▶ RNN 개요
● "I live to eat"과 "I eat to live"는 모두 같은 단어로 이루어져 있으나 뜻은 완전 다릅니다. 이전 게시물들에서 배운 단어의 feature만 잡아내는 일반적인 신경망들로는 이 변화를 인식하기가 힘듭니다. RNN은 이처럼 데이터의 순서가 주는 정보까지 인지해내기 위해 등장한 신경망입니다.
● 이전에 포스팅했던 CNN은 시간의 개념이 없는 정적인 데이터만을 다룹니다. 하지만 실세계에 존재하는 것들은 모두 연속적, 순차적(sequential)으로 일어납니다. 이러한 데이터를 "시계열 데이터(time series data)"라고 합니다.
● RNN이 내는 출력은 순차적인 데이터의 흐름을 모두 내포합니다. RNN의 구조는 아래와 같습니다. 그림에서 X는 입력을, h는 은닉벡터(hidden vector)를 나타냅니다.
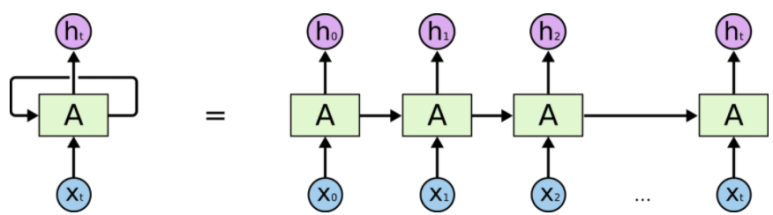
RNN 구조도
데이터의 정보를 하나씩 입력받을 때마다 지금까지 입력된 벡터들을 종합해 은닉 벡터를 만들어냅니다. 첫 번째 데이터 x0을 입력받은 RNN은 h0을 생성합니다. x0에 이어 x1까지 RNN에 입력되면 x0과 x1를 압축한 h1이 만들어지는 방식입니다. 이렇게 생성된 최종 벡터 h는 배열 속 모든 벡터들의 내용을 압축한 벡터라고 할 수 있습니다.
● RNN계열의 신경망들 : LSTM(long short term memory), GRU(gated recurrent unit)
● RNN을 응용한 신경망들
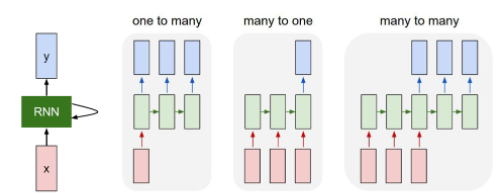
- one to many : 이미지를 보고 이미지 안의 상황을 글로 설명하는 task에 사용
- many to one : 감정 분석 같이 순차적인 데이터를 보고 값 하나를 내는 task에 사용
- many to many : 챗봇과 기계 번역 같이 순차적인 데이터를 보고 순차적인 데이터를 출력하는 task에 사용
▶ RNN을 이용한 영화 리뷰 감정 분석
- 사용 데이터셋 : 텍스트 형태의 데이터셋인 IMDB => 약 5만개로 구성, 각 리뷰는 다수의 영어 문장으로 구성되었으며, 긍정적인 영화 리뷰는 2로, 부정적인 영화 리뷰는 1로 레이블링
전체 코드 주소입니다!
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
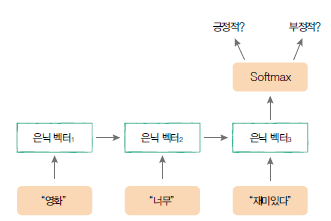
이 예제에서 만들고자하는 모델은 아래와 같은 구조를 갖습니다.
또한, 이미지가 아닌 텍스트를 다루기 때문에, 토크나이징(tokenizing)과 워드 임베딩(word embedding)이 필요합니다.
- 토크나이징(tokenizing): 언어의 최소 단위인 토큰으로 나누는 것
- 워드 임베딩(word embedding) : 언어의 최소 단위인 토큰을 벡터 형태로 변환하는 작업
● 간단 코드 설명
이전 게시물과 동일한 부분은 제외하고 설명하겠습니다.
- 필요 라이브러리 import
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext import data, datasets # 텍스트를 다루기 위해 필요한 라이브러리
- 데이터셋 로딩하고 텐서로 변환하기
=> sequential 파라미터를 이용해 데이터셋이 순차적인 데이터셋인지 명시해줍니다.
=> batch _first 파라미터로 신경망에 입력되는 텐서의 첫 번째 차원값이 batch_size가 되도록 정해줍니다.
=> lower 변수를 이용해 텍스트 데이터 속 모든 영문 알파벳이 소문자가 되도록 처리합니다.
