이번 포스팅에서는 분류와 회귀에 사용되는 평가 지표들에 대해 설명하겠습니다!
▶Classification Metrics
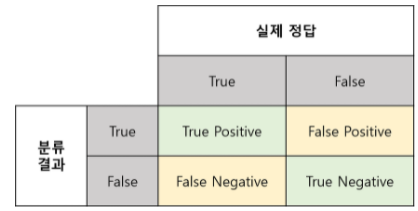
Classification Metrics에서 가장 중요한 개념은 Confusion Matrix입니다. 이는 모델의 예측과 실제 결과를 비교하여 나타낸 표를 말합니다. 가로행은 모델의 예측된 결과를, 세로열은 실제 결과를 의미합니다.
True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
Positive/Negative는 그렇다/아니다로 판별, True/False는 판단이 올바르다/틀렸다로 기억하면 쉽습니다.
예시를 통해 설명해보겠습니다.
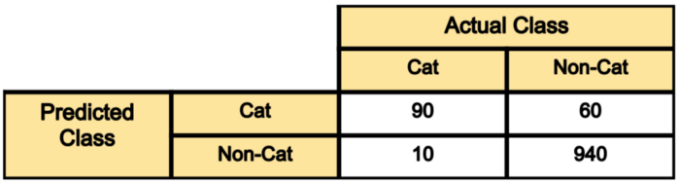
전체 100장의 사진 중 model은 90장을 정확히 판단했고 나머지 10장은 잘못 판단한 것입니다.
True Positive(TP) : 100장의 고양이 사진 중 90장만 고양이라고 판단
False Positive(FP) : 1000장의 고양이가 아닌 사진 중 60장을 고양이라고 판단
False Negative(FN) : 10장의 고양이 사진을 고양이가 아니라고 판단
True Negative(TN) : 1000장의 고양이가 아닌 사진 중 940장을 고양이가 아니라고 판단
- Accuracy(정확도)

정확도는 가장 직관적으로 모델의 성능을 나타내는 지표입니다. True를 True라고 예측한 경우, False를 False라고 옳게 예측한 경우 모두 고려하는 지표입니다. 위 예시에서 Accuracy를 계산해본다면,
Accuracy=(90+940) / (1000+10) = 93.6%
- Precision(정밀도)
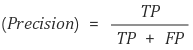
정밀도는 모델이 True라고 분류한 것중 실제 True인 것의 비율을 나타냅니다. Accuracy보다 좀 더 구체화된 평가 지표입니다. 위의 예시에서 Precision을 계산해본다면,
# cat을 기준으로 측정한다면
Precision = 90 / (90+60) = 60%
# non-cat을 기준으로 측정한다면
Precision = 940 / 950 = 98.9%
- Recall(재현율)

