[Paper] https://arxiv.org/pdf/2112.04482
[Github] https://github.com/facebookresearch/multimodal/tree/main/examples/flava
multimodal/examples/flava at main · facebookresearch/multimodal
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale. - facebookresearch/multimodal
github.com
1. Abstract
- 기존 연구의 문제점
- 기존의 vision과 VLM 모델들은 대규모 vision-language 모델 사전학습을 통해 성능을 향상시킴
- 특정 modality 혹은 task에 초점을 맞춘 모델들이 다수
- cross-modal(CLIP)과 multi-modal(Transformer) 중 하나만 활용
⇒ FLAVA는 이러한 한계를 넘어 하나의 총합적인 “foundation” 모델로서 vision task, language task, cross-modal task, multi-modal task 모두에서 우수한 성능을 달성하는 범용 vision-language 모델 을 구현
2. Introduction

- cross-modal과 multi-modal의 문제점
- cross-modal: 한 모달리티에서 다른 모달리티를 예측/검색 ⇒ Fusion Task에서 약함
- multi-modal: 여러 모달리티를 동시에 처리 ⇒ 단일 모달리티 성능이 낮아질 수 있음
- FLAVA: Foundational Language And Vision Alignment Model
- multimodal(이미지-텍스트 쌍) 와 unimodal(image/text only) 데이터를 결합하여 학습,
- 모든 모달리티에서 시각 및 언어의 강력한 표현을 학습하는 범용 모델이 됨
- masking 기반 학습을 적용하여 강력한 representation을 학습 가능
- 단순한 contrastive learning 기반이 아닌 다양한 형태의 데이터에서 representation을 학습하는게 가능해짐
- 35개 task에서 모델의 우수함 검증
- multimodal(이미지-텍스트 쌍) 와 unimodal(image/text only) 데이터를 결합하여 학습,
✅ Masking 기반의 학습 방법
- = reconstruction 기반
- 데이터 일부를 가려놓고 복원하도록 학습 ⇒ 표현력을 크게 향상시킬 수 있는 학습 방법
- 마스킹된 부분을 복원하면서 멀티모달 정보의 상관관계를 학습하는 방식
- 중간 표현 및 부분적인 재구성 관점에서 접근
3. Method
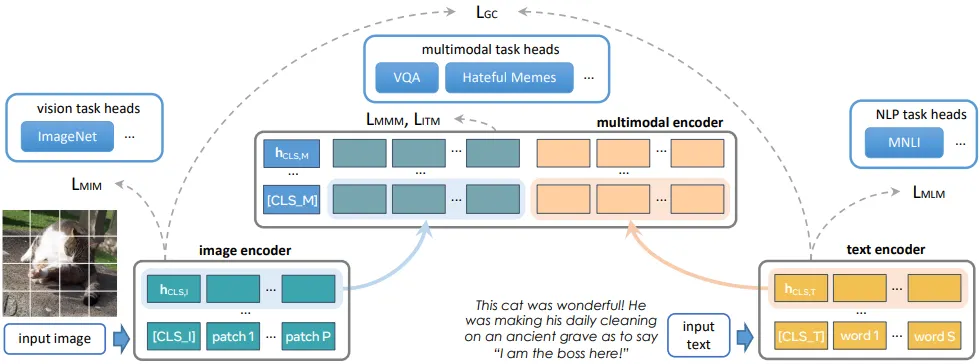
3.1. The model architecture
- Transformer 기반
- 3가지 부분으로 구성 됨
- Unimodal: image encoder, text encoder
- multi modal : multimodal encoder
- image encoder
- ViT 구조 (ViT-B/16)
- resizing → patching → positional embedding → hidden state vector h_I
- classification head 추가 (downstream task 수행을 위한 것) ⇒ [CLS_I]
- text encoder
- BERT 기반의 Transformer
- tokenization → token embedding → hidden state vector h_T
- classification head 추가 (downstream task 수행을 위한 것) ⇒ [CLS_T]
- multimodal encoder
- 각 image encoder와 text encoder를 통과하여 얻어진 hidden state vector(h_I, h_T)에 각각 linear projection 적용
- 각 unimodal encoder에서 나온 hidden representation을 결합하여 fusion representation 학습 및 masking 된 부분 복원
- 이후 이를 단일 리스트로 병합(concat)
- multimodal classification을 위한 special token을 추가 ⇒ [CLS_M]
- 각 image encoder와 text encoder를 통과하여 얻어진 hidden state vector(h_I, h_T)에 각각 linear projection 적용
💡FLAVA는 하나의 거대한 네트워크 안에서
- image only,
- text only,
- image-text pair 입력
위 3가지를 모두 하나의 모델로 처리하기 때문에, 각각의 경우에 맞는 objectives 들을 정의
3.2. Multimodal pre-training objectives
- Global contrastive (GC) loss
- CLIP 방식과 유사⇒ h_I와 h_T로 contrastive learning
- 각 h_CLS,I 및 h_CLS,T를 임베딩 공간에 linear projection 후 L2 정규화/내적 및 temperature에 따라 조정된 softmax loss 계산
- image-text pair의 관계(연관성) 학습
- Masked multimodal modeling (MMM)
- text input과 이미지 패치 모두 masking 적용
- 이미지: 이미지를 패치 단위로 나눈 후 임의의 패치를 선택하여 masking
- 텍스트: 텍스트 토큰 중 15%를 임의로 골라 [MASK] 토큰으로 대체, BERT 기반
- multimodal encoder의 output({h_M})을 multi-layer perceptron을 통해 처리하여 masking된 데이터를 복원
- 이미지: masking 된 이미지 패치의 visual codebook index 예측
- codebook?
