이 논문은 이전 논문에 이어서 비디오 관계 탐지에 관한 논문입니다. 이전 논문들은 VidVRD 데이터 집합을 사용하였지만 본 논문부터는 VidOR이라는 새로운 데이터 집합을 중점적으로 사용합니다.
<Introduction>
비디오에서의 관계 탐지를 위해 다양한 유형의 multi modal feature들을 사용한 논문입니다. 이전 논문들은 비디오내에 등장하는 물체들의 visual feature에 의존하던 것을 개선하여 visual feature이외에 다양한 feature를 사용합니다.
추가로, 이 논문에서는 [1] 논문의 object trajectory proposal 단계의 개선 방안 또한 제안합니다.
<Model>
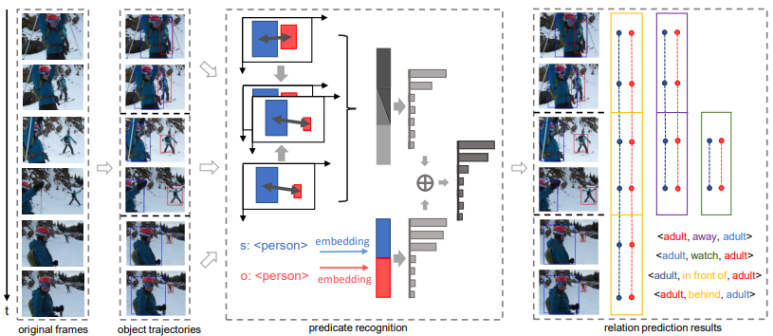
전체 구조도
1) Object trajectory proposal
[1] 논문과 마찬가지로 입력 비디오를 일정한 크기로 분할하는 segment방식을 사용합니다. 이 단계에서 [1]의 논문과 다르게 추가된 기법들은 아래와 같습니다.
- Flow-guided feature aggregation
=> 주변 frame들을 이용한 feature extract
- seq-NMS
=> Frame간의 등장 물체들의 갑작스런 변화를 해결
- Kernelized correlation filter
=> High-speed tracking
2) Predicate recognition
주어 물체와 목적어 물체의 위치 정보와 language feature를 동시에 사용합니다.
▶ Spatio-Temporal feature
- relative location feature: 주어 물체와 목적어 물체의 상대 좌표, 크기

- motion feature: 시작 프레임과 끝 프레임 사이에서 주어 물체와 목적어 물체의 상대 위치
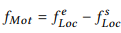
▶ Language context feature
- GoogleNews 데이터 집합을 이용한 Word2Vec모델을 이용
- 주어 물체와 목적어 물체의 예측 class 이용
최종적으로 위의 두 feature를 각각 서로 다른 분류기를 통과시켜 관계 클래스 분포도를 얻습니다. 얻어진 관계 클래스 분포도는 아래 식을 이용하여 fusion합니다. 이 fusion된 정보를 이용해 최종적으로 관계를 예측합니다.

<Result>
데이터 집합은 VidOR을 사용합니다. 아래는 VidVRD와 VidOR을 비교한 표입니다.
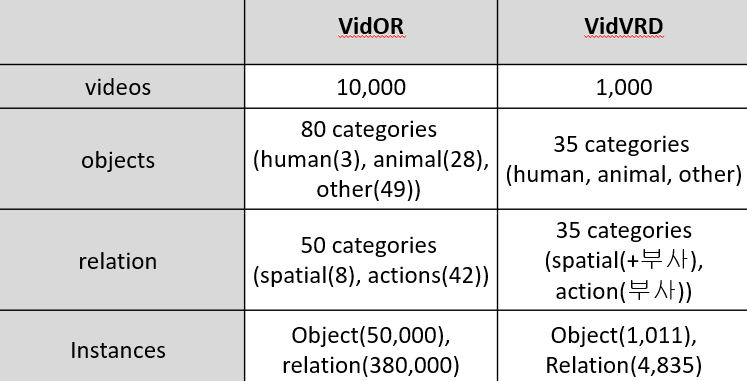
데이터 집합의 수가 확연히 증가하였고 그로인해 instance의 수도 훨씬 많아졌습니다. 뿐만 아니라 탐지하는 관계의 유형에도 차이가 있습니다. VidVRD는 "jump_left", "jump_right" 처럼 "jump"라는 하나의 관계도 방향에 따라 뒤에 여러 부사를 붙혀 관계 클래스를 다양화하였으나 VidOR에서는 이를 개선하여 순수하게 관계 클래스를 다양화 하였습니다.
아래는 실험 결과입니다.

제안하는 모델이 모든 평가 지표에 대해 우수한 성능을 보이는 것을 알 수 있습니다.
<결론>
- FGFA, seq-NMS, KCF방법을 이용하는 object trajectory detection module 제안
- multi-modal feature를 이용한 relation prediction module 제안