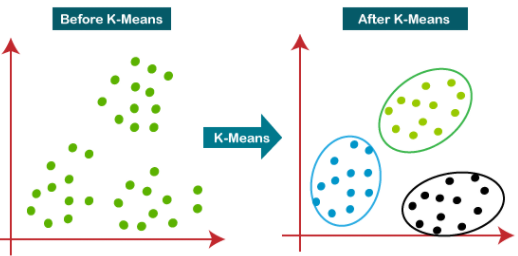
▶K-Means clustering(k - 평균 군집화)이란?
이 알고리즘은 널리 사용되는 비지도학습(unsupervised learning) 알고리즘입니다. 이 알고리즘에 대해 설명하기 전에 먼저 군집화(clustering)에 대해 설명하겠습니다.

● 군집화(clustering)란?
지금까지 대부분의 포스팅에서는 레이벨이 있는 데이터로 분류하는 법을 설명했습니다. 그러나 실세계에서는 레이블이 없는 경우가 더 많습니다. 레이블이 없는 데이터를 가지고 데이터 안에서 패턴과 구조를 발견하는 것이 비지도 학습이고, 가장 대표적인 비지도학습 기술이 군집화입니다. 군집화가 사용되는 대표적인 분야로는 추천엔진, 검색엔진 등이 있습니다. 추천엔진에서는 사용자 경험을 개인화하기 위해 비슷한 제품끼리 묶는다던가, 검색엔진에서는 관련 주제나겸색 결과를 묶어주는 것이 이에 해당합니다.
군집화의 목표는 서로 유사한 데이터들은 같은 그룹으로 묶고, 유사하지 않는 데이터는 다른 그룹으로 분리하는 것입니다. 그렇다면 데이터는 몇개의 그룹으로 나누는게 적당하고, 이 데이터들 사이의 유사도는 어떻게 정의하는게 좋을까요? 이 두 가지를 해결할 수 있는 가장 유명한 방법이 K-Means 알고리즘입니다.
▶K-Means clustering의 원리
K는 데이터 집합에서 찾을 것으로 예상되는 그룹 수를 말합니다. Means는 각 데이터로부터 그 데이터가 속한 그룹의 중심까지의 평균거리를 의미합니다. 이 Means값을 최소화하는 것이 알고리즘의 목표입니다.
1. K 개의 임의의 중심점(centroid)을 배치합니다.
2. 각 데이터들을 가장 가까운 중심점으로 할당합니다.( 첫번째 군집을 형성합니다.)
3. 군집으로 지정된 데이터들을 기반으로 해당 군집의 중심점을 업데이트합니다.
4. 2-3단계를 수렴이 될 때까지(= 더이상 중심점이 업데이트 되지 않을 때까지) 반복합니다.
이 예제에서는 K의 값을 2로 정했습니다. 때문에 b에서 아무곳에 점 2개를 찍습니다. c에서는 각 데이터들을 두 개의 점중 더 가까운 곳으로 재배치하였습니다. d에서는 형성된 군집을 바탕으로 중심점을 업데이트 하였고, e에서는 업데이트된 중심점을 바탕으로 다시 각 데이터들의 거리를 구해 군집을 다시 할당하였습니다
▶K 값 정하기
군집화를 위해 먼저 몇개의 군집을 만들것인지를 결정해야 합니다. 그러려면 일단 "좋은 군집"에 대해 정의할 수 있어야 합니다. 만약 군집화가 잘 됐다면 같은 군집에 속한 데이터들은 가까운 거리에서 묶일 것입니다. 군집내 데이터들이 얼마나 퍼져있는지 또는 뭉쳐있는지에 대한 응집도를 inertia라고 합니다.
특정 데이터에서 k값에 변화에 따른 inertia 값을 그래프로 그려보면 위와 같습니다. k값이 증가하면 inertia 값은 감소하다가 어느정도 수준에서는 거의 일정하게됩니다. 따라서 군집수가 너무 많지 않으면서 inertia값이 작은 상태가 최선의 군집수가 됩니다. 위 그래프상에서는 3이 최적의 군집수입니다.
▶K-Means clustering의 장단점
- 장점 : 구현이 쉬우며, 레이블이 필요하지 않습니다. 새로운 데이터가 들오와 군집을 찾아야할 때 계산량이 적습니다.
- 단점 : 초기 군집수에 따라 정확도 차이가 존재합니다. 초기에 군집이 잘못 설정되면 매우 나쁜 결과를 얻게되고, 학습 후에는 군집의 변경이 불가능합니다. 또한 중심점이 이상치에 취약해 이상치 데이터를 만나면 중심점의 변동이 심해질 수 있습니다.
※ K-NN 알고리즘
여담으로, K-Means 알고리즘과 유사한 K-NN 알고리즘이라는 것도 있습니다. 둘은 모두 K개의 점을 이용하여 거리를 기반으로 구현된다는 점에서 유사합니다. 하지만 K-NN은 지도학습 알고리즘이며 분류 알고리즘입니다. 간단히 설명하자면 어떤 데이터가 주어지면 그 주변의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식입니다.
빨간 점이 주어지면 k=3인 경우 가장 가까운 데이터 3개를 참고합니다. 이때 노란점이 1개, 보라점이 2개 포함되므로 빨간점은 개수가 더 많은 보라색 클래스로 분류됩니다. k=6인 경우도 동일하게 동작합니다. 좀 더 자세한 설명은 이곳을 참고하면 좋습니다!
'AI Research > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 기초] 머신러닝 분류모델 정리 (0) | 2023.02.28 |
|---|---|
| [인공지능 기초] 나이브 베이즈 분류(Naive Bayes Classification) (0) | 2023.02.28 |
| [인공지능 기초] 서포트 벡터 머신(Support Vector Machines, SVM) (0) | 2023.02.28 |
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 2 (0) | 2023.02.28 |
| [인공지능 기초] 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression) - 1 (0) | 2023.02.28 |