728x90
반응형
[paper] https://arxiv.org/pdf/2602.06040
[Github] https://github.com/Accio-Lab/SwimBird
GitHub - Accio-Lab/SwimBird
Contribute to Accio-Lab/SwimBird development by creating an account on GitHub.
github.com
1. Introduction

- 기존 MLLM모델들의 추론패턴 문제점을 지적
- 항상 텍스트 CoT만 사용하거나 latent Visual Token만 사용하는 방식
- ⇒ 질문마다 필요한 사고방식이 다른데 왜 항상 같은 추론 패턴을 사용할까?
- 다양한 유형의 쿼리에 유연하게 대응하지 못하는 한계 직면
- 텍스트 중심의 논리적 문제에서 불필요한 시각적 연산을 초래하여 성능을 저하시키거나, 반대로 시각 정보를 주로 사용해야 하는 문제에서 텍스트만으로는 표현할 수 없는 정보의 손실을 야기
- 이를 해결하기 위해 SwimBird는..
- 질의에 따라 text-only / vision-only / vision-text interleave의 3가지 모드를 모델이 스스로 선택하도록 만들고, latent token 길이도 문제 난이도에 따라 동적으로 할당하도록 함
- text-only 추론: <reason>…</reason>로 표기되는 텍스트 CoT 중심
- vision-only 추론: <|latent_start|> … <|latent_end|> 구간에서 연속 잠재 토큰(임베딩) 을 생성하며, 텍스트 CoT를 최소화.
- vision-text interleave 추론: 필요할 때 latent token과 텍스트 추론을 번갈아 수행
- Hybrid Autoregressive를 사용하여 텍스트 토큰에 대한 예측과 visual token의 임베딩 예측을 단일 프레임워크 내에서 통합 → 위의 3가지 모드 선택 자체를 학습한다!
- 질의에 따라 text-only / vision-only / vision-text interleave의 3가지 모드를 모델이 스스로 선택하도록 만들고, latent token 길이도 문제 난이도에 따라 동적으로 할당하도록 함
2. Method
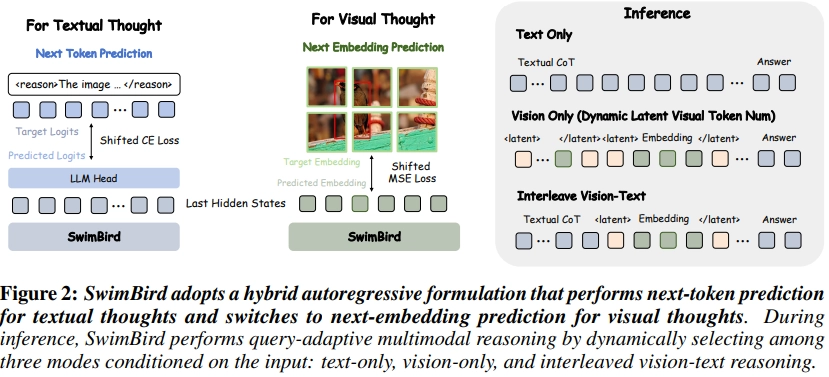
3.1 Hybrid Autoregressive Modeling
- Textual thought as next-token prediction
- shifted cross-entropy loss사용
- x: 이미지, w: 단어토큰
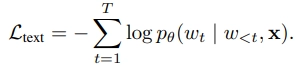
- x: 이미지, w: 단어토큰
- shifted cross-entropy loss사용
- Visual thought as next-embedding prediction
- MSE loss 사용
- z: visual latent tokens
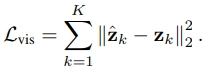
- z: visual latent tokens
- MSE loss 사용
- Unified training objective
- 최종 loss

- 최종 loss
- Mode switching with special delimiters
- output space 를 토큰과 임베딩 두 종류로 확장했기에 이를 구분하는 토큰 필요
- 학습시 <|latent_start|> … <|latent_end|> 로 visual thought 영역 표시
- 모델이 텍스트 토큰이 아닌 연속적인 latent embedding을 생성해야 함을 알려줌
- system prompt

