이번 게시물에서는 이전 시간보다 더 깊게 신경망을 쌓아 Fashion MNIST 데이터셋을 분류해보도록 하겠습니다!
▶ Fashion MNIST 데이터셋
- 28×28 픽셀의 흑백 이미지
- 총 70,000장 으로 구성됨 (train set : test set = 60,000 : 10,000)
- 신발, 드레스, 가방을 포함하여 총 10개의 카테고리로 구성 (T-shirt/Top, Troser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, Ankle boot)
- torchvision에서 데이터셋을 자동으로 다운받고 학습 데이터를 나누는 일까지 해주기 때문에 편리하게 사용 가능


●코드 설명
- 필요한 모듈 import
from torchvision import datasets, transforms, utils
from torch.utils import data
import matplotlib.pyplot as plt
import numpy as np●torch.utils.data : 데이터셋의 표준을 정의하고 데이터셋을 불러오고 자르고 섞는 데 쓰는 도구들이 들어있는 모듈, 모델을 학습시키기 위한 데이터셋의 표준을 torch.utils.data.Dataset에 정의
● torchvision.datasets : 이미지 데이터셋의 모음, 패션 아이템 데이터셋이 들어있는 모듈
● torchvision.transfoms : 이미지 데이터셋에 쓸 수 있는 여러 가지 변환 필터를 담고 있는 모듈(이미지=>텐서로 변환, 크기 조절(resize ), 크롭(crop), 밝기(brightness ), 대비(contrast) 등을 조절)
● torchvision.utils : 이미지 데이터를 저장하고 시각화하기 위한 도구가 들어있는 모듈
- 이미지=>텐서 변경, 학습 및 실험데이터 설정
torchvision.datasets로 생성된 객체는 파이토치 내부 클래스 ‘torch.utils.data.Dataset’을 상속하는데, 그러므로 파이토치의 ‘DataLoader’, 즉 데이터셋을 로딩하는 클래스에 넣어 바로 사용 가능합니다. ‘DataLoader’는 데이터셋을 배치(batch)라는 작은 단위로 쪼개고 학습 시 반복문 안에서 데이터를 공급할 수 있도록 합니다.
transform = transforms.Compose([ ## 이미지를 텐서로 변경
transforms.ToTensor()
])
trainset = datasets.FashionMNIST( # download를 True로 설정하여 데이터셋 다운로드
root = './.data/',
train = True, # True이면 학습데이터, False이면 실험데이터
download = True,
transform = transform
)
testset = datasets.FashionMNIST(
root = './.data/',
train = False,
download = True,
transform = transform
)
- 데이터로더 설정하기
batch_size = 16 # 반복마다 이미지를 16개씩 읽음
train_loader = data.DataLoader( # 위의 데이터를 넣어주어 편리하게 데이터를 뽑아쓸 수 있음
dataset = trainset,
batch_size = batch_size # 설정해준 batch size만큼 가져옴
)
test_loader = data.DataLoader(
dataset = testset,
batch_size = batch_size
)
dataiter = iter(train _loader) # 반복문에 사용할 수 있도록 함
images, labels = next(dataiter) # 배치 1개 가져오기
● 인공 신경망으로 패션 아이템 분류하기
신경망을 여러개 쌓아 데이터 집합을 분류해보겠습니다.
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
- 필요한 모듈을 import하고, epoch과 batch를 설정합니다.
import torch
import torch.nn as nn
import torch.optim as optim # optimizer 설정위해 필요
import torch.nn.functional as F # nn모듈의 함수버전
from torchvision import transforms, datasets
USE_CUDA = torch.cuda.is_available() # CUDA 사용 가능 여부 확인
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
EPOCHS = 30 # 전체 데이터 셋 반복 횟수
BATCH_SIZE = 64 # 모델에 한번에 입력으로 주어지는 데이터셋의 수- 데이터셋을 다운받고 dataloader를 사용하는 방법은 위와 동일합니다.
- 신경망 설계 : 3개의 fc layer로 구성해주었습니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x첫번째 fc layer의 입력 유닛 수가 784인 이유는=> 입력 x 는 [배치크기, 색, 높이, 넓이]로 이루어져 있습니다. x.size()를 해보면 [64, 1, 28, 28]이라고 표시되는 것을 보실 수 있습니다.(흑백이기 때문에 색은1, 컬러이미지인 경우 RGB로 3) 이미지의 크기는 28 x 28입니다. 그러므로 입력 x의 총 특성값 갯수는 28 x 28 x 1, 즉 784개 입니다.
가장 마지막 layer인 fc3의 output size는 10인데 분류해야할 클래스의 수가 총 10개이기 때문입니다.