TEXT = data.Field(sequential=True, batch_first=True, lower=True)
LABEL = data.Field(sequential=False, batch_first=True)
trainset, testset = datasets.IMDB.splits(TEXT, LABEL)
- 만들어진 데이터셋을 이용해 워드 임베딩에 필요한 단어 사전 생성
=> min_freq는 학습 데이터에서 최소 5번 이상 등장한 단어만을 사전에 담는 것을 의미합니다..
TEXT.build_vocab(trainset, min_freq=5)
LABEL.build_vocab(trainset)
- 사전속 단어들의 수와 레이블의 수정해주기
vocab _size = len(TEXT.vocab)
n _classes = 2
- RNN 모델 구현하기
=> nn.Embedding : 첫 번째 파라미터(n_vocab)는 전체 데이터셋의 모든 단어를 사전 형태로 나타냈을때, 그 사전에 등재된 단어 수이고, 두 번째 파라미터(embed_dim)는 임베 딩된 단어 텐서가 지니는 차원값입니다..
=> nn.GRU : RNN이 문장의 뒷부분에 다 다를수록 앞부분의 정보가 소실되는 문제점을 해결하기 위해 GRU를 사용했습니다.(기본적인 RNN은 입력이 길어지면 학습 도중 기울기가 너무 작아지거나 커져서 앞부분에 대한 정보를 정확히 담지 못하는 문제가 발생할 수도 있습니다.)

class BasicGRU(nn.Module):
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2):
super(BasicGRU, self).__init__()
print("Building Basic GRU model...")
self.n_layers = n_layers # 은닉 벡터들의 층 정의
self.embed = nn.Embedding(n_vocab, embed_dim)
self.hidden_dim = hidden_dim # 은닉벡트의 차원 값
self.dropout = nn.Dropout(dropout_p) # 드롭 아웃
self.gru = nn.GRU(embed_dim, self.hidden_dim,
num_layers=self.n_layers,
batch_first=True)
self.out = nn.Linear(self.hidden_dim, n_classes) # 클래스 예측
- forward 함수 구현
1. 모델에 입력되는 데이터 x는 한 배치 속에 있는 모든 영화평인데, 이 영화평들을 embed( ) 함수로 워드 임베딩하면 아래처럼 벡터로 변환됩니다.
2. 입력 x를 첫 번째 은닉 벡터 h0과 함께 self.gru( ) 함수에 입력하면 은닉 벡터들이 시계열 배열 형태로 반환됩니다.
3. self.gru( ) 함수가 반환한 텐서를 [:,-1,:]로 인덱싱하면 배치 내 모든 시계열 은닉 벡터들의 마지막 토큰들을 내포한 (batch_size, 1, hidden_dim) 모양의 텐서를 추출 가능합니다.
def forward(self, x):
x = self.embed(x)
h_0 = self._init_state(batch_size=x.size(0))
x, _ = self.gru(x, h_0) # [i, b, h]
h_t = x[:,-1,:] # 영화 리뷰 배열들을 압축한 은닉 벡터
self.dropout(h_t)
logit = self.out(h_t) # [b, h] -> [b, o], 결과 출력
return logit
# 첫 번째 은닉벡터 H0을 정의해 x와 함께 입력해주기 위해 필요한 함수
def _init_state(self, batch_size=1):
weight = next(self.parameters()).data # nn.GRU 모듈의 첫 번째 가중치 텐서를 추출
# new( ) 함수를 호출해 모델의 가중치와 같은 모양을 갖춘 텐서로
# 변환한 후 zero_ ( ) 함수를 호출해 텐서 내 모든 값을 0으로 초기화
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_()
▶ Seq2Seq 기계 번역
●언어를 다른 언어로 해석해주는 모델입니다.(번역기) 시퀀스를 입력받아 또 다른 시퀀스를 출력합니다.
● 서로 다른 역할을 하는 두 개의 RNN을 이어붙인 구조입니다. (앞쪽의 RNN은 인코더 역할을 하여 번역할 문장을 이해하고, 뒤 쪽의 RNN은 디코더 역할을 하여 번역문을 작성합니다.) 아래 그림은 Seq2Seq의 구조도입니다.
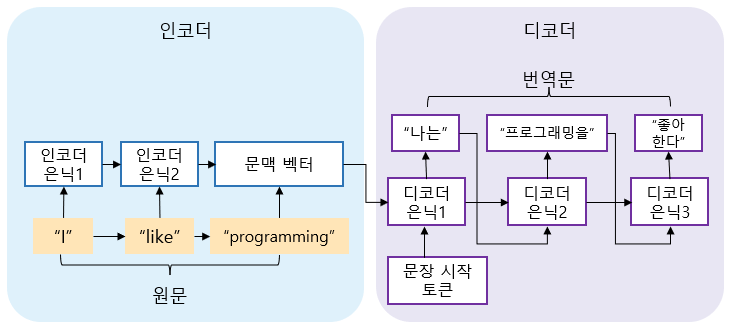
여기서, 문장 시작 토큰은 실제로 문장에는 나타나지는 않지만, 디코더가 정상적으로 작동할 수 있도록 인위적으로 넣은 토큰입니다.