재현율은 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율입니다. hit rate라고 불리기도 합니다. Precision과 Recall은 모두 실제 True인 정답을 모델이 True라고 예측한 경우에 관심을 두지만 관점이 다릅니다. Precision은 모델의 관점에서, Recall은 실제 정답의 관점에서 바라보는 것입니다. Precision과 Recall은 상호 보완적으로 사용할 수 있고, 두 지표가 모두 높게 계산되었다면 좋은 모델이라고 할 수 있습니다. 위의 예시에서 Recall을 계산해본다면,
# cat을 기준으로 측정한다면
Recall = 90 / 100 = 90%
# non-cat을 기준으로 측정한다면
Recall= 940 / 1000 = 94%
-F1-Score
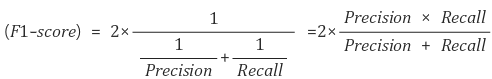
Precision과 Recall의 조화 평균입니다. 데이터 레이블이 불균형 할 때 모델의 성능을 정확하게 평가할 수 있습니다.
- Fall-out
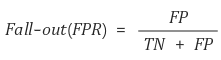
FPR(False Positice Rate)라고도 불립니다. 실제 False 중에서 모델이 True라고 예측한 비율을 의미합니다. 즉, 잘못 예측한 것의 비율을 의미합니다.위의 예시에서 Recall을 계산해본다면,
- ROC(Receiver Operating Characteristic)
Recall과 Fall-out의 변화를 시각화 한것입니다. 두 지표에 대해 다시 설명하면, Recall은 실제 True중에서 모델이 True로 분류한 것이고, Fall-out은 실제 False중에서 True로 분류한 비율을 나타냅니다.현재 분류기의 성능은 고정하고 가능한 모든 임계값 별 recall과 fall-out의 비율을 알아내 그래프로 그린 것입니다. 두 지표를 각각 x, y축에 두고 그래프를 그려보면 아래처럼 그려집니다.
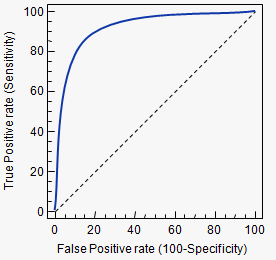
커브 모양으로 그려지는데, 커브가 왼쪽 위 모서리와 가까울수록, 그리고 y=x그래프 보다 위에 있을수록 모델이 성능이 좋은 것입니다. 즉, Recall이 크고, Fall-out이 작은 것이 좋은 모델인 것입니다. ROC 커브는 이진 분류에 많이 쓰입니다. 좀 더 자세한 설명은 이곳을 참조해주세요!
-AUC(Area Under Curve)
AUC는 ROC 그래프의 아래 면접값을 의미합니다. ROC는 그래프 형태이기 때문에 정확한 수치값을 비교하기 어려워 이런 방법을 사용하는 것입니다. 최댓값은 1이며, 1에 가까울수록 좋은 모델입니다.
▶ Regression Metrics
회귀에서는 예측값과 실제값의 오차가 얼만큼 되는지를 평가 지표로 사용합니다.
- MSE(Mean Squared Error)
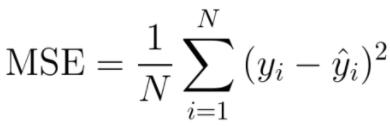
평균 오차 제곱합이라고도 하며, 예측값과 실제값의 차이를 제곱한뒤 평균을 낸 값입니다. 0에 가까울수록 좋은 성능을 의미합니다.
- RMSE(Root Mean Squared Error)
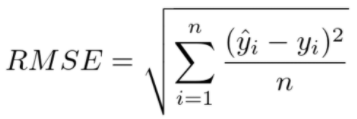
MSE에 루트를 씌운 것으로 MSE가 제곱 때문에 오차 값이 커지는 것을 보정해줍니다. 회귀에서 대표적인 평가지표로 사용됩니다. 0에 가까울수록 좋은 성능을 의미합니다.
- RMSLE(Root Mean Squared Log Error)

MSE의 각 인자에 로그를 씌운 값입니다. 연속적인 값의 분포가 한쪽으로 치우쳐졌거나 정규분포를 따르지 않는 불균형한 모양일 때 사용되는 방법입니다. 이상치에 크게 영향을 받지 않는 지표입니다. 0에 가까울수록 좋은 성능을 의미합니다.
- MAE(Mean Absolute Error)
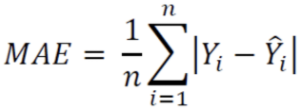
예측값과 실제값의 차이에 절댓값을 씌워 합해준 것입니다.
- R2(R-Squared)
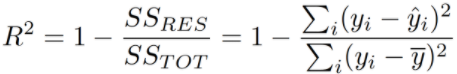
총 제곱합에 대한 회귀제곱합을 의미하며 결정계수라고도 합니다. 1에 가까울수록 좋은 성능을 나타냅니다.
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] 그래프 신경망(Graph Neural Network) (0) | 2023.03.04 |
|---|---|
| [딥러닝 기본지식] 가중치(weight)와 편향(bias) (0) | 2023.03.04 |
| [딥러닝 기본지식] 오차 역전파(backpropagation)의 이해 - 계산그래프와 연쇄법칙(chain rule) (1) | 2023.03.04 |
| [딥러닝 기본지식] 최적화 함수(optimizer)의 이해 - 최적화 함수의 정의와 다양한 종류들 (0) | 2023.03.03 |
| [딥러닝 기본지식] 경사 하강법(Gradient Descent)의 이해 - 정의 (0) | 2023.03.03 |