▶ 앙상블 학습(Ensemble Learning)이란?
앙상블 학습은 여러 개의 모델을 생성하고, 그 모델들의 예측을 결합하여 보다 나은 예측 결과를 도출하는 방법입니다. 강력한 모델 하나만을 사용하는 대신 조금 약한 모델들을 조합하여 더 정확한 예측을 하겠다는 방식입니다. 앙상블 학습은 굉장히 강력한 학습법인만큼 캐글에서 XGBoost, LightGBM과 같은 앙상블 알고리즘들이 큰 인기를 끌고 있습니다. 가장 기본적인 앙상블 알고리즘으로는 보팅(voting), 배깅(bagging), 부스팅(boosting), 스태킹(stacking) 등이 있습니다.
▶보팅(voting)
여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식입니다. 서로 다른 알고리즘을 여러 개 결합하여 사용합니다. 아래 그림에서는 Decision Tree, k-Nearest Neighbor, Logistic Regression을 사용하였습니다.
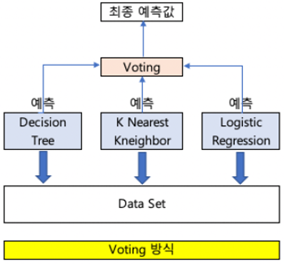
보팅 방식에는 하드보팅(hard voting)과 소프트보팅(soft voting)이 있습니다.
- 하드 보팅 : 다수의 분류기가 예측한 결과값을 최종 결과로 선정하는 방식입니다.
- 소프트 보팅: 모든 분류기가 예측한 레이블 값의 결정 확률 평균을 구한 다음 가장 확률이 높은 레이블 값을 최종 결과로 선정하는 방식입니다.

▶배깅(Bootstrp Aggregation, bagging)
데이터를 샘플링(bootstrap)을 통해 분류기들을 학습시키고 결과를 집계(aggregating)하는 방법입니다. 이때 사용되는 분류기들의 알고리즘은 모두 동일합니다. 데이터를 분할할 때는 중복을 허용하여 분할합니다. 이 방식은 과적합 방지에 효과적입니다. 가장 대표적인 알고리즘으로는 랜덤 포레스트 알고리즘입니다.

데이터를 샘플링하는 bootstrap 방법부터 자세히 설명해 보면, 아래 그림처럼 중복을 허용해 데이터를 분할합니다.

마지막까지 한번도 추출되지 않는 데이터들은 검증데이터로 사용됩니다. 추출된 데이터 샘플들은 각 분류기에 넣고 학습시킵니다.
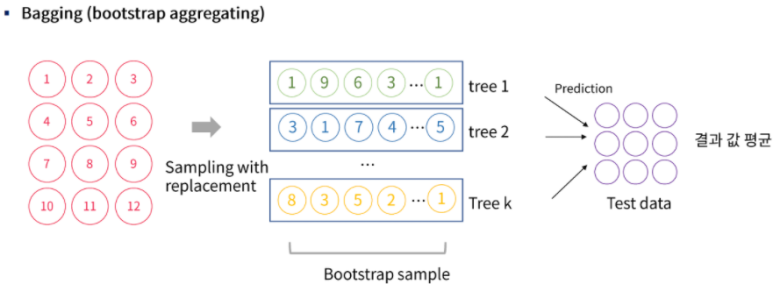
학습시킨 후 각 트리의 결과를 하나로 합해줍니다. 이때 categorical data라면 다수결 투표 방식으로 보팅 하고, continuous data 라면 평균값 집계 방식으로 보팅 해줍니다.
배깅의 장단점은 아래와 같습니다.
- 장점 : 모델의 분산을 잘 줄일 수 있습니다. 동일 알고리즘의 다양한 모델의 결과를 이용하기 때문에 결과가 더 잘 예측되고, 병렬적으로 학습하기 때문에 분산을 줄이고 과적합을 피할 수 있습니다.
- 단점 : 데이터 샘플링시에 중복을 허용하기 때문에 특정 데이터에 편향될 가능성이 있습니다. 또한 데이터가 적은 경우에는 데이터를 잘 반영하지 못할 수도 있으며, 이상치가 많은 경우 예측 결과가 왜곡될 수 있습니다. 또한 독립적인 데이터에만 사용가능합니다.
▶부스팅(boosting)
부스팅은 가중치를 활용하여 약한 분류기를 강한 분류기로 만드는 방법입니다. 이 방법은 분류기들 간에 팀워크가 이루어진다고 생각하면 쉽게 이해할 수 있습니다. 처음 분류기가 예측을 하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 주게 됩니다. 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복합니다.

