논문 링크 : http://cvboy.com/pdf/publications/iccv2017_msdn.pdf
Guthub : https://github.com/yikang-li/MSDN
<Introduction>
본 논문에서는 이전 논문들처럼 Object detection, relation detection방법을 수행하고 추가로 image captioning까지 세 가지 작업을 수행하는 프레임 워크 제안합니다.
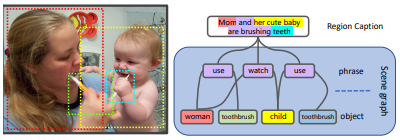
위 3가지 작업을 동시에 진행하여 서로 다른 semantic level을 학습할 수 있습니다.
이미지가 주어지면 물체, phrase, caption을 위한 그래프 생성합니다. 이는 이미지마다 물체, phrase, caption이 모두 다르기 때문에 동적 그래프를 생성할 수 있도록 합니다.
feature 갱신은 message passing을 통해서 하며 세 작업들 사이에 서로 다른 semantic level의 메시지 전달하면서 이루어집니다.
<Model>

전체 구조도
1) Object Detection
백본 네트워크로 VGG16을 사용하는 RPN(Region Proposal Network)를 이용
•Object region: N개
•Phrase region: N^2개
•Caption region: gt로 부터 훈련된 다른 RPN에 의해 생성(이 RPN은 phrase와 object 모두 포함하게 훈련)
2) Dymamic Graph Construction

•Phrase-object: phrase region 생성시 자연적으로 같이 생성
•Phrase-caption: 공간 관계 기반으로 연결
=> Caption region box와 phrase region box가 일정 비율이상 겹치면 관련 있다 판단
3) Feature Refining
서로 다른 레벨들 간에 메세지를 주고 받는 Message Passing 단계
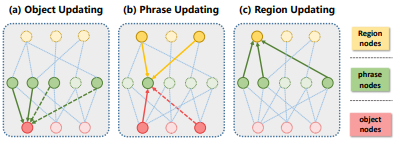
- Object Updating
해당 object와 연결된 모든 phrase node값에 대한 연산 결과

Object 노드 업데이트시에 해당 노드가 subject에 있을 때와 object에 있을 때를 구분
- Phrase Updating
Object 물체와 subject물체, caption노드의 정보를 이용하여 업데이트

-Region Updating
이전 caption정보와 관련 있는 phrase정보를 이용하여 업데이트
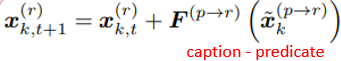
4) Scene Graph and Region Caption Generation
Message passing후 => fully connected graph
Object : object class / background 로 예측
Relation : predicate class / irrelevant 로 예측
Caption : LSTM모델을 이용해 예측
<Result>
이전 연구들과 동일하게 Visual Genome dataset 사용
=> 자주 등장하는 상위 150개의 object종류와 상위 50개의 서술어 선택
=> 95998개의 이미지
Training 75998 / Testing 25000개

다른 모델들에 비해 높은 성능을 보이는 것을 확인 할 수 있습니다.
<결론>
- object detection, visual relationship detection and region captioning을 결합한 새로운 모델 제안(Multilevel Scene Description Network, MSDN)
- 입력 이미지가 주어지면 서로 다른 의미적 레벨에서 연관성을 찾기 위해 그래프 설계 => 이 그래프는 서로 다른 task사이에서 feature를 결합하는 새로운 방법 제안
'Paper Review > Image Scene Graph Generation' 카테고리의 다른 글
| [6] Exploring the Semantics for Visual Relationship Detection (0) | 2023.03.07 |
|---|---|
| [5] Graph R-CNN for Scene Graph Generation (0) | 2023.03.07 |
| [4] Factorizable Net: An Ecient Subgraph-based Framework for Scene Graph Generation (0) | 2023.03.07 |
| [2] Neural Motifs: Scene Graph Parsing with Global Context (0) | 2023.03.06 |
| [1] Scene Graph Generation by Iterative Message Passing (0) | 2023.03.06 |