- 이미지 패치를 이산적 벡터로 매핑하기 위한 “시각 어휘집(visual vocabulary)”
- 텍스트: masking 된 텍스트 토큰의 word vocabulary index 예측
- 이미지: masking 된 이미지 패치의 visual codebook index 예측
- 즉, 한 modality의 정보로 다른 modality의 가려진 부분을 예측할 수 있게 만듦.
- text input과 이미지 패치 모두 masking 적용
- Image-text matching (ITM)
- multimodal encoder의 [CLS_M] 벡터를 이용해 image와 text가 실제로 매칭되는지 판단
3.3. Unimodal pre-training objectives
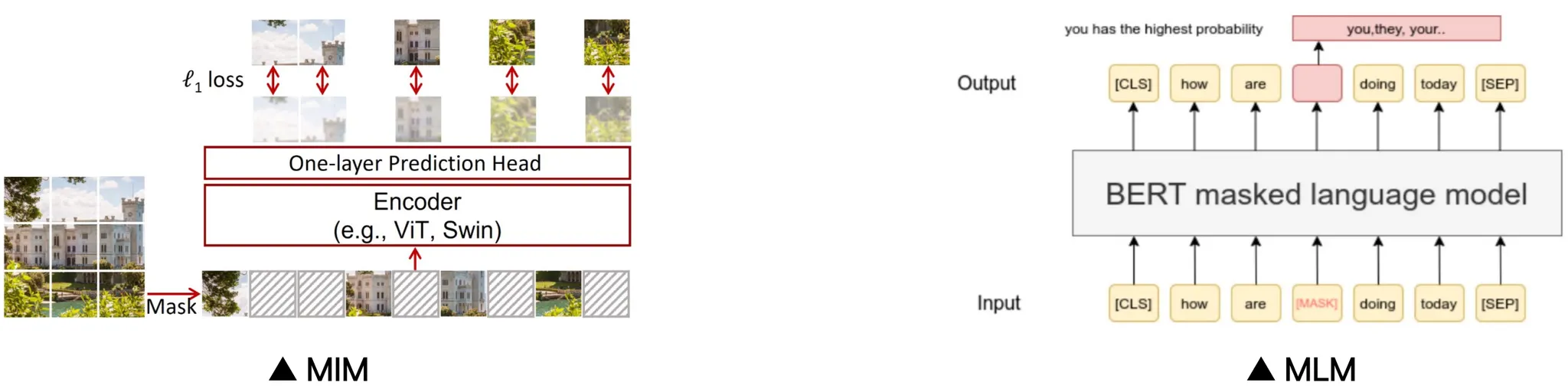
- Masked image modeling (MIM)
- 패치 일부를 마스킹하고, 모델이 마스킹된 부분의 픽셀 값을 예측하도록 학습하는 방법
- 이미지 자체의 구조와 패턴을 이해 할 수 있음 → 시각적 표현 능력 향상
- Masked language modeling (MLM)
- 일부 단어나 토큰 마스킹
- 언어의 문맥과 의미를 효과적으로 파악 → 언어적 표현 능력 향상

3.4. Implementation details
- batch size = 8192
- lr = 1e-3
- optimizer = AdamW
- 세부 학습 방법
- 이미지 단독(batch of images) → Masked Image Modeling (MIM)
- 텍스트 단독(batch of text) → Masked Language Modeling (MLM)
- 이미지–텍스트 쌍(batch of pairs) → Contrastive + Matching + Masked Multimodal (GC + ITM + MMM)
- 세 가지 데이터들을 라운드 로빈 방식으로 샘플링
- 한 iteration에서는 이미지 전용 데이터 (ImageNet batch) → MIM loss 계산
