이번 포스팅과 다음 포스팅에서는 회귀(regression)에 대해 설명하겠습니다. 이번 포스팅에서는 선형회귀와 선형회귀의 학습 과정에 대해 다루도록 하겠습니다.
▶ 선형 회귀(Linear Regression)란?
머신러닝은 모델을 생성하여 여러 인풋 값에 대해 적절한 아웃풋을 예측하는 것이 목적입니다. 이 때 입력 대비 아웃풋을 가장 잘 표현할 수 있는 것이 선(line)입니다. 이렇게 데이터를 두고 그것을 잘 표현할 수 있는 선을 찾는 것을 선형 회귀(Linear Regression)라고 합니다. 예를 들어, 키와 몸무게 데이터들을 표현한 데이터가 있다면, 그것들을 잘 표현할 수 있는 선을 찾으면 특정인의 키를 바탕으로 몸무게를 예측할 수 있게됩니다. 키를 독립변수, 독립변수의 변화에 따라 어떻게 변화하는지 알고싶은 몸무게를 종속 변수라고 합니다.
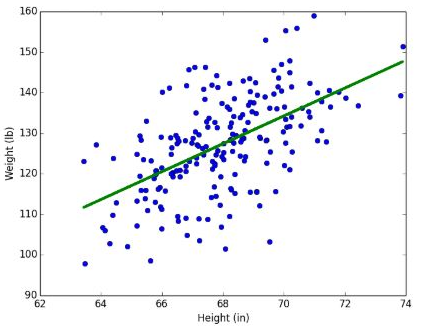
만약 독립 변수가 1개면 단순 선형 회귀 분석(simple linear regression analysis)이라고 하고, 아래 식처럼 나타낼수 있습니다.
기울기 w, 절편 b에 따라 그 선의 모양이 달라지기 때문에 x를 인풋으로 넣었을 때 적절한 아웃풋 y를 구할 수 있게 됩니다. 선형회귀의 목적은 우리가 가진 데이터를 가장 잘 표현할 수 있는 가장 적합한 w와 b를 얻는 것입니다.
독립 변수가 여러개인 경우를 다중 선형 회귀 분석(multiple linear regression analysis)이라고 합니다. 예측 해야할 아웃풋 y는 1개이지만 y를 예측하기 위해 필요한 독립변수 x가 여러개인 경우를 말합니다. 아래 식처럼 나타낼 수 있습니다.
집 층의 수, 방 갯수, 지하철 역과의 거리를 이용해 집의 매매 가격을 예측하는 경우가 다중 선형회귀 분석에 속합니다.
이제 단순 선형 회귀 모델을 예시로 들어 학습이 어떻게 이루어지는지 설명해보겠습니다.
아래는 학생의 공부시간과 점수를 나타낸 데이터입니다. 표로 표현하면 왼쪽과 같고 좌표평면에 그리면 오른쪽과 같습니다.
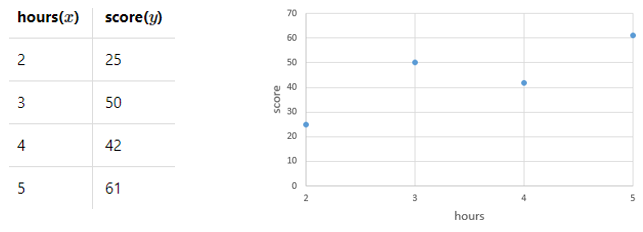
x,y의 관계를 유추하기 위해서 수학적으로 여러식을 세워보고 이를 식으로 표현해보겠습니다.
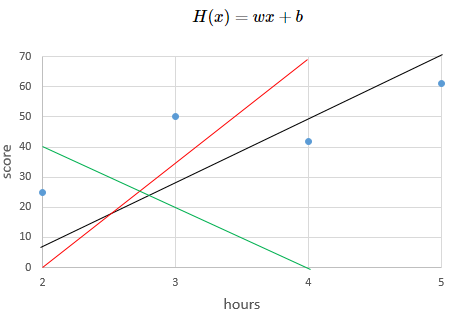
위의 좌표 평면에 w=13, b=1인 임의의 직선 y=13x+1을 그려보겠습니다. 임의의 직선이기 때문에 당연히 정답이 아니며, 이 직선으로부터 w,b의 값을 조금씩 바꾸며 주어진 데이터를 표현하는 정답 직선을 찾아야 합니다. 정답 직선이란 y와 x의 관계를 가장 잘 나타내는 직선을 그리는 것이고, 좌표 평면에 표현된 모든 점들과 위치적으로 가장 가까운 직선을 그리는 것입니다. 이제 임의의 직선과 데이터 사이의 오차를 구해보겠습니다.
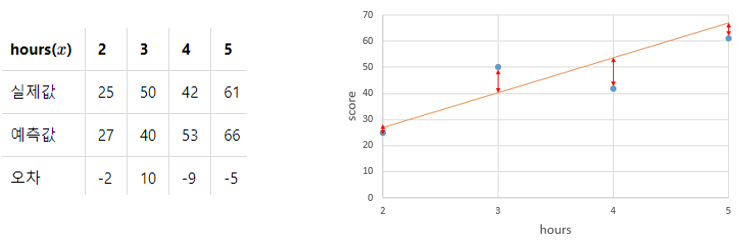
손실함수는 평균 제곱 오차(Mean Squared Error, MSE)를 사용하겠습니다. MSE는 회귀 분석 문제에 가장 많이 사용되는 손실 함수입니다.
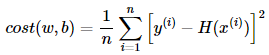
y=13x+1의 예측값과 실제값의 오차는 52.5입니다.
