이번 게시물에서는 Aritificial Neural Network(ANN)에 대해 다루도록 하겠습니다.
▶Aritificial Neural Network(ANN) : 인공 신경망
●인공 신경망이란?
: 인간의 뇌와 비슷하게 작동하여 정보를 처리하기 위한 구조를 말합니다.
● 인공 신경망의 구조
- 입력층(input layer) : 입력 정보를 받는 층
- 은닉층(hidden layer) : 입력된 정보를 해석하는 층
- 출력층(output layer) : 입력된 정보에 대한 출력을 내는 층
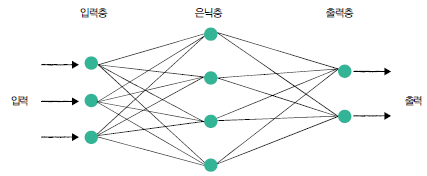
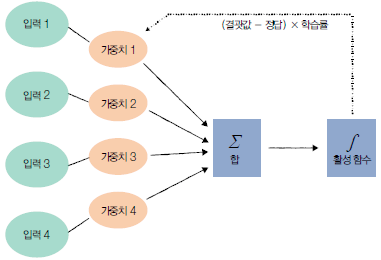
각 노드(위 그림의 동그란 것들)는 특정한 수학 연산을 실행합니다. 각 층에 존재하는 매개변수인 가중치(weight)에 행렬곱을 하고 편향(bias)을 더해주는 것입니다. 그리고 이 행렬 곱의 결과는 활성화 함수를 거쳐 인공 신경망의 결과값을 도출하게 됩니다.
=> 가중치(weight): 입력 신호가 출력에 주는 영향을 계산하는 매개변수
=> 편향(bias) : 각 노드가 얼마나 데이터에 민감한지 알려주는 매개변수, 랜덤으로 초기화하거나 사용자가 부여
=> 활성화함수(activation function) : 입력 신호(은닉층에서 계산된 결과값)의 합이 활성화를 일으키는지 아닌지를 판별하는 역할, 활성함수를 거치고 나면 0이 되는 경우도 있는데 이때는 다음 뉴런으로 전달되지 않음(즉, 다음 뉴런으로 전달할지 말지 결정)
다양한 활성화함수들입니다.

다양한 활성화함수들
=> 역전파(back propagation) : 겹겹히 쌓인 가중치를 뒤에서부터 차례대로 조정하고 최적화, 출력층의 값과 실제 값의 차이(오차)를 구한 후 이전 layer로 오차를 전파하며 각 노드가 갖고 있는 weight와 bias를 갱신하는 과정
▶간단한 분류모델 구현
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
- 라이브러리 import
import torch
import numpy # 수치해석용 라이브러리
from sklearn.datasets import make_blobs # 파이썬의 대표적인 머신러닝 라이브러리
import matplotlib.pyplot as plot # 데이터의 분포와 패턴 시각화
import torch.nn.functional as F
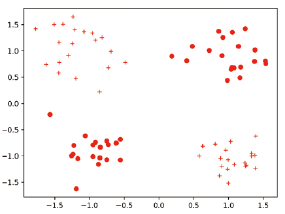
- make_blobs() 함수를 이용해 데이터를 2차원 벡터 형태로 만들어줍니다. 레이블을 생성하며, 랜덤하게 점들을 생성하여 각 점들이 몇 번째 클러스터(총 4개: 0, 1, 2, 3)에 속해있는지 알려줍니다.
n_dim = 2
x_train, y_train = make_blobs(n_samples=80, n_features=n_dim, centers=[[1,1],[-1,-1],[1,-1],[-1,1]],shuffle=True, cluster_std=0.3)
x_test, y_test = make_blobs(n_samples=20, n_features=n_dim, centers=[[1,1],[-1,-1],[1,-1],[-1,1]], shuffle=True, cluster_std=0.3)
- label_maps()함수를 통해 0~4 사이의 값을 갖던 레이블이 0 또는 1을 갖도록 바꿔줍니다.
def label_map(y_, from_, to_):
y = numpy.copy(y_)
for f in from_:
y[y_ == f] = t_
return y
y_train = label _map(y_train, [0, 1], 0)
y_train = label _map(y_train, [2, 3], 1)
y_test = label _map(y_test, [0, 1], 0)
y_test = label _map(y_test, [2, 3], 1)데이터가 모두 만들어지고, 이를 시각화해보면 아래 그림처럼 생성된 것을 확인할 수 있습니다.