위 그림처럼 +와 -를 분류하는 문제를 예로 들어보겠습니다. 첫 번째 분류기의 구분선(점선)은 위쪽의 + 한 개와 아래 쪽의 - 두 개, 총 3개를 잘못 분류한 구분선입니다. 따라서 다음 분류기에서는 잘못 분류된 3개의 데이터에 대해서는 가중치를 부여해 주고 나머지 잘 분류된 데이터에는 가중치를 낮춰줍니다. (+,-의 크기가 커진 것은 가중치가 커졌다는 의미입니다.)
두 번째 분류기의 구분선은 오른쪽 3개의 -가 잘못 분류되었습니다. 따라서 다음 그림에서 3개의 -가 가중치가 커졌습니다. 이렇게 첫 번째~세 번째 분류기를 모두 합쳐 최종 분류기를 구할 수 있습니다. 최종 분류기는 +와 -를 정확히 구분할 수 있게 됩니다.
부스팅의 장단점은 아래와 같습니다.
- 장점 : 잘못 분류된 것에는 높은 가중치를 부여하고, 잘 분류한 것에는 낮은 가중치를 부여하기 때문에 잘못한 것에 더 집중하여 학습할 수 있습니다.
- 단점 : 이상치에 취약합니다.
※ 배깅과 부스팅의 차이

위 그림에서 알 수 있듯이 배깅은 병렬적으로 학습하고 부스팅은 순차적으로 학습합니다. 부스팅은 배깅에 비해 성능이 좋지만 속도가 느리고 오버피팅 될 수 있습니다. 따라서, 개별 결정 트리의 낮은 성능이 문제라면 부스팅을 선택하는 것이 좋고, 오버피팅을 해결하고자 한다면 배깅을 선택하는 것이 좋습니다.
▶스태킹(stacking)
스태킹은 서로 다른 모델들을 조합해서 최고의 성능을 내는 모델을 생성합니다. 이전에 설명한 방법들은 동일 알고리즘을 적용한 여러 모델을 이용해 하나의 모델을 만들었던 반면에, 스태킹은 서로 다른 알고리즘을 적용한 모델들을 이용해 하나의 모델을 만듭니다. 스태킹은 여러 모델들의 예측 결과 값을 하나의 데이터로 만들고 다른 모델(Meta Learner)을 재학습시켜 결과를 예측합니다.

Base Learner는 SVM, 랜덤 포레스트, KNN등등 다양한 방식을 가질 수 있습니다.
스태킹의 장단점은 아래와 같습니다.
- 장점 : 여러 방식을 적용하고 장점만 취하기 때문에 성능이 향상됩니다. 또한 앙상블의 본래 목적인 높은 분산 문제를 해결할 수 있습니다.
- 단점 : 과적합이 발생할 가능성이 높으며 많은 연산량을 가집니다.
- 참고 2 :https://pangyo-datascientist.tistory.com/entry/%EC%95%99%EC%83%81%EB%B8%94-Bagging
'AI Research > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 1 (0) | 2023.02.28 |
|---|---|
| [인공지능 기초] 정규화 (Normalization) (0) | 2023.02.26 |
| [인공지능 기초] Regularization (0) | 2023.02.26 |
| [인공지능 기초] 랜덤 포레스트(Random Forest) (0) | 2023.02.26 |
| [인공지능 기초] 결정 트리(Decision Tree) (0) | 2023.02.26 |