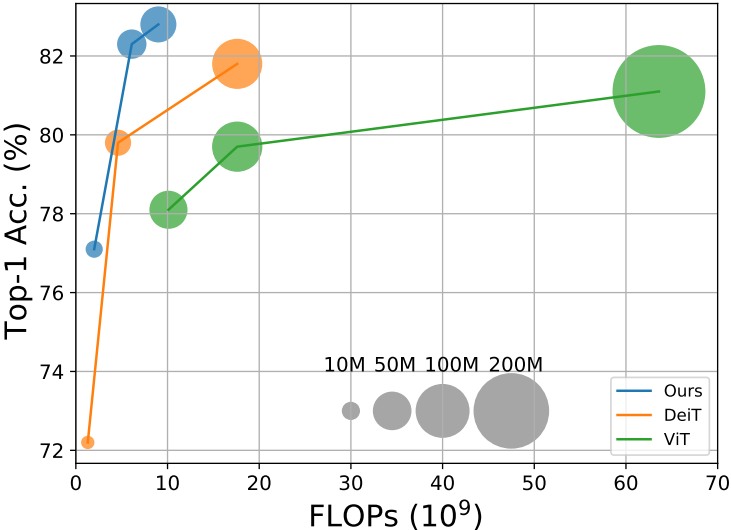
따라서, 본 논문에서는 "이미지 분류 작업을 위한 multi-scale feature representations" 방법을 tansformer에 적용하는 방식을 제안합니다. 이미지를 크고 작은 patch들로 나누고 두 개의 branch를 통해 더 강력한 visual feature들을 생성합니다. 이 두 branch는 서로 다른 computational complexities 를 가지고 서로를 상호 보완하며 fuse 됩니다. fuse하는 방법으로는 cross attention을 사용합니다. 이를 통해 quadratic time이 아닌 linear-time정도의 시간 증가만 가져오게 됩니다. 아래는 DeiT와 ViT, 본 논문에서 제안하는 CrossViT 의 정확도와 FLOPs를 비교한 그림입니다.
2. Method
제안하는 CrossViT모델은 기본적으로 ViT의 구조를 따릅니다.
2.1 Overview of Vision Transformer
Vision Transformer에 대한 설명은 아래 글을 참고해 주세요!
https://ga02-ailab.tistory.com/147
2.2 Proposed Multi-Scale Vision Transformer
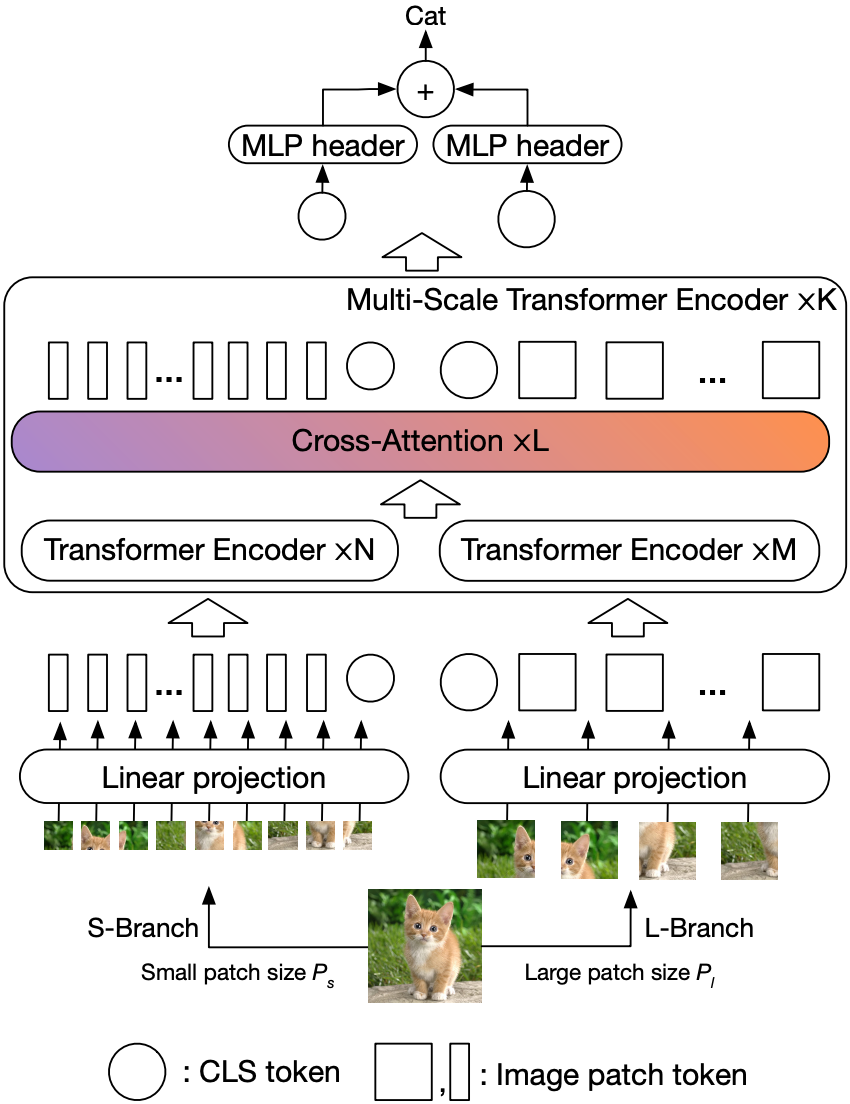
이미지 patch의 크기는 정확도와 복잡도에 영향을 미칩니다. ViT의 경우에 보면 patch 크기가 16일때와 32일 때 , 16일때 정확도가 6% 더 높았지만 FLOPs는 4배더 많았다고 합니다. 본 논문에서는 정확도 향상과 FLOPs사이에 균형을 맞추면서 작은 patch크기를 유지 하기 위한 방법을 제시합니다. 그 중 첫번째가 dual-branch이고, 두번째가 두 branch 사이의 정보를 효과적으로 fuse하는 방법에 대한 것입니다.
