Github : https://github.com/rowanz/neural-motifs
<Introduction>
이미지에서의 장면그래프를 생성하는 모델에 대한 논문입니다. 이 논문에서는 데이터 집합에서의 등장 패턴을 분석하여 그 분포를 예측에 사용합니다.
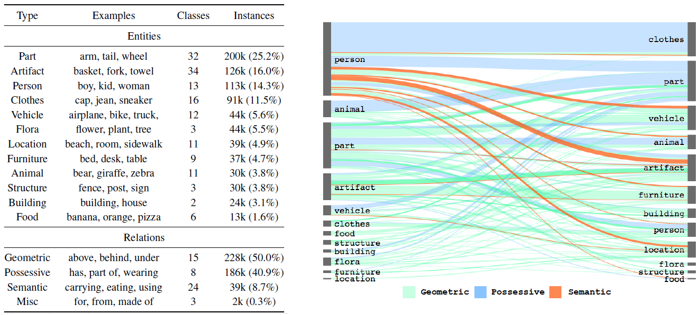
왼쪽의 표는 사용 데이터 집합인 Visual Genome의 object와 relation의 타입을 분석한 표입니다. object의 대부분은 "part"에 속하고, relation의 대부분은 "geometric"과 "possessive"에 속하는 것을 알 수 있습니다. 오른쪽 그림은 고 수준 간선들의 유형을 나타냅니다. "Geometric", "possessive" , "semantic"이 각각 50.9%, 40.9%, 8.7%를 차지합니다. 특히 semantic관계의 대부분은 사람과 차량, 구조물 사이의 위치관계임을 알 수 있습니다.
위 그림들을 통해서 알 수 있는 사실은 요소들 사이의 의존성이 매우 크다는 것입니다. 따라서 이러한 학습 데이터에서의 분포 비율을 통한 예측 또한 가능하다고 할 수 있습니다.
이와 관련하여 "motif" 라는 용어가 등장합니다. ("패턴" 정도로 이해하면 좋을 것 같습니다.)
이 논문에서는 반복적으로 등장하는 subgraph를 2개 이상의 triple로 구성합니다.
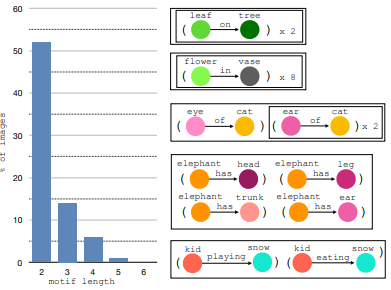
따라서 이 논문에서는 Object detection + 데이터 분포로부터 추정하고 물체 종류로부터 제일 많이 등장했던 관계를 선택하는 방식으로 모델을 구성합니다.
<Model>
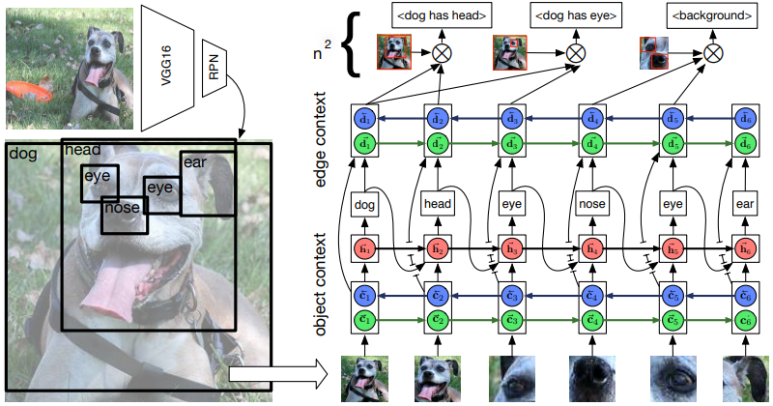
1) Object Detection
Faster R-CNN에 백본으로 VGG 네트워크를 이용합니다.
2) Object Context
1에서 제안된 물체 영역들을 bidirectional LSTM을 거쳐 물체의 전체적인 맥락 정보를 파악한 후 물체의 카테고리를 분류합니다.
3) Edge Context
2에서 얻은 물체의 카테고리, 맥락 정보를 동일하게 bidirectional LSTM을 거쳐 edge context 정보를 추출합니다.
2와 3의 과정에서 동일하게 highway LSTM이 적용됩니다.
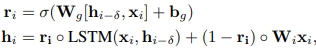
이 방법을 통해 radient vanishing problem 보완하고 skip connection 처럼 깊이를 줄이는 효과를 얻을 수 있습니다.
<Result>
데이터 집합은 Visual Genome을 사용합니다.
- object 150, relation 50 (positive : negative = 1 : 3)
- 두 물체가 겹치지 않으면 relation 삭제
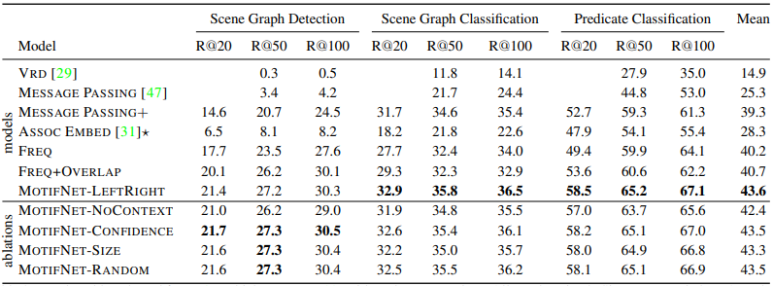
제안하는 MotifNet이 가장 높은 성능을 보이고 있음을 알 수 있습니다. 또한 LSTM의 입력으로 이미지의 왼쪽에서부터 등장하는 바운딩 박스를 먼저 넣엇을 때 가장 높은 성능을 보이고 있음을 알 수 있습니다.
<결론>
- 데이터집합 내에 존재하는 다양한 패턴분석
=> motif(패턴) 만을 이용하여 관계 분류 가능함을 실험을 통해 입증.
- 탐지된 물체로부터 맥락 정보를 활용
=> object 카테고리 분류
=> relationship 카테고리 분류
'Paper Review > Image Scene Graph Generation' 카테고리의 다른 글
| [6] Exploring the Semantics for Visual Relationship Detection (0) | 2023.03.07 |
|---|---|
| [5] Graph R-CNN for Scene Graph Generation (0) | 2023.03.07 |
| [4] Factorizable Net: An Ecient Subgraph-based Framework for Scene Graph Generation (0) | 2023.03.07 |
| [3] Scene Graph Generation from Objects, Phrases and Region Captions (0) | 2023.03.06 |
| [1] Scene Graph Generation by Iterative Message Passing (0) | 2023.03.06 |