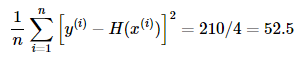
이제 이 오차를 점점 줄여 최소가 되게 만드는 w와 b를 구해야합니다.
선형 회귀를 포함하여 수많은 머신 러닝, 딥 러닝의 학습은 결국 손실 함수를 최소화하는 매개 변수인 w와 b를 찾아가는 작업을 수행하는 것입니다. 이때 사용되는 알고리즘을 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 합니다. 그리고 이 옵티마이저를 통해 적절한 w와 b를 찾아가는 과정을 머신 러닝에서 훈련(training) 또는 학습(learning)이라고 합니다. (옵티마이저에 대해 더 자세히 알고싶다면 이 포스팅과 이 포스팅을 참조해주세요)
w는 찾아야하는 직선에서는 기울기, 머신러닝에서는 가중치로 불립니다. 아래 그래프는 w의 기울기에 따라 오차가 어떻게 달라지는지 그려놓은 것입니다.
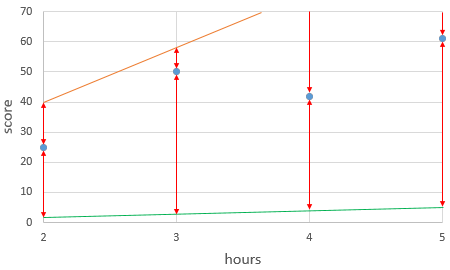
주황색 선을 보면, 기울기가 지나치게 크면 실제 값과 예측 값의 오차가 커지는 것을 알 수 있습니다. 또한 초록색 선을 보면 기울기가 지나치게 작을 때도 오차가 커지는 것을 알 수 있습니다. 이제 경사하강법을 수행해보겠습니다. 기울기 w와 손실함수 MSE의 관계를 그래프로 표현하면 아래처럼 그릴수 있습니다.
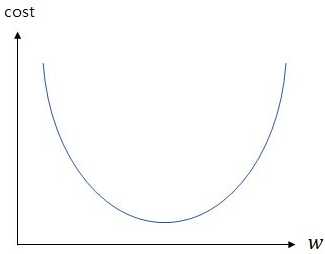
그래프를 해석해보면 기울기 w가 무한대로 커지면 cost값도 무한대로 커지고, 무한대로 작아져도 cost의 값이 무한대로 커집니다. cost가 가장 작은 부분은 가운데 볼록한 부분입니다. 저 곳의 w값을 찾는 것이 학습의 목표입니다. 기계는 랜덤하게 w값을 정하고 최적의 w값을 향해 계속 수정해 나갑니다. 이를 수행해주는 것이 경사하강법입니다.
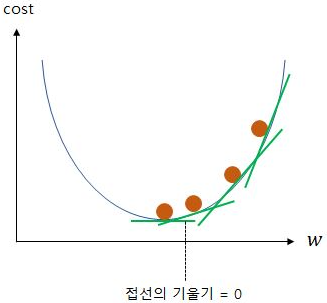
위 그림에서 초록색 선은 w가 임의의 값일때 그 점에서 접선의 기울기를 의미합니다. 도달해야하는 볼록한 부분으로 갈수록 기울기가 줄어드는 것을 알 수 있습니다. 점차 그 지점으로 가다보면 결국 접선의 기울기가 0이 됩니다. 즉, cost가 최소화가 되는 지점은 접선의 기울기(미분값)가 0이 되는 지점입니다. 다시 말해, 현재 w에서의 미분하여 접선의 기울기를 구하고, 접선의 기울기가 줄어도는 방향으로 w의 값을 변경하고, 다시 미분하고 이 과정을 접선의 기울기가 0인 곳을 향해 w의 값을 변경하는 작업을 반복하는 것에 있습니다.
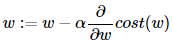
w 갱신 식
위의 식은 현재 w의 미분값과 a와 곱한 값을 w에서 빼서 w 값을 갱신하는 것을 의미합니다. a는 학습률을 의미하며 w의 값을 변경할 때 얼마나 크게 병경할지를 결정하는 값입니다.. 현재의 w값에서 w의 미분값을 빼는건 어떤 의미가 있을까요?
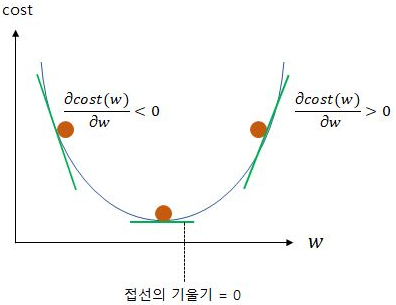
위의 그림은 차례대로 공이 접선의 기울기가 음수, 0, 양수인 지점에 있을 때를 나타냅니다. 기울기가 음수면 위의 w갱신 식에 의해 해당 값을 양수로 바꾸고 더하는 것과 같습니다. 결론적으로 w의 값이 증가하는 것이고 접선의 기울기가 감소하게됩니다. 만약 기울기가 양수면 전체적으로 w의 값이 감소하게되고 이 역시 기울기가 감소하게 됩니다. 이렇게 기울기가 음수든, 양수든 모두 접선의 기울기가 0인 지점을 향해 w의 값을 조정하게 되는 것입니다.
'AI Research > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 기초] 서포트 벡터 머신(Support Vector Machines, SVM) (0) | 2023.02.28 |
|---|---|
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 2 (0) | 2023.02.28 |
| [인공지능 기초] 정규화 (Normalization) (0) | 2023.02.26 |
| [인공지능 기초] Regularization (0) | 2023.02.26 |
| [인공지능 기초] 랜덤 포레스트(Random Forest) (0) | 2023.02.26 |