● 인코더
- 원문의 내용을 학습하는 RNN => 원문 속의 모든 단어를 입력받아 문장의 뜻을 내포하는 하나의 고정 크기 텐서를 만들어냅니다. 이렇게 압축된 텐서는 원문의 뜻과 내용 모두를 압축하여 "문맥 벡터(context vector)"라고 합니다.
● 디코더
- 인코더에게서 원문 문맥벡터를 받아 번역문 속의 토큰을 차례대로 예측합니다.
▶ Seq2Seq 모델 구현하기
- 간단하게 문장이 아닌 단어를 번역하는 모델을 구현해보겠습니다.
=> 간단한 영단어 “hello”를 스페인어 “hola”로 번역하는 작업을 구현합니다.
전체 코드 주소입니다!
GitHub - jgyy4775/3-min-pytorch: <펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드
<펭귄브로의 3분 딥러닝, 파이토치맛> 예제 코드. Contribute to jgyy4775/3-min-pytorch development by creating an account on GitHub.
github.com
- 모델 클래스 정의
class Seq2Seq(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(Seq2Seq, self).__init__()
self.n_layers = 1
self.hidden_size = hidden_size # 임베딩된 토큰의 차원값으로 정의
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.encoder = nn.GRU(hidden_size, hidden_size) # 인코더를 GRU로 정의
self.decoder = nn.GRU(hidden_size, hidden_size) # 디코더를 GRU로 정의
self.project = nn.Linear(hidden_size, vocab_size) # 디코더가 번역문의 다음 토큰을 예상하는 신경망
- forward 함수 구현
=> 인코더 : 첫 번째 은닉 벡터를 정의하고 인코더에 입력되는 원문 “hello”를 구성하는 모든 문자를 임베딩합니다.
=> 디코더 : 문장 시작 토큰인 아스키 번호 0을 이용해 번역문 “hola”의 ‘h’ 토큰을 예측했으면 다음 반복에선 ‘h’ 토큰을 이용해 ‘o’ 토큰을 예측해야 합니다.
def forward(self, inputs, targets):
# 인코더에 들어갈 입력
initial_state = self._init_state()
embedding = self.embedding(inputs).unsqueeze(1)
# embedding = [seq_len, batch_size, embedding_size]
# 인코더 (Encoder), 문맥 벡터인 encoder_state를 생성
encoder_output, encoder_state = self.encoder(embedding, initial_state)
# encoder_output = [seq_len, batch_size, hidden_size]
# encoder_state = [n_layers, seq_len, hidden_size]
# 디코더에 들어갈 입력
# 번역문의 첫 번째 토큰을 예상하려면 인코더의 문맥 벡터와 문장 시작 토큰을 입력 데이터로 받아야 함
decoder_state = encoder_state # encoder_state를 디코더의 첫 번째 은닉 벡터 decoder_state로 지정
decoder_input = torch.LongTensor([0]) # 문장 시작 토큰 '0', 의미 없는 공백 문자
# 디코더 (Decoder)
outputs = []
for i in range(targets.size()[0]):
# 첫 번째 토큰과 인코더의 문맥 벡터를 동시에 입력
decoder_input = self.embedding(decoder_input).unsqueeze(1)
decoder_output, decoder_state = self.decoder(decoder_input, decoder_state)
# 디코더의 출력 값으로 다음 글자 예측하기
projection = self.project(decoder_output)
outputs.append(projection)
#티처 포싱(Teacher Forcing) 사용
decoder_input = torch.LongTensor([targets[i]])
outputs = torch.stack(outputs).squeeze()
return outputs
* 티처 포싱(Teacher Forcing)이란 ?
학습이 아직 되지 않은 상태의 모델은 잘못된 예측 토큰을 입력으로 사용할 확률이 높습니다. 만약 반복해서 잘못된 입력 토큰이 사용되면 학습이 더뎌지는데, 디코더 학습 시 실제 번역문의 토큰을 디코더의 전 출력값 대신 입력으로 사용해 학습을 가속하는 방법입니다. 이 예제에서는 번역문의 i번째 토큰에 해당하는 값targets[i]를 디코더의 입력값으로 설정합니다.
'AI Research > Deep Learning' 카테고리의 다른 글
| [Pytorch-기초강의] 경쟁하며 학습하는 GAN (0) | 2023.03.03 |
|---|---|
| [Pytorch-기초강의] 딥러닝을 해킹하는 적대적 공격 (0) | 2023.03.03 |
| [Pytorch-기초강의] 사람의 지도 없이 학습하는 오토인코더 (0) | 2023.03.01 |
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(Deep CNN) (0) | 2023.03.01 |
| [Pytorch-기초강의] 이미지 처리 능력이 탁월한 CNN(CNN의 기초) (0) | 2023.03.01 |