- 학습시 <|latent_start|> … <|latent_end|> 로 visual thought 영역 표시
- output space 를 토큰과 임베딩 두 종류로 확장했기에 이를 구분하는 토큰 필요
- 추론 단계에서는 어떻게?
- 예를 들어, 모델이 <|latent_start|> 를 출력하면 그 다음부터는 임베딩 생성 단계로 전환 → <|latent_end|> 를 출력하면 텍스트토큰 생성으로 복귀
3.2 Dynamic Latent Token Budget
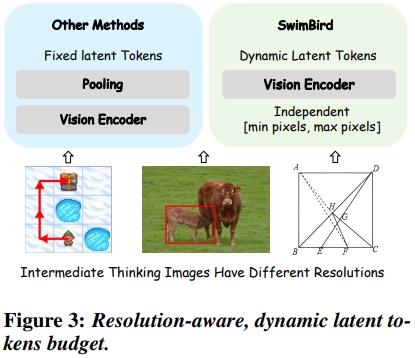
- 입력 이미지의 해상도에 따라 visual latent token수 조절
- 기존의 고정된 토큰 수의 문제점
- 고해상도 이미지에서는 용량 부족 / 저해상도 이미지는 계산 낭비
- 학습 중간에 중간 이미지를 고정된 길이로 생성해버리면 정보손실 발생 가능성
- SwimBird에서는 해상도를 고려해 동적 latent token 생성
- Qwen ViT 인코더의 고유 해상도 보존 특성을 활용
- 질문 이미지와 중간 단계의 사고 이미지에 대해 각각 다른 최대 픽셀 크기를 할당
- visual encoder가 생성하는 토큰의 개수가 이미지의 실제 정보량에 비례하도록 설계
- 잠재 토큰의 개수 K는 사전에 정의된 범위 [ N_min, N_max ] 내에서 이미지의 해상도와 쿼리의 난이도에 따라 가변적으로 결정
- 모델은 </latent>를 출력하여 중지를 결정할 때까지 토큰을 계속 생성 (vision 사고의 정도를 스스로 조절)
- 이런 방식의 장점?
- 정밀도 유지: 고해상도의 세밀한 분석이 필요한 이미지의 경우, 많은 Pooling을 피하고 더 많은 잠재 토큰을 할당함으로써 중요한 시각적 단서 보존 가능
- 연산 낭비 방지: 저해상도이거나 정보 밀도가 낮은 이미지의 경우, 불필요하게 많은 토큰 생성을 억제하여 추론 속도를 높이고 메모리 사용량 감소 가능
- 기존의 고정된 토큰 수의 문제점
3.3 Switchable Reasoning SFT Dataset Construction
- switchable reasoning mode학습을 가능하게 하기 위해 데이터큐레이션 파이프라인 설계

Step 1) 후보수집 + 쉬운 데이터 제거: ThinkMorph, Zebra-CoT, MathCanvas-Instruct 이용(중간 사고이미지가 포함된 데이터셋들)
Step 2) 모델을 이용한 라벨링: pass@8 지표 이용, Qwen3-235B-Instruct를 판정자로 사용해 score 0.75 이상인 것만 라벨링
Step 3) 텍스트 전용 CoT 추가: OpenMMReasoner 등에서 50,000개의 텍스트 전용 CoT 데이터를 추가
3. Experiments
- Training Details
- backbone: Qwen3-VL 8B
- 학습: SFT (SwimBird-SFT-92K)
- GPU: A100-80GB
- bs: 128
- LLM만 업데이트(vision encoder 와 multimodal projector 는 frozen)
- 스케줄러/학습률: cosine LR scheduler, 초기 LR = 1e-5
- Fine-grained Visual Understanding ( 고해상도 )
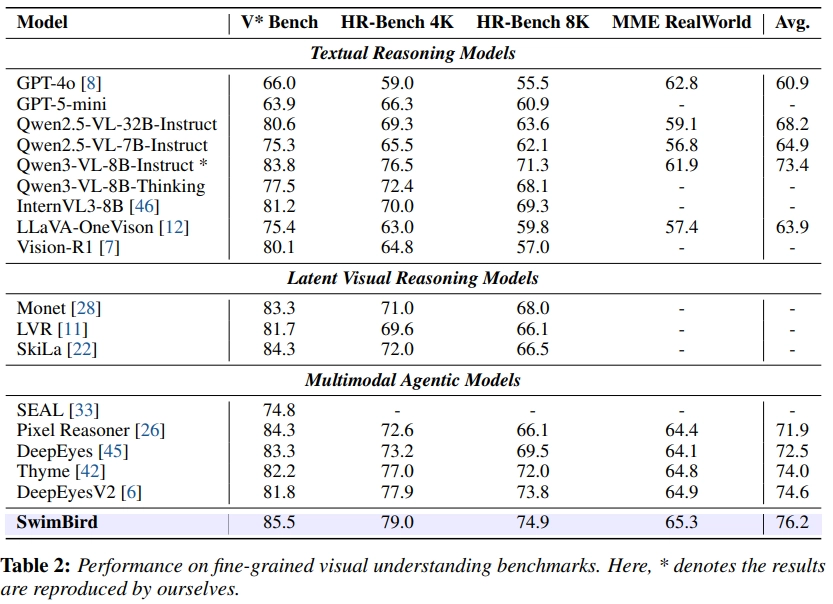
- 일반 VQA 및 멀티모달 추론
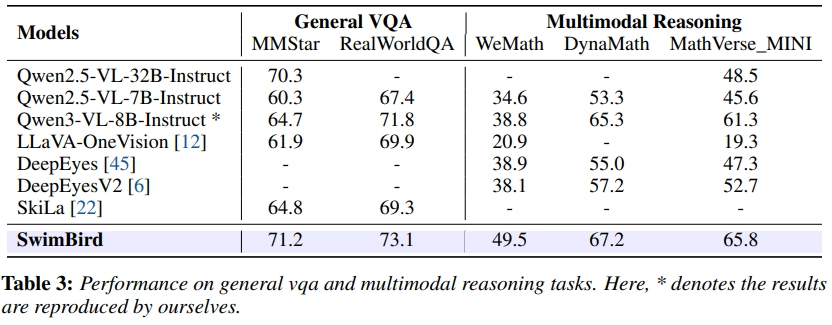
- 잠재 토큰 개수와 MSE 가중치에 따른 성능변화

- table 4: max 토큰 수에 따른 성능
- 32 일때 가장 좋은 성능 ⇒ 과도한 잠재 계산이 전체 추론을 방해할 수 있음을 보여줌
728x90
반응형