▶ 오토인코더 기초
● 오토인코더(Auto-Encoder)란?
레이블 없이 feature를 추출하는 신경망을 말합니다. 지금까지의 신경망들은 입력값에 정답이 포함된 supervised learning(지도학습)이었습니다. 이번 챕터에서 소개하는 오토인코더는 입력값만으로 학습하는 unsupervised learning(비지도학습)신경망입니다.
- 특징1: 비지도학습에선 정답이 없기 때문에 오찻값을 구하기가 모호합니다 => ‘정답이 있으면 오차값을 구할 수 있다’ 는 생각에서 출발하여 x를 입력받아 x를 예측하고, 신경망에 의미 있는 정보가 쌓이도록 설계된 신경망이 바로 오토인코더입니다. (입력된 x를 복원한다는 의미로 생각하면 됩니다.)
따라서, 오차값에도 x를 얼마나 복원했는지를 의미하는 복원오차 또는 정보 손실값이라는 용어를 사용합니다.

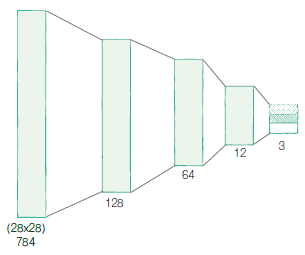
- 특징2: 오토인코더는 입력과 출력의 크기는 같지만, 중간으로 갈수록 신경망의 차원이 줄어듭니다. 이런 구조로 인해 정보의 통로가 줄어들고 병목현상(bottleneck)이 일어나 입력의 특징들이 압축됩니다. 압축된 표현을 잠재변수라고 하고, 보통 z로 표기합니다. z를 기준으로 앞쪽은 인코더(encoder, 정보를 압축) , 뒷쪽은 디코더(decoder, 압축된 정보를 풀어 복원)라고 합니다.
● 압축된 데이터 z : z에 이미지의 정보가 저장 => 복잡한 데이터의 의미를 담을 수 있다는 점에서 중요합니다. 덜 중요한 요소는 버리고 중요한 정보만 압축하기 때문입니다. 압축과정에서는 필연적으로 정보의 손실이 일어나는데, 원본의 디테일을 어느정도 잃는다는 단점도 있지만, 중요 정보만 남긴다는 점에서 필요한 과정입니다.
=> 이러한 특징으로 인해, 오토인코더는 주로 복잡한 비선현 데이터의 차원을 줄이기 위해 사용합니다.
▶ 오토인코더로 이미지의 특징 추출하기
- Fashion MNIST 데이터셋을 이용합니다.
● 간단 코드 설명
이전 게시물들에서 설명한 부분은 제외하고 설명하겠습니다.
- 오토인코더의 인코더 모듈을 정의합니다.
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential( # 여러 모듈을 하나로 묶어줌
nn.Linear(28*28, 128), # 28 × 28, 784개의 차원으로 시작
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 12),
nn.ReLU(),
# 입력의 특징을 3차원으로 압축(특징을 3개만 남김 => 이 부분을 통해 나온것이 잠재변수 z에 해당
nn.Linear(12, 3),
)
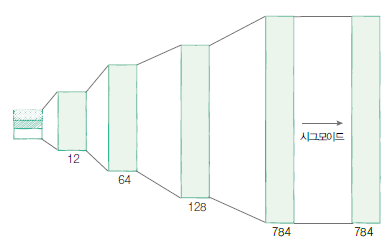
- 오토인코더의 디코더 모듈을 정의합니다.
self.decoder = nn.Sequential( # 3차원의 잠재 변수를 받아 다시 784차원의 이미지로 복원
# 출력 차원이 점점 증가
nn.Linear(3, 12),
nn.ReLU(),
nn.Linear(12, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 픽셀당 0과 1 사이로 값을 출력
)
- 모델로 데이터를 입력해줍니다.
=> 인코더(self.encoder)는 잠재 변수인 encoded를 만들고, 디코더 (self.decoder )는 복원 이미지인 decoded를 생성합니다.
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
- 모델, optimizer(Adam 사용) , loss function(MSELoss, 평균제곱오차) 을 정의합니다.
autoencoder = Autoencoder().to(DEVICE)
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.005)
criterion = nn.MSELoss() # source와 target의 차이에 제곱해서 평균을 구해줌
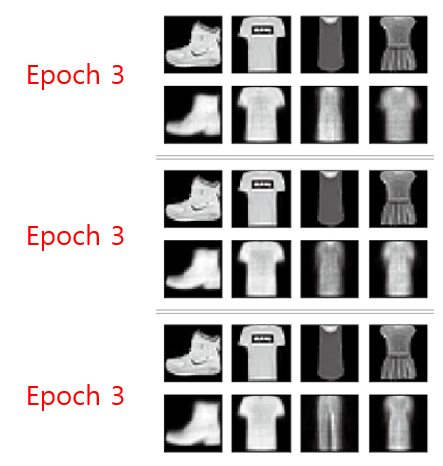
- 학습 중간중간 복원된 이미지를 확인해보면 다음과 같습니다.
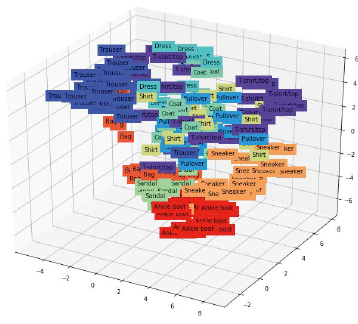
- 또한, 오토인코더 모델이 학습이 잘 됐다면, 같은 라벨들 끼리는 비슷한 위치에 시각화되어야 합니다.
아래 그림을 통해, 동일하게 잠재 변수 안에서 비슷한 특징이 모이는 결과를 확인할수 있습니다.
▶ 오토인코더로 망가진 이미지 복원하기(denoising autoencoder)
=> 중요한 특징을 추출하는 오토인코더 특성을 이용하여 비교적 ‘덜 중요한 데이터’인 noise를 제거하는 방향으로 학습되도록 설계합니다.
전체 코드 주소입니다!
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
- 이미지에 노이즈를 더해줍니다.
=> 노이즈는 랜덤하게 주기위해 torch.randn( ) 함수를 이용합니다. 입력에 이미지의 크기(img.size ( ) )를 넣어 이미지와같은 크기의 노이즈를 만들고 노이즈와 이미지를 더해주면 됩니다. 노이즈의 세기는 0.2로 정했습니다.
def add_noise(img):
noise = torch.randn(img.size()) * 0.2
noisy_img = img + noise
return noisy_img
- 오토인코더 모델은 위의 설명한 것과 동일합니다.
- 학습 결과를 시각화하면 다음과 같습니다.

'AI Research > Deep Learning' 카테고리의 다른 글
| [Pytorch-기초강의] 딥러닝을 해킹하는 적대적 공격 (0) | 2023.03.03 |
|---|---|
| [Pytorch-기초강의] 순차적인 데이터를 처리하는 RNN (0) | 2023.03.03 |
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(Deep CNN) (0) | 2023.03.01 |
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(CNN의 기초) (0) | 2023.03.01 |
| [Pytorch-기초강의] 패션 아이템을 구분하는 DNN (1) | 2023.03.01 |