- 다음 iteration에서는 텍스트 전용 데이터 (BookCorpus batch) → MLM loss 계산
- 그 다음 iteration에서는 이미지-텍스트 쌍 데이터 (COCO, CC12M) → GC + ITM + MMM 계산
3.5. Data: Public Multimodal Datasets (PMD)


- 저자들이 직접 만든 Public Multimodal Datasets (PMD) 사용
- 약 7천만 쌍의 데이터
- 총 이미지 수 약 6,800만장, 평균 캡션 길이 12.1단어
- Visual Genome, Conceptual Captions등 공개 데이터셋만 사용하였기에 연구 재현성과 향후 확장에 용이함
4. Experiments
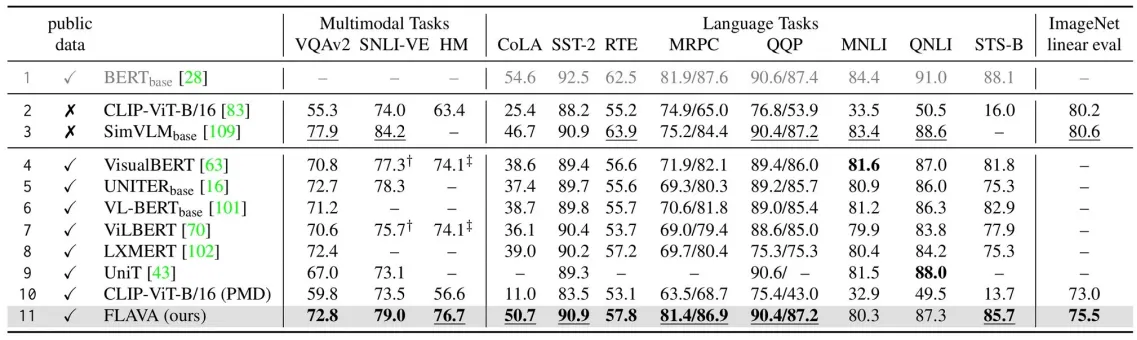
- Comparison to state-of-the-art models
- ablation study
- Full FLAVA model
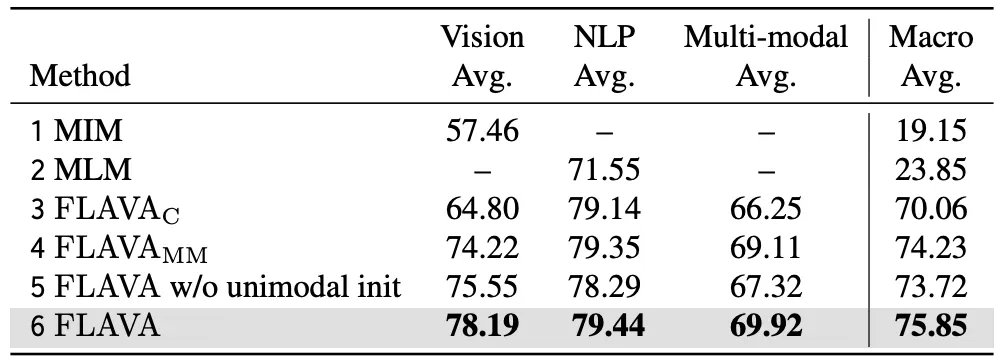
- 1, 2: unimodal-only
- image encoder 및 text encoder를 독립적으로 학습
- 3, 4: multimodal-only
- 3번) contrastive learning을 통해 두 모달리티 간 연관성 학습
- 4번) multimodal encoder를 통한 fusion representation 학습
- 5, 6: unimodal + multimodal
- 전체 FLAVA model 학습
5. Limitations
- 학습 효율은 높지만, 3개의 인코더가 있으므로 메모리 사용량이 큼.
- multimodal encoder의 cross attention을 사용하는 대신 단순 concat 방식을 사용해서 fine-grained 관계 학습이 부족할 수 있음.
→ 이후 연구들(BLIP, ALBEF2, Flamingo, Kosmos-2.5 등)이 이를 개선