이번 포스팅에서는 EM Clustering에 대해 설명해보도록 하겠습니다. 간단히 얘기하자면 EM Clustering은 Expectation단계와 Maximization 단계를 이용하여 클러스터링합니다. 자세히 설명하기 전에 Soft Clusterting에 대해 먼저 설명하겠습니다.
- Soft Clustering
Soft Clustering은 여러 클러스터들이 서로 겹쳐질 수 있는 클러스터링을 말합니다. K-Means Clustering의 경우에는 K개의 클러스터를 가정한 뒤 각 클러스터의 평균을 기준으로 하여 클러스터링 하는 방식입니다. 이는 하나의 데이터는 하나의 클러스터에만 포함될 수 있는 구조입니다. 그러나 실세계의 데이터들은 꼭 하나의 클러스터에만 포함되지 않을 수도 있습니다. Soft Clustering는 이와 다르게 한 데이터가 여러 개의 클러스터에 포함될 수 있습니다. A가 직장 동료 그룹에 0.7만큼 친구 그룹에 0.3만큼 포함된다고도 설명할 수 있는 것입니다. EM Clustering은 Soft Clustering에 해당합니다. Soft Clustering을 위해 하나의 클러스터가 각각의 확률 분포를 가지는 상태를 기반으로 하여 EM Clustering 알고리즘이 작동합니다.
- EM Clustering
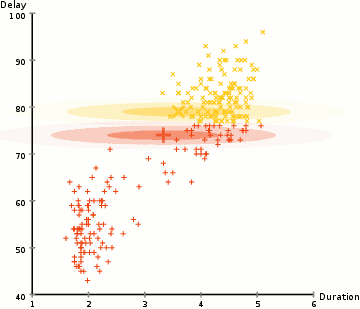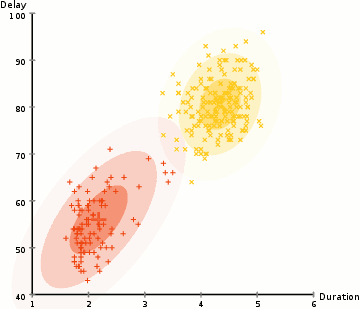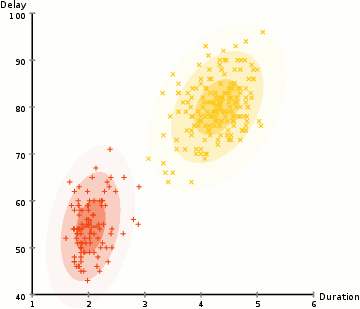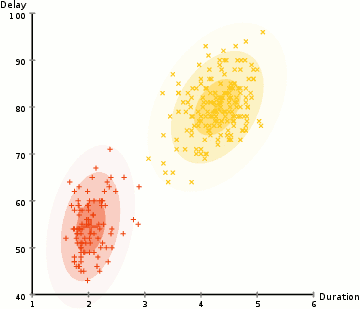
아래와 같이 클러스터를 알고 있는 데이터들이 주어졌다고 가정해보겠습니다.

이 클러스터의 확률분포의 모수를 어떻게 구할 수 있을까요? 노란색 데이터들의 평균과 분산을 구하고, 파란색 데이터들의 평균과 분산을 구하면 될 것입니다.
하지만 우리는 클러스터링 하고자 하는 데이터들의 분포를 알지 못합니다. 아래 그림처럼 분포를 알지 못하는 데이터들이 어떤 클러스터에 속하는지 알아내는 것이 클러스터링의 목적입니다.

이 때 각 클러스터 확률 분포의 모수를 알고 있다면 어떻게 될까요?

위 그림은 확률 분포의 모수가 주어진 모습입니다. 주어진 모수가 맞는지 틀린지에 상관없이 그냥 클러스터링 해본다면 아래처럼 클러스터링 해 볼 수 있을 것입니다. 확률 분포가 주어졌으므로 우리는 이 확률 분포를 바탕으로 각 데이터의 가능도(likelihood)를 구하고 그것을 기준으로 클러스터링 해줄 수 있습니다.