- 이 데이터들을 텐서 형태로 변환해 줍니다.
x_train = torch.FloatTensor(x_train)
print(x_train.shape)
x_test = torch.FloatTensor(x_test)
y_train = torch.FloatTensor(y_train)
y_test = torch.FloatTensor(y_test)
- 분류에 사용할 간단한 신경망을 정의해줍니다. linear layer 들로만 구성된 신경망입니다.
class NeuralNet(torch.nn.Module):
def __init__(self, input _size, hidden _size):
super(NeuralNet, self).__init__()
self.input _size = input_size # 입력 데이터의 크기
self.hidden _size = hidden_size # 은닉 유닛의 수
self.linear_1 = torch.nn.Linear(self.input _size, self.hidden_size) # linear layer 정의
self.relu = torch.nn.ReLU() # 활성화함수 ReLU 선언
self.linear_2 = torch.nn.Linear(self.hidden _size, 1) # linear layer 정의
self.sigmoid = torch.nn.Sigmoid() # 활성화 함수 sigmoid 선언
def forward(self, input _tensor):
linear1 = self.linear_1(input_tensor) # 입력 데이터를 첫번째 linear layer에 넣음
relu = self.relu(linear1) # 첫번째 linear layer를 거쳐 나온 값에 relu를 적용
linear2 = self.linear_2(relu) # 활성화 함수를 거친 값을 두번째 linear layer에 넣음
output = self.sigmoid(linear2) # 두번째 linear layer를 거쳐 나온 값에 sigmoid를 적용,
# sigmoid를 거치면 0~1 사이의 값으로 바뀌게되고 입력 데이터가 0과 1중 어디에 더 가까운지 판별가능
return output
- 기타 하이퍼파라미터 정의
## 신경망 모델 생성 및 관련 변수와 알고리즘 정의
model = NeuralNet(2, 5)
learning_rate = 0.03 # 학습률 정의
criterion = torch.nn.BCELoss() # loss 함수로 Binary Cross Entropy 함수 사용
epochs = 2000 # 전체 학습데이터를 몇번이나 반복해서 학습할지
optimizer = torch.optim.SGD( model.parameters(), lr = learning_rate)
# optimizer 설정, Stochastic Grdient Descent 사용)
# step()함수를 부를 때마다 가중치를 학습률만큼 갱신, model.parameter()함수로 추출한 모델 내의 가중치, 학습률을 입력
- 학습전 모델 성능 평가
model.eval()
test_loss_before = criterion(model(x_test).squeeze(), y_test)
print('Before Training, test loss is {}'.format(test_loss_before.item()))
- 신경망 학습
for epoch in range(epochs):# Epoch만큼 도는 함수
model.train() # 신경망을 학습 모드로 전환 (test 시에는 model.eval())
optimizer.zero_grad() # 매 epoch마다 기울기를 새로 계산하기 때문에 epoch시작시 0으로 설정
train_output = model(x_train) # 데이터를 모델로 보내 결과값을 계산, 자동으로 forward함수로 들어감
train_loss = criterion(train_output.squeeze(), y_train) # 모델의 결과물과 실제 정답간의 loss를 구하는 과정
if epoch % 100 == 0:
print('Train loss at {} is {}'.format(epoch, train_loss.item()))
train_loss.backward() # loss 함수를 gradient로 미분해서 오차가 최소가 되는 방향을 알아냄
optimizer.step() # 알아낸 방향으로 모델을 학습률만큼 이동, 역전파
- 학습된 가중치 저장
state_dict() : 가중치들을 dict 형태로 저장할 수 있도록 해주는 함수
torch.save(model.state_dict(), './model.pt')
print('state_dict format of the model: {}'.format(model.state_dict()))
- 저장된 가중치를 불러와 새로운 모델에 적용(전이 학습)
new_model = NeuralNet(2, 5)
new_model.load_state_dict(torch.load('./model.pt'))
new_model.eval()
print('벡터 [-1, 1]이 레이블 1을 가질 확률은 {}'.format(new_model(torch.FloatTensor([-1,1])).item()))'AI Research > Deep Learning' 카테고리의 다른 글
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(Deep CNN) (0) | 2023.03.01 |
|---|---|
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(CNN의 기초) (0) | 2023.03.01 |
| [Pytorch-기초강의] 패션 아이템을 구분하는 DNN (1) | 2023.03.01 |
| [Pytorch-기초강의] 파이토치로 구현하는 ANN (텐서와 autograd) (0) | 2023.03.01 |
| [Pytorch-기초강의] 1. 딥러닝과 파이토치 (0) | 2023.03.01 |