- 모델 선언과 optimizer, 학습률 설정
model = Net().to(DEVICE) # 모델 선언
optimizer = optim.SGD(model.parameters(), lr=0.01)- 학습하기
def train(model, train_loader, optimizer):
model.train() # 모델을 학습 모드로 전환(<-> model.eval())
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE) # 학습 데이터를 DEVICE의 메모리로 보냄
optimizer.zero_grad() # 1 epoch마다 기울기 계산위해 zero grad 호출
output = model(data) # model로부터 나온 output받음
loss = F.cross_entropy(output, target) # loss계산( cross entropy 사용)
loss.backward() # 오차 역전파, 기울기 계산
optimizer.step() # 가중치 수정
▶ 과적합과 드롭아웃
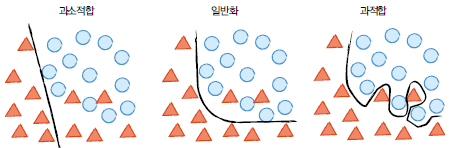
● 과적합(overfitting) 이란?
신경망이 학습 데이터에만 너무 잘 학습되어, 테스트 데이터에서는 좋지 않은 성능을 보이는 현상
● 과소적합(underfitting)이란?
학습데이터도 제대로 학습하지 못한 경우
● 일반화(Generalization)란?
학습 데이터와 학습하지 않은 실제 데이터에서 동시에 높은 성능을 내는 상태
학습 데이터셋만 이용해서 학습하면 오차는 무한정 내려갈 수밖에 없습니다.(과도한 반복학습으로 학습데이터에만 잘 하게 됨) 실제로 학습을 멈추지 않고 계속 진행해보면 학습 성능은 계속 좋아지지만, 검증/테스트 성능이 오히려 떨어지는 것을 확인할 수 있습니다. 따라서 학습 중간중간 검증용 데이터셋으로 모델이 학습 데이터에만 과적합되지 않았는지 확인할 필요가 있습니다.
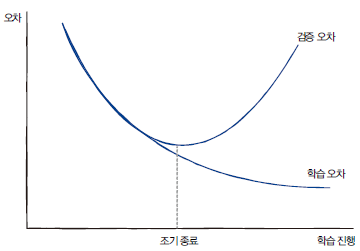
검증용 데이터셋(validation set)을 이용해서 검증 데이터셋에 대한 성능이 나빠지면 학습을 종료해주면 됩니다.
●과적합을 방지하려면?
1. 데이터 늘리기 : 이미 가지 데이터 내에서 최대한 수를 늘려야합니다.이를 data augmentation이라고 합니다. 이미지를 자르기, 돌리기, 노이즈 더하기, 생상 변경 등의 방법이 있습니다
2. 드롭아웃(drop out) : 학습 진행 과정에서 신경망의 일부를 사용하지 않는 방법입니다. (예를 들어 50% 드롭아웃이면 학습 단계마다 절반의 뉴런만 사용합니다.) => 학습에서 배재된 뉴런 외에 다
른 뉴런들에 가중치를 분산시키고 개별 뉴런이 특징에 고정되는 현상을 방지하는기능을 합니다.
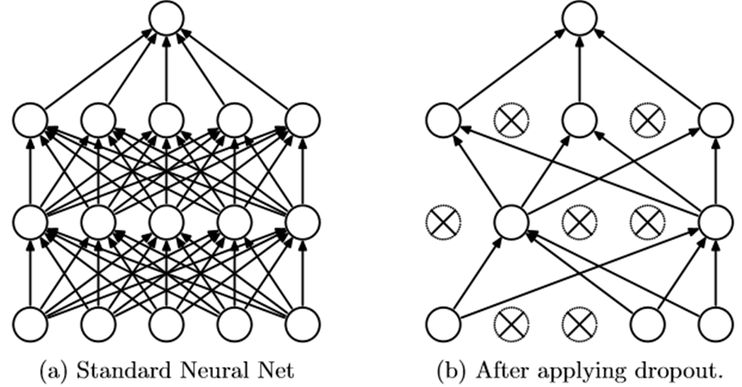
드롭아웃의 사용법은 아래와 같습니다. forward에서 드롭아웃의 비율도 함께 설정해주고 값을 넣어주면됩니다.
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.fc1(x))
x = F.dropout(x, training = self.training, p=0.2) # 학습시 20퍼센트의 뉴런은 사용하지 않음
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x'AI Research > Deep Learning' 카테고리의 다른 글
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(Deep CNN) (0) | 2023.03.01 |
|---|---|
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(CNN의 기초) (0) | 2023.03.01 |
| [Pytorch-기초강의] 파이토치로 구현하는 ANN(ANN) (0) | 2023.03.01 |
| [Pytorch-기초강의] 파이토치로 구현하는 ANN (텐서와 autograd) (0) | 2023.03.01 |
| [Pytorch-기초강의] 1. 딥러닝과 파이토치 (0) | 2023.03.01 |