▶ 서포트 벡터 머신(Support Vector Machines, SVM)이란?
서포트 벡터 머신은 분류에 쓰이는 지도학습(supervised learning)모델 중 하나입니다. 학습을 통해 데이터를 분류하는 기준선인 결정 경계(decision boundary)를 알아냅니다. 이때 결정 경계는 속성의 차원에 따라 선이나 면이 될 수 있습니다.
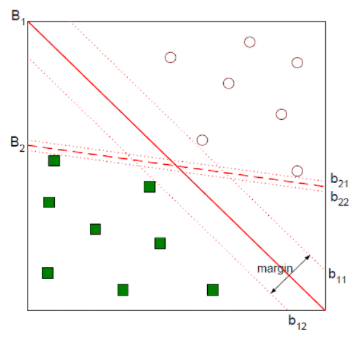
위 그림을 보면 실선인 B1과 점선인 B2모두 동그라미 데이터와 네모 데이터를 무난하게 분류하고 있습니다. 두 데이터를 분류하는 선을 긋는 방법은 무수히 많을 것입니다. 하지만 가장 나은 결정 경계는 B1입니다. 그을 수 있는 선들중에서 가장 여유있게 분류를 해주고 있기 때문입니다. 위 그림에서 b11을 plus-plane, b12를 minus-plane이라고 하며, 이 둘 사이의 거리를 마진(margin, 다음 항목에서 설명합니다.)이라고 합니다. 또 다른 예를 살펴보겠습니다.
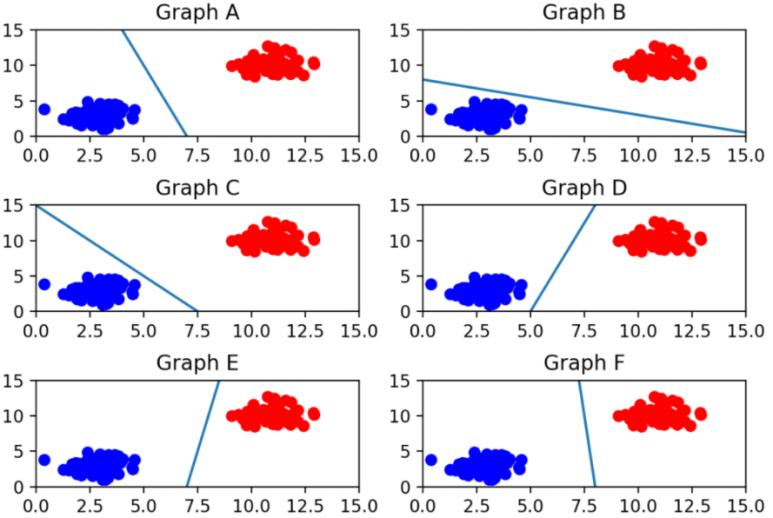
위 그림에서 두 데이터를 구분하는 가장 최적의 선은 바로 F입니다. 선이 어느 한쪽으로 치우치지도 않고 두 데이터 사이에서 거리가 가장 멀기 때문입니다.
이처럼 서포트 벡터 머신은 이 마진을 최대화 하는 결정 경계를 찾는 것입니다. 서포트 벡터(support vector) 는 결정 경계와 가까이 있는 데이터 포인트들을 의미합니다.
▶ 마진(margin)
결정 경계와 서포트 벡터 사이의 거리를 의미합니다.

가운데 그어진 실선이 결정 경계가 되겠습니다. 그리고 이 실선으로부터 검은 테두리의 빨간점과 파란점까지의 영역을 두고 실성과 평행하게 선을 그었습니다. 이 점선으로부터 결정 경계까지의 거리가 바로 마진입니다. 이를 통해 알 수 있는 것은 최적의 결정 경계는 마진을 최대화 한다는 것입니다.
대부분의 지도학습 알고리즘들은 모든 학습 데이터를 사용하여 학습하지만 서포트 벡터 머신은 서포트 벡터만 잘 고르면 나머지 데이터들은 무시할 수 있기 때문에 매우 빠르게 동작합니다. 결정 경계를 정의하는 것이 서포트 벡터이기 때문에 가능한 것입니다.
▶ 이상치(outlier) 허용
서포트 벡터 머신은 데이터를 올바르게 분류하면서 마진의 크기를 최대화 해야 하는데 이는 결국 이상치를 얼마나 잘 다루는지와 관련이 있습니다. 아래 그림을 보겠습니다.