클러스터링이 된 결과를 바탕으로 각 데이터가 어떤 분포에 속하는지 알 수 있습니다. 그럼 여기서 다시 또 새로운 분포를 구할 수 있습니다! 결국 분포를 구하고 클러스터링을 하고, 다시 분포를 구하고...의 반복이라고 설명할 수 있습니다. 이 과정을 각각 Expectation 단계와 Maximization 단계라고 합니다.
- 데이터의 분포를 알면 각 데이터가 어떤 분포에 속한 데이터인지 알 수 있습니다. (Expectation 단계)
- 데이터가 어떤 분포에 속하는지 알면 데이터로부터 분포의 모수를 알 수 있습니다.(Maximization 단계)
EM Clustering 알고리즘은 랜덤한 확률 분포(보통 가우시간 분포를 가장 많이 사용합니다.)를 가정하고 위 두가지 과정을 반복적으로 수행합니다. K-Means와 유사하지만 앞서 설명한대로 EM Clustering 은 Soft clustering이라는 것입니다. 즉, 하나의 데이터가 A이냐 B이냐를 정하는 것이 아닌, 확률 분포를 구해 어떤 클러스터에 얼마만큼의 확률로 들어갈 수 있는지를 구하는 것입니다.
이제 구체적인 예시로 살펴보겠습니다. 위의 데이터에 초기 확률 분포는 가우시간 분포로 가정하겠습니다.
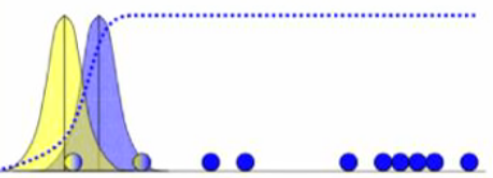
그럼 데이터들은 위와 같이 soft cluster들을 부여 받게 됩니다. 이는 Expectation단계에 해당합니다. 가능도 계산을 통해 얻어진 결과에 해당합니다. 가능도는 분포의 모수를 알고 있다면 베이즈 정리를 이용해 아래와 같은 식을 이용해 구할 수 있습니다.
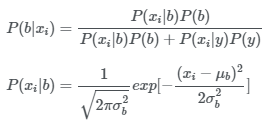
이렇게 각 데이터에 대해 soft clustering을 구하는 Expectation단계가 끝나면 각 데이터를 이용해 새로운 두 개의 확률 분포를 구합니다. 즉 새로운 두 확률 분포의 평균과 분산을 구하는 것입니다. 이는 Maximization 단계에 해당합니다. 파란색 분포의 평균과 분산은 아래 식을 이용해 구할 수 있습니다.
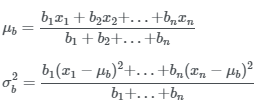
이렇게 새로운 클러스터 확률 분포의 모수들을 알았다면 이제 다시 데이터들을 클러스터링 해줄 수 있습니다.
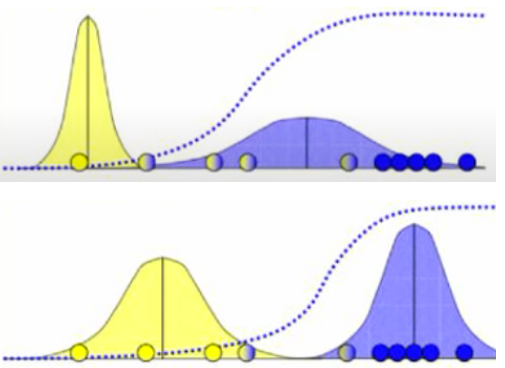
이 과정을 계속 반복하다 보면 더 이상 변하지 않는 단계에 도달하게 되고, clustering이 완료되었다고 볼 수 있습니다.
마지막으로 EM Clustering의 장단점에 대해 알아보겠습니다.
- 장점 : 얻을 수 있는 cluster의 모양이 K-means보다 다양하고 유연합니다. 또한 k-means와 다르게 확률 분포를 이용하기 때문에 하나의 데이터가 A cluster에 속할 확률, B cluster에 속할 확률 등의 형태로 분석 할 수 있습니다.
- 단점 : K-means 알고리즘과 마찬가지로 임의의 K값을 설정해주어야 합니다. 또한, 계산이 복잡하고 느립니다.
※ 정리
EM Clustering은 Expectation 단계와 Maximization 단계로 나뉘어지며 이 두 단계를 반복하며 최적의 파라미터를 찾는 과정입니다.
- Expectation 단계 : 주어진 파라미터 값에서 가능도를 구하고 cluster부여
- Maximization 단계 : 계산된 가능도를 최대화 하는 새로운 파라미터 값(=새로운 확률 분포)를 얻음
'AI Research > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 기초] 차원의 저주(Curse of Dimensionality) (0) | 2023.03.05 |
|---|---|
| [인공지능 기초] Likelihood(가능도, 우도) (0) | 2023.02.28 |
| [인공지능 기초] 결측치(Missing Value) 처리 (0) | 2023.02.28 |
| [인공지능 기초] 머신러닝 분류모델 정리 (0) | 2023.02.28 |
| [인공지능 기초] 나이브 베이즈 분류(Naive Bayes Classification) (0) | 2023.02.28 |