위 구조도를 살펴보겠습니다. 제안하는 crossViT는 K 개의 K multiscale transformer encoder로 구성되어 있고 각각의 encoder는 2개의 branch로 L-Branch와 S-Branch로 구성되어 있습니다.
L-Branch: coarse-grained patch size를 이용합니다. 더 많은 encoder와 더 큰 embedding dimesion을 갖습니다.
S-Branch: fine-grained patch size를 이용합니다. 적은 encoder 와 작은 embedding dimension을 갖습니다.
이 두 branch는 L번 fuse하게 되고 , 마지막에 CLS 토큰을 예측에 사용합니다. 또한, 각 branch의 token에 learnable position embedding 을 추가해 위치 정보를 학습할 수 있게 합니다.
2.3 Multi-Scale Feature Fusion
이제, 효율적인 feature fusion 방법에 대해 알아보겠습니다. 이는, multiscale feature representations에 중요한 키 역할을 하는데요. 본 논문에서는 아래 그림처럼 4가지 방식을 소개합니다. a-c는 heuristic 접근 법이고, d가 본 논문에서 제안하는 방식입니다.

앞으로 나올 수식들에 등장하는 x^i는 branch의 시퀀스 데이터를 의미합니다.
2.3.1 All-Attention Fusion
그림(a)의 방식입니다. 가장 기본적인 방법으로 각 token의 성질은 고려하지 않고 모든 token들을 연결하고 self-attention 모듈을 통해 fuse하는 방법입니다. 간단하지만 계산 비용이 많이 든다는 문제점이 있습니다.
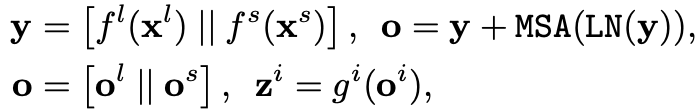
f( ), g( )는 projection과 back-projection을 나타내고, z는 최종 output을 의미합니다. 위 식을 해석해보자면 이렇습니다. L-Branch와 S-Branch로 각각 output을 구해 y를 얻고 이를 self-attention 모듈에 넣어 o를 얻어냅니다.
