Github : https://github.com/nexusapoorvacus/DeepVariationStructuredRL
<Introduction>
이 논문은 강화학습을 이용하여 scene graph 생성하는 모델인 "Deep variation-structured Reinforcement Learning(VRL)"를 제안한 논문입니다. 또한, 관계만 예측하던 다른 연구들과는 다르게 물체의 속성도 함께 예측합니다.

▶강화학습 알고리즘 중 하나인 Deep Q-Learning을 사용하여 장면 그래프를 생성합니다.
=> 주어 물체의 속성 예측(color, shape, pose)
=> 목적어 물체 예측 (people, places, parts of objects.)
=> 주어 물체와 목적어 물체의 관계 예측 (spatial,compositional, action)
▶효과적인 state vector추출법 제안
<Model>
1) Object Detection
- Faster R-CNN 이용
- S: object instance
-각 object의 confidence score-> 초기 정보들을 바탕으로 relation과 attribute 분류
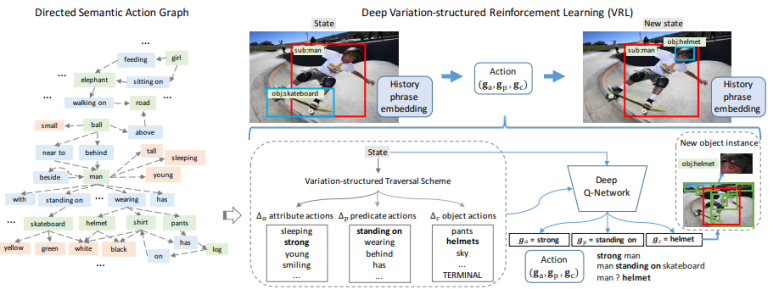
2) Directed Semantic Action Graph
데이터 집합으로 부터 가능한 물체의 클래스, 집합, 관계들을 미리 사전에 저장하여 그래프로 생성한 것
3) Variation-structured RL
-Variation-structured action space.
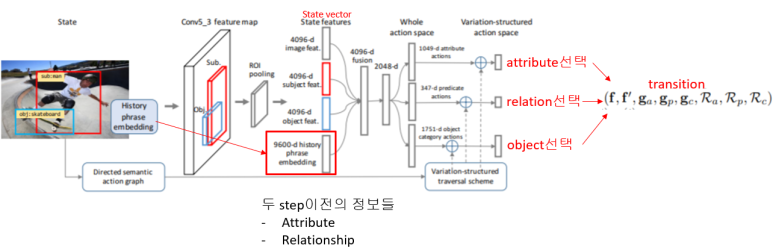
- Q-Learning 사용
앞서 추출된 attribute, relation, object를 이용해 Q-learning

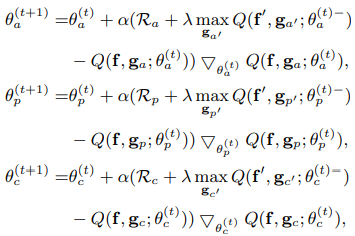
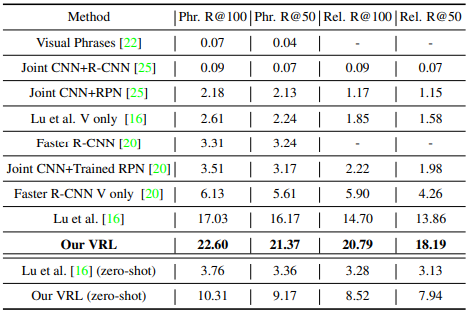
<Result>
Dataset
- Visual Genome
- VRD
Metrics
- Predicate detection: relation만 예측
- Phrase detection: object class와 relation예측
- Attribute detection

<결론>
- 강화 학습을 이용한 장면 그래프 생성 방법 제안
- 물체, 관계 뿐만 아니라 속성까지 함께 탐지하는 모델 제안