▶합성곱 신경망(CNN)에 대해 배우기전에 기초 개념들에 대해서 복습해보도록 하겠습니다!
● 학습이란?
신경망에서 가중치를 적절하게 조정하는 것을 말합니다.
=> 다시 말해, 모델이 정확한 output을 낼 수 있도록 적절한 가중치로 갱신하는 것입니다.
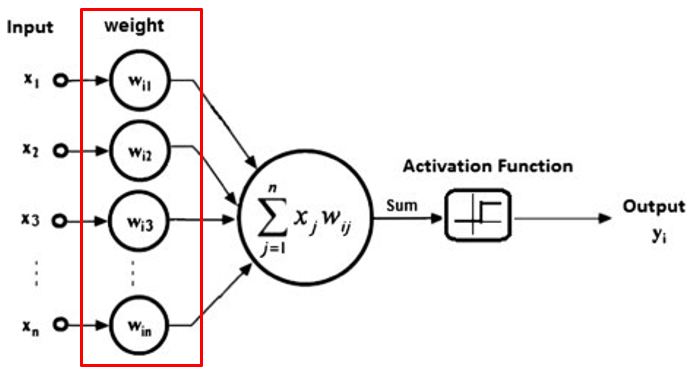
● 계층(layer)이란?
- 네트워크의 구성 요소를 말합니다.
- 특정 단위 작업을 수행
-> 함께 처리되는 뉴런들의 집합. (FC Layer, Conv Layer 등)
-> 뉴런 없이 특정 기능을 수행하는 함수. (Pooling Layer 등) : 이번 게시물에서 설명하도록 하겠습니다.
-> 경우에 따라 Activation Function도 하나의 Layer로 취급됨(개발 시에, 이들을 하나의 레이어처럼 사용하기 때문)
● 네트워크(network)란?
- 여러 Layer들로 이루어집니다.
- 네트워크의 형태에 따라 다양하게 분류됩니다.(FFN, CNN, RNN, GCN 등)
▶합성곱 신경망(CNN) 기초
- 컴퓨터가 보는 이미지
픽셀 값들을 가로, 세로로 나열

이런 이미지들은 가장 간단한 FC layer로 학습을 시킨다면 이미지를 일렬로 펼쳐서 모델의 입력으로 주게 되는데, 이때 여러 문제점이 발생하게됩니다.
1. 이미지의 연속적인 지역적 특징 추출 불가
2. 인접 픽셀들간의 상관관계 무시됨
3. 중요 정보 손실
4. 과도한 연산량
5. 다양한 형태의 입력에 대한 확장성이 떨어짐(특징 값을 추출하는 가중치가 영상의 가운데에만 집중하도록 학습)

● 컨볼루션의 목적
- 계층적으로 이미지의 특징(feature)을 추출하는것=>계층적으로 인식 가능하게 함(윤곽선, 질감, 털 ...)
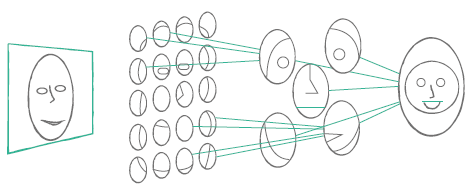
- 각 단계에서 이미지에 다양한 필터(filter 또는 kernel)를 적용하여 각종 feature 추출 (초록색: feature map , 노란색: 필터)
=> Feature map * 필터 값 = 신규 feature map => 곱하고 더하는 과정 반복

● CNN 모델
- 컨볼루션 계층(convolution layer), 풀링 계층(pooling layer)로 구성
=> 합성 곱(Convolution) 연산을 수행하는 뉴런들로 구성
=> 컨볼루션 계층은 이미지 특징 추출,
=> 풀링 계층은 필터를 거친 여러 특징 중 가장 중요한 특징 하나를 골라냄( 덜 중요한 특징은 버리기 때문에 이미지 차원 감소)

- 필터 : 컨볼루션 계층 하나에 여러개 존재 가능(보통 3*3 또는, 5*5)
=> 이 필터 행렬 값( = 가중치)이 특징을 잘 뽑을 수 있도록 학습되는 것!
=> 필터 크기, 필터 모양, 필터 개수 등 조정 가능
=> 필터마다 역할 존재(필터 1: 얼굴,필터 2: 코, 필터 3: 눈 … => 머신이 알아서 결정하는 것)
- 컨볼루션의 작동 방식 : 오른쪽 아래로 움직이며 다음 feature map 생성 (이때 몇 칸씩 움직일지 조절하는 값을 stride라고 함) => 생성된 여러 feature map은 pooling 단계로 넘어감
- 풀링(pooling) : feature map의 크기가 크면 학습이 어렵고 과적합의 위험이 증가하는데, 풀링 계층을 사용하여 이전에 추출한 특징 값을 하나로 추려내서 feature map의 크기를 줄여주고 중요 특징 강조
아래 사진은 가장 많이 쓰이는 max pooling입니다. feature map을 일정 크기의 영역으로 나누고 각 영역에서 최댓값을 뽑음( 이외에도 average pooling, min pooling등이 있음)

