<Introduction>
이 논문은 위치 정보와 자연어를 이용하여 장면 그래프를 생성하는 방법에 관한 논문입니다. 이에 대해 제안하는 방법과 기대 효과들은 다음과 같습니다.
▶ Subject물체와 object물체의 단어 임베딩을 통한 관계예측(Glove 이용)
- Image captioning등으로 미리 학습된 임베딩값 사용
- 자주 등장하는 관계를 통해 자주 등장하지 않는 관계 예측 가능
- EX) 자주 등장(person-ride-horse) / 자주 등장하지 않는(person-ride-elephant)
- => horse와 elephant는 모두 animal 범주에 속하므로 비슷한 임베딩 값을 가짐
그러므로, horse를 통해 elephant도 ride라는 관계를 가질 수 있음을 예측
가능
▶ 이러한 정보들을 임베딩하기 위해 Bi-directional recurrent neural network(BiRNN)을 사용
<Model>

1. Object detection
CNN을 거쳐 각 탐지된 영역들의 feature추출
2. Object Pair Generation
Subject와 object feature: 초기 예측된 class 분포
spatial information: 두 물체의 bbox의 중심 좌표, 넓이, 높이 이용
3. Object Pair Feature Initialization
object, subject word vector: 2에서 예측된 분포 중 가장 높은 class의 word vector사용
relative spatial feature: 2의 spatial information을 이용한 feature
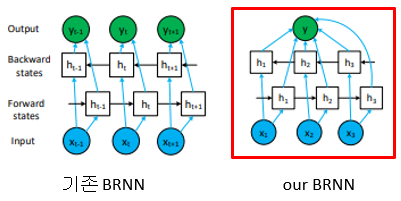
BRNN을 사용함으로써 <person-ride-horse>와 <horse-ride-person>이 다름을 학습하며 아래 그림처럼 주어와 목적어 물체가 같아도 다른 관계를 가질 수 있음을 학습

- 기존 BRNN
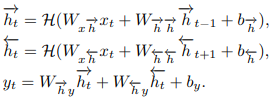
- Our BRNN
주어와 목적어 물체의 정보 이용
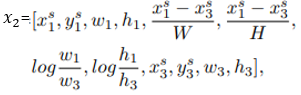
최종 output y
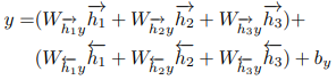
4. Natural language guided relationship recognition
Subject-predicate-object사이의 RNN을 이용한 정보 공유
5. Joint recognition
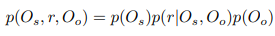
<Result>
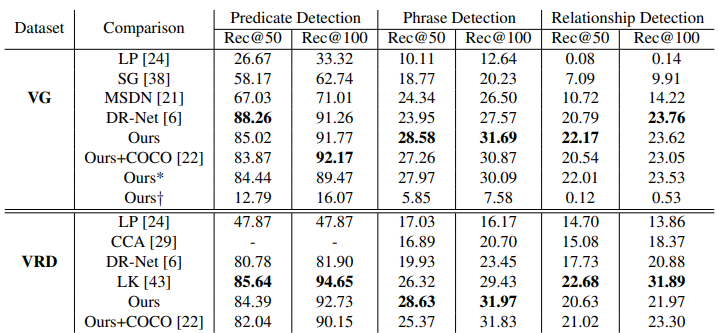
Dataset
- Visual Genome
- VRD
Metrics
- Predicate detection: relation만 예측
- Phrase detection: object class와 relation예측
- Relationship detection: 물체의 영역, class, relation 모두 예측
<결론>
- 이미지에서 시각 관계를 탐지하기 위한 자연어 지식 기반 방법을 제시
- 이 자연어 지식과 spatial 정보를 기반으로 탐지된 물체 사이의 관계를 예측하기 위해 BRNN 모델을 설계했
= > 특히, 롱테일 문제(데이터 불균형 문제)를 처리하는 데 있어 자주 등장하는 관계 인스턴스에서 자주 등장하지 않는 관계를 추론 가능하게 함.