위 두개의 그림에서 왼쪽에 동떨어진 파란 점과 오른쪽에 동떨어진 빨간 점이 바로 이상치(outlier)입니다.
왼쪽 그림은 이상치를 허용하지 않고 기준을 까다롭게 세운 것입니다. 이를 하드 마진(hard margin)이라고 합니다. 또한 서포트 벡터와 결정 경계 사이가 매우 좁아 마진이 매우 작습니다. 이렇게 개별적인 학습 데이터들을 다 놓치지 않으려고 이상치를 허용하지 않도록 결정 경계를 잡는다는 오버피팅 문제가 발생할 수 있습니다.
오른쪽은 이상치들이 마진안에 어느 정도 포함되어 있습니다. 왼쪽 보다는 유하게 기준을 잡아준것입니다. 이를 소프트 마진(soft margin)이라고 합니다. 이렇게 결정경계를 잡으면 마진이 커집니다. 어느 정도 이상치를 허용하지만 너무 대충 학습을 하게 되는 것이라 언더 피팅(underfitting)문제가 발생할 수 있습니다.
▶ 커널 트릭(kernel)
지금까지 예시로 나온 결정경계들은 모두 선 하나였습니다. 선 하나로 구분이 불가능한 데이터들은 어떻게 구분해줄 수 있을까요?

위 데이터가 이에 속합니다. 이런 경우에는 차원을 올려서 해결할 수 있습니다. 위 그림은 현재 2차원이니 3차원으로 변형해주어야 합니다. 차원을 변경해주는 커널에는 다양한 종류가 있지만 여기서는 다항식 커널(polynomial kernel)을 사용하겠습니다.
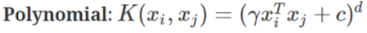
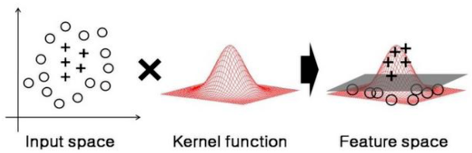
2차원의 데이터를 커널 트릭을 이용해 3차원으로 사상하면 아래와 같은 결과를 얻을 수 있습니다.

데이터를 높은 차원으로 변령하였더니 초평면(hyperplane)의 결정 경계를 얻을 수 있게 되었습니다.
즉, 커널 트릭은 주어진 데이터를 고차원 특성 공간으로 사상해 주는 것입니다. 실제로는 특성이 추가되는 것이 아니지만 특성을 많이 추가한 것과 동일한 효과를 얻을 수 있습니다.
또 다른 커널에는 방사 기저 함수(Radial Bias Function, RBF)가 있습니다. RBG커널, 가우시안 커널이라고 부릅니다. 간단히 설명하자면 2차원 점을 무한한 차원의 점으로 변환해줍니다.

성능이 좋아 자주 사용되는 커널입니다. 다항식 커널과 동일하게 r감마가 들어있는 것을 알 수 있습니다.
이 변수는 결정경계를 얼마나 유연하게 그을 것인지, 학습데이터에 얼마나 민감하게 반응할 것인지 정해주는 변수입니다. 아래 그림은 감마의 값에 따라 결정경계가 그려지는 모습입니다.
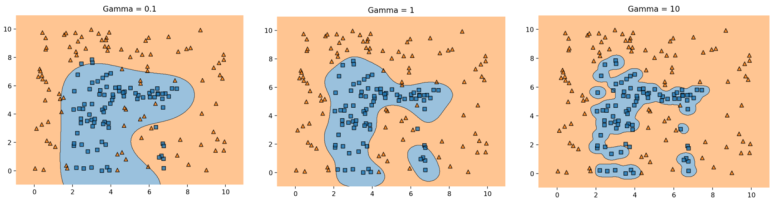
차례대로 감마가 0.1, 1, 10일때를 나타낸 것입니다. 감마가 너무 작으면 결정 경계가 대충 그려져 언더 피팅이 발생합니다. 반대로 감마가 너무 높으면 오버피팅이 발생하는 것을 알 수 있습니다.
▶ 회귀에서의 서포트 벡터 머신
지금까지는 서포트 벡터 머신을 분류에 사용하는 경우만 가지고 설명하였습니다. 회귀에서도 사용할 수 있는데 이를 서포트 벡터 회귀(support vector regression, SVR)라고 합니다. 회귀문제에 사용하려면 어떻게 해야 할까요? 이때는 데이터를 대표하는 선을 만드는 것이 목표가 됩니다. 분류 문제에서와 반대로 선 안에 데이터들이 들어가도록 학습시키는 것이 목표입니다.

마진안에 가능한 많은 샘플이 들어가도록 학습시키면 됩니다. 마진 밖에 있는 데이터들의 에러가 최소가 되도록 동작합니다.
▶ 서포트 벡터 머신의 장단점
- 장점: 오류 데이터의 영향이 적고 과적합이 잘 일어나지 않습니다. 분류 문제 뿐만 아니라 회귀에도 사용가능합니다. 비선형 데이터도 커널 트릭만 이용하면 분류할 수 있습니다.
- 단점: 데이터가 많아질수록 학습 속도가 느리고 메모리를 많이 사용합니다. 오버피팅과 언더피팅을 피하기 위해 매개 변수를 잘 설정해주어야 하며 분석이 어렵다는 단점이 있습니다.
'AI Research > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 기초] 나이브 베이즈 분류(Naive Bayes Classification) (0) | 2023.02.28 |
|---|---|
| [인공지능 기초] K-Means Clustering (0) | 2023.02.28 |
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 2 (0) | 2023.02.28 |
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 1 (0) | 2023.02.28 |
| [인공지능 기초] 정규화 (Normalization) (0) | 2023.02.26 |