풀링의 사용이 과적합의 위험을 줄여주는 이유는 parameter를 줄이기 때문에, 해당 network의 표현력이 줄어들기 때문입니다.
- 패딩(padding) : 가장자리 픽셀 정보가 사라지는 것을 방지하기 위함
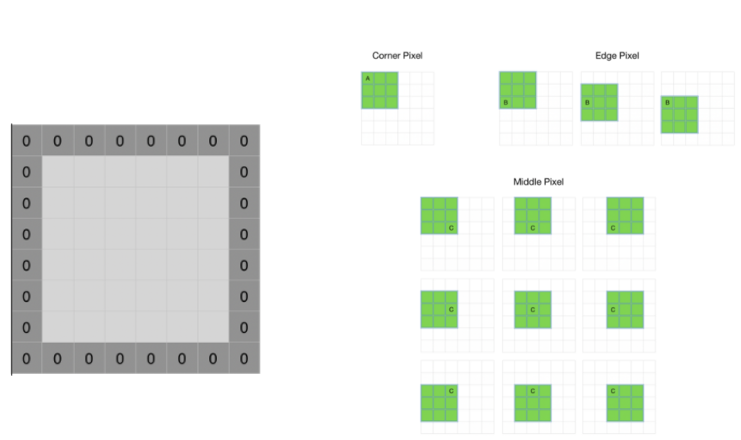
이렇게 컨볼루션 계층과 풀링 계층을 계층적으로 쌓으면 특징이 선 같은 저수준(앞 레이어)에서 고수준(뒷 레이어)으로 특징이 추출되게 됩니다.

- CNN의 장점
=> 지역적 특징 추출 가능
=> 고차원 데이터 처리 가능
=> FC보다 적은 가중치 수
=> 입출력 데이터 크기가 고정되지 않음(레이어 종류에 따라 다름)
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
● 간단 코드 설명
이전 게시물들에서 설명했던 부분은 제외하고 설명하겠습니다!
- 모델 생성
필터 크기 5*5의 2계층 모델을 구성합니다.
class CNN(nn.Module):
def __init__(self):
super(Net, self).__init__()
# nn.Conv2d(입력 채널 수, 출력 채널 수, kernel _size=필터 사이즈)
self.conv1 = nn.Conv2d(1, 10, kernel _size=5) # 10개의 feature map생성
self.conv2 = nn.Conv2d(10, 20, kernel _size=5) # 10개의 feature map을 받아 20개의 feature map 생성
self.drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50) # cnn을 거친 후 일반 신경망을 거치도록함
self.fc2 = nn.Linear(50, 10) # 10은 분류해야할 클래스의 수
- 입력으로부터 출력내기
cnn 계층 -> max pooling -> relu 함수 -> cnn 계층 -> max pooling -> relu 함수 순으로 진행됩니다.
def forward(self, x):
x = F.relu(F.max _pool2d(self.conv1(x), 2)) # F.max_pool2d(입력, 필터 크기)
x = F.relu(F.max _pool2d(self.conv2(x), 2))
x = x.view(-1, 320) # 모양 변경
x = F.relu(self.fc1(x)) # 완전 연결 계층
x = self.drop(x) # 드롭아웃 적용
x = self.fc2(x) # 0부터 9까지의 레이블을 갖는 10개의 출력값
return F.log_softmax(x, dim=1)
- 학습을 시작합니다.
def train(model, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data) # 모델로 데이터를 보냄
loss = F.cross_entropy(output, target) # 손실함수로 cross entropy 사용
loss.backward()
optimizer.step()
if batch_idx % 200 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
'AI Research > Deep Learning' 카테고리의 다른 글
| [Pytorch-기초강의] 사람의 지도 없이 학습하는 오토인코더 (0) | 2023.03.01 |
|---|---|
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(Deep CNN) (0) | 2023.03.01 |
| [Pytorch-기초강의] 패션 아이템을 구분하는 DNN (1) | 2023.03.01 |
| [Pytorch-기초강의] 파이토치로 구현하는 ANN(ANN) (0) | 2023.03.01 |
| [Pytorch-기초강의] 파이토치로 구현하는 ANN (텐서와 autograd) (0) | 2023.03.01 |