2.3.2 Class Token Fusion
그림(b)의 방식입니다. CLS token은 추상적인 global feature representation로 여겨집니다. 그 이유는 최종 예측 단계에서만 사용되기 때문입니다. 그러므로 두 branch의 CLS token을 합산하여 fuse할 수도 있습니다. 이 방식은 하나의 tiken만 처리하면 되므로 매우 효율적입니다. CLS token이 fuse되면 이 정보는 transformer encoder의 patch token 입력이 됩니다.
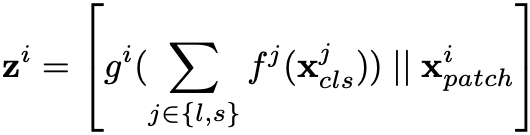
2.3.3 Pairwise Fusion
그림(c)의 방식입니다. patch token들은 이미지 공간상에 위치해 있기 때문에 각 patch의 spatial location을 기반으로 결합 할 수도 있습니다. 그런데 두 branch가 서로 다른 patch 사이즈를 가지기 때문에 patch의 수도 다를 수 밖에 없습니다. 따라서 먼저, interpolation을 통해 spatial size를 동일하게 해주고 fuse해줍니다.
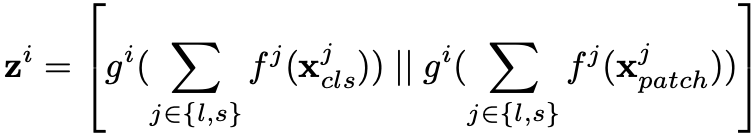
2.3.4 Cross-Attention Fusion
그림(d)의 방식입니다. 본 논문에서 제안하고 있는 방식이죠! 이 방식의 fusion은 다른 branch의 CLS token을 서로의 branch와 공유합니다. 구체적으로, multi-scale feature를 좀 더 효과적으로 fusion하기 위해 각 branch의 CLS token을 agent로서 이미지 patch와 정보를 교환한 다음 projection합니다. 이웃 branch로 가 그곳의 이미지 patch들의 정보를 학습한 후 자신의 branch로 돌아오는 것이죠. CLS token을 교환함으로써 branch들 사이의 patch token들의 정보를 교환하는 효과를 기대 할 수 있습니다. 아래 그림은 cross-attention module의 구조도입니다.
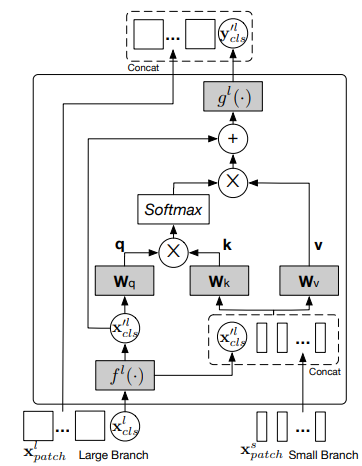
l-branch의 경우 s-branch로 부터 patch정보를 모으로 CLS token 을 연결합니다. 이를 식으로 표현하면 아래와 같습니다.
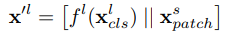
f는 projection 함수를 의미하고 x^'l은 small과 large의 CLS token을 projection하고 concat한 것을 의미합니다. 그 후 CLS token을 query로 하여 x^'l와 x^l_cls로 cross attention 연산을 진행합니다. 이는 수식으로 아래와 같이 나타냅니다.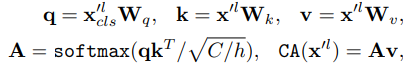
위 식의 W 들은 학습 가능한 파라미터들입니다. C는 embedding dimension, h는 num of heads입니다.
그 이후의 과정은 self-attention과 유사하게 multi-head와 LayerNorm을 사용합니다.
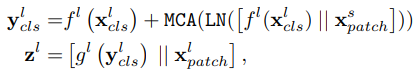
이 때, f 와 g는 각각 projection, back-projection 함수입니다.
