이 논문은 "비디오 관계 탐지"를 가장 처음 제안한 논문입니다.
<Introduction>
이 논문은 "Video Visual Relationship Detection" task를 처음 제안한 논문이며 이 task에 가장 처음 등장한 데이터 집합인 VidVRD를 제안한 논문입니다.
- Video Visual Relationship Detection이란?
VidVRD는 입력으로 주어지는 비디오 안에 등장하는 모든 물체들과 그들 간의 관계들을 탐지하여 <Subject(주어) - Relationship(관계) - Object(목적어)>의 형태로 나타내는 작업입니다. 이 작업은 비디오에 등장하는 모든 물체 트랙들을 탐지하고 시공간의 변화에 따라 변화하는 관계를 잘 탐지할 수 있는 방법을 요구합니다. 다시 말해, 물체 trajectory 탐지, 관계 탐지를 동시에 수행하는 높은 수준의 도전 과제라고 할 수 있습니다.
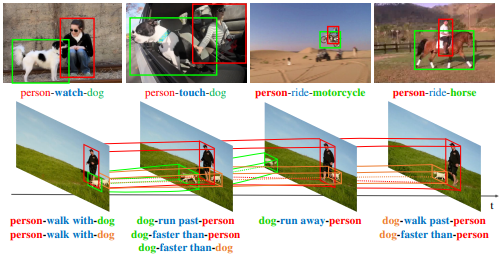
위 그림은 이미지에서의 관계 탐지와 비디오에서의 관계 탐지를 비교한 그림입니다.
-이미지에서는 등장하는 물체를 찾기 위해 물체 탐지(Object Detection)를 수행하지만 비디오에서는 변화하는 물체의 위치를 추적해야 하기 때문에 물체 추적(Object Tracking)을 수행합니다.
-이미지에서는 정적인 관계만을 다루지만 비디오에서는 다양한 동적인 관계를 다룹니다. 또한 동일한 주어와 목적어 사이에 시간이 변화함에 따라 관계가 변화하는 모습 또한 확인할 수 있습니다.
<Dataset>
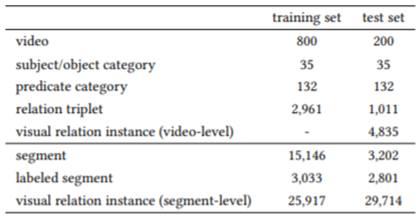
본 논문에서는 데이터 집합 VidVRD와 이 task를 위한 새로운 평가지표를 제안하였습니다.
- VidVRD Dataset
총 1000개의 비디오로 이루어져 있으며 training set : test set = 800 : 200입니다.
물체 카테고리는 airplane, antelope, ball, bicycle, cat, cattle, dog, elephant, motorcycle, person, sheep, skateboard, snake를 포함하여 35개가 존재합니다.
관계 카테고리는 ride와 같은 타동사, faster와 같은 비교 서술자, above와 같은 공간 관계 서술자, fly와 같은 자동사 등이 있습니다.
아래 표는 데이터 집합의 통계표입니다.
<Metrics>
1) Relationship tagging
=> Relation triple 예측
=> Precision 사용
2) Relationship detection
=> Relation triple, object trajectory예측
=> Recall 사용
<Model>
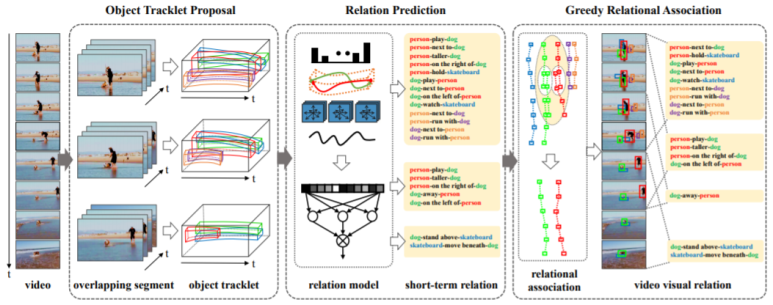
1) Object Tracklet Proposal
먼저 입력 비디오를 30프레임씩 일정한 크기의 비디오(segment)로 분할합니다. 이때 각 segment는 이웃 비디오와 15프레임씩 겹치게 분할합니다. 이는 등장하는 관계들 중 30프레임 이상 지속되는 관계들을 탐지하기 위함입니다.
=> per-frame detection: Faster R-CNN(ResNet 101)
=> object trajectory generation: MOSSE tracker(설명: https://neverabandon.tistory.com/2)
=> trajectory refinement: NMS
2) Relationship Prediction
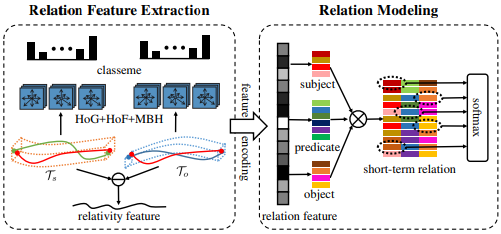
가능한 모든 물체 쌍들에 대해서 아래 feature들을 추출합니다.
=> 각 tracklet의 물체 클래스 분포도
=> 각 tracklet의 HoG, HoF, MBH
=> relativity feature
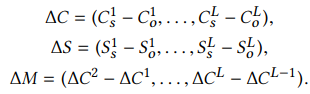
위 3가지 feature들을 모두 concatenation 해줍니다. 최종 feature로 주어 물체 분류, 관계 분류, 목적어 분류를 모두 수행하며 학습합니다. 이때 사용하는 loss 함수는 아래와 같습니다.
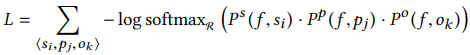
3) Greedy Relational Association
segment들 사이의 <s - p - o>관계를 하나로 통합해주는 과정입니다. short-term 관계들을 이어붙여 long-term관계가 될 수 있도록합니다.

모든 pair들에 대해 수행하고 두 <s - p - o>의 클래스가 같고 주어와 목적어의 트랙의 vIoU가 0.5이상이면 같은 관계로 판단합니다.
<Result>
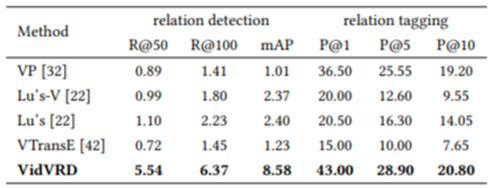
다른 모델들과의 성능 비교표입니다.
표에서 1~4번모델은 기존의 이미지 관계탐지 모델을 동영상 관계 탐지 모델로 변형한 것입니다.
본 논문에서 제안하는 Baseline Model이 가장 높은 성능을 보이고 있습니다.
<결론>
- VidVRD라는 새로운 vision task제안합니다.
- VidVRD라는 새로운 데이터 집합 제안합니다.
- 제안하는 task를 해결하기 위해 Object tracklet proposal - relation prediction - greedy relational association의 3단계로 이루어진 모델 제안합니다.