3. Experiments
3.1 Comparisons with DeiT
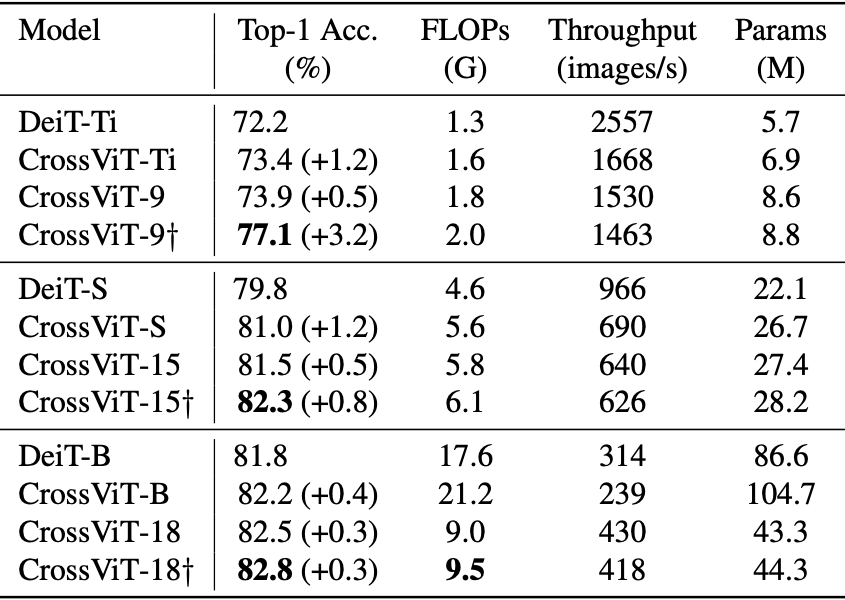
먼저 DeiT와 비교입니다. CrossViT가 더 높은 성능을 보이고 있습니다.
3.2 Comparisons with SOTA Transformers
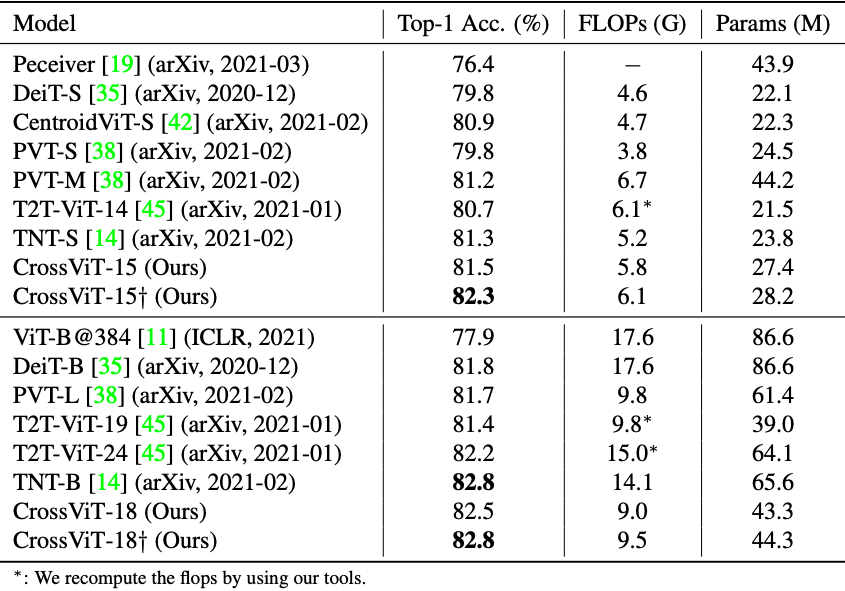
다른 transformer 모델들과의 비교에서도 CrossViT가 가장 높은 성능을 보이고 있습니다.
3.3 Comparisons with CNN-based Models
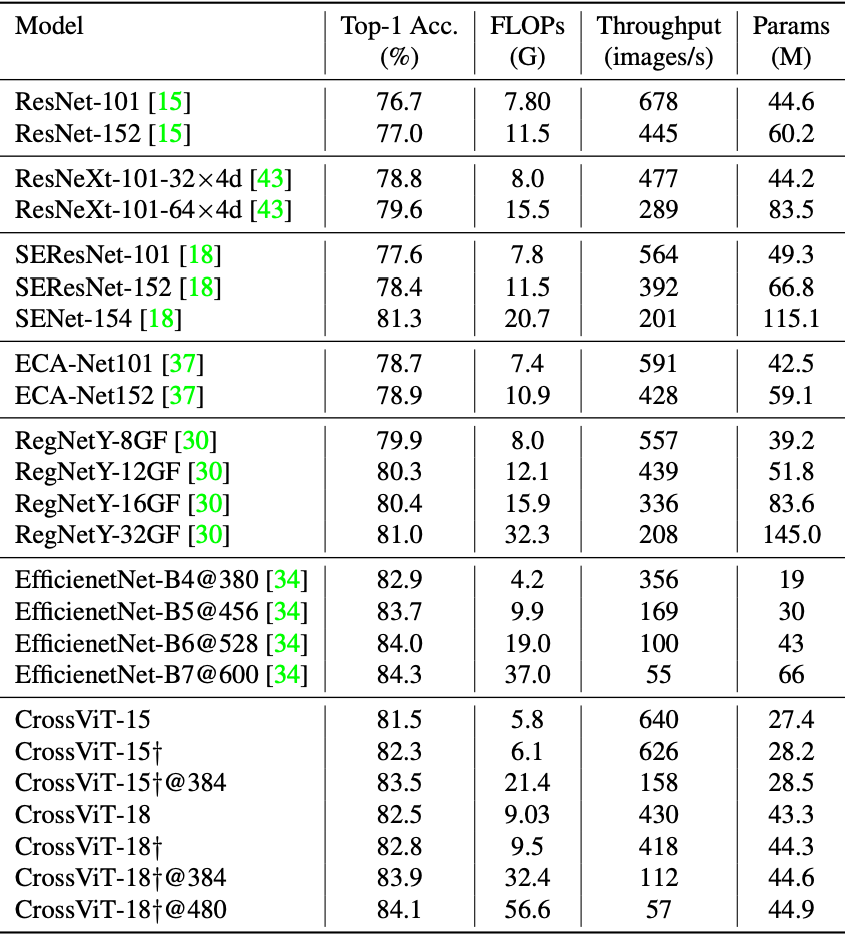
이번엔 CNN 모델들과의 비교입니다. CrossViT 또한 CNN과 거의 비슷한 성능을 내고 있습니다.
3.4 Ablation Study
3.4.1 Comparison of Different Fusion Schemes
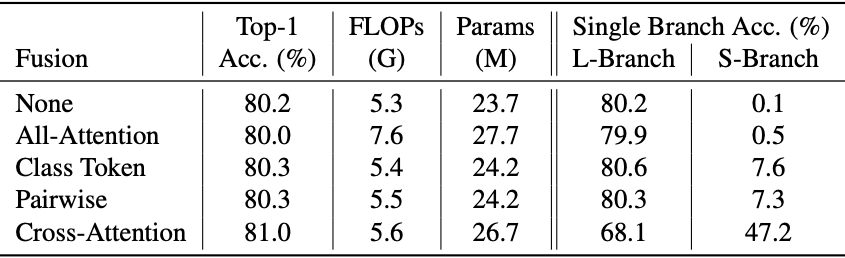
다양한 fusion 방식들에 대한 성능입니다. cross-attention 방법이 가장 높은 성능을 내고 있습니다.
'Paper Review > etc' 카테고리의 다른 글
| [9] Supervised Contrastive Learning (1) | 2023.11.23 |
|---|---|
| [8] MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER (2) | 2023.10.15 |
| [7] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2023.09.12 |
| [6] MobileOne: An Improved One millisecond Mobile Backbone (0) | 2023.08.06 |
| [5] VanillaNet: the Power of Minimalism inDeep Learning (1) | 2023.06.25 |