<Introduction>
이 논문은 video feature 추출을 위한 I3D라는 모델을 제안합니다. 또한 이를 위해 행위인식에 많이 쓰이는 Kinect dataset을 제안한 논문이기도 합니다. Kinect 데이터 집합이 등장하게된 배경을 좀 더 자세하게 설명하자면,
=> 이미지 분류 task에 가장 많이 사용되는 imagenet 데이터 셋을 이용하는 모델들을 매우 큰 데이터셋으로 사전 학습(pre-training)하게되면 다른 도메인에 확정하여 적용하는데 굉장히 많은 도움 될 수 있습니다. 이는 네트워크 구조 바뀌어도 도움될 수 있다고 논문에서 설명하고 있습니다. 그렇기 때문에 매우 큰 비디오 데이터셋이 있다면 사전 학습으로 퍼포먼스 높일 수 있지 않을까라는 의문에서 시작하여 kinetics라는 매우 큰 비디오 데이터셋을 만들게 됩니다.
=> 본 논문에서는 제안하는 I3D모델을 소개할 뿐만 아니라, 이전에 행위인식에서 사용하던 방법 또한 정리하였습니다.
<Model>
이전까지의 행위 인식 모델들은 ...
- 2차원 CNN vs 3차원 CNN => 2D를 사용한다면 frame 단위로 feature를 추출하여 어떻게 aggregation할 것인지
- Only RGB vs RGB + optical flow
크게 이렇게 나눌 수 있었습니다.
그럼, (a)모델부터 (e)모델까지 차례대로 설명하겠습니다.
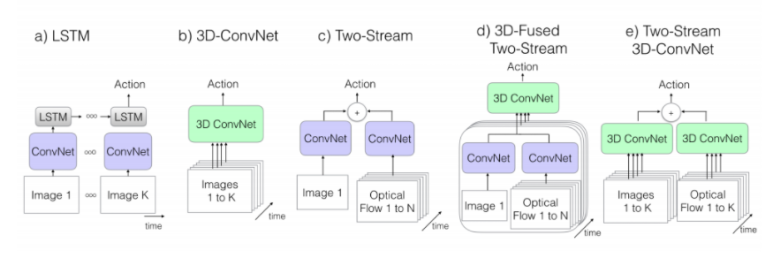
(a) ConvNet + LSTM
● 2D ConvNet 사용 => frame마다 Convolution 연산
● Aggregation 방법
- LSTM을 통과한 결과물을 pooling 방법으로 aggregation함
- LSTM을 통해 temporal 정보를 얻고자 함
● 낮은 수준의 motion 정보 얻기 힘들다는 단점 존재.
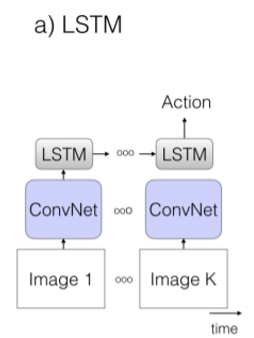
(b) 3D-ConvNet
● 비디오를 이해하기 위해 3D 사용
● I3D등장 전까지 video task에서 가장 많이 사용하던 CNN
● Spatial + temoral feature 모두 추출 가능
● 기존 2D에서 시간축을 추가하여 dimension 확장
● 학습해야할 parameter가 많은 단점
- 연산량 매우 많음
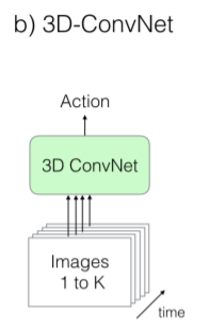
(c) Two-Stream
● Optical flow를 적용하여 two-stream으로 설계
● 각 frame에 2d ConvNet 적용 + optical flow
● Frame으로 부터 spatial정보를, optical flow로 부터 temporal 정보를 얻음
● 연산량이 적음
● 꽤 높은 정확도
※ Optical - Flow(광학 흐름)란?
-영상 내 물체의 움직임 패턴
-픽셀 자체의 움직임을 고려한 정보
-이전 프레임과 다음 프레임 사이의 픽셀이 이동한 방향과 거리 분포

(d) 3D-Fused Two Stream
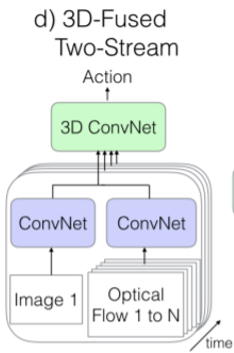
● (3)의 방법에 3D ConvNet 추가
● 매우 복잡한 연산
● 그러나, 3의 방법과 성능면에서는 큰 차이가 존재하지 않음
(e) Two – Stream Inflated 3D-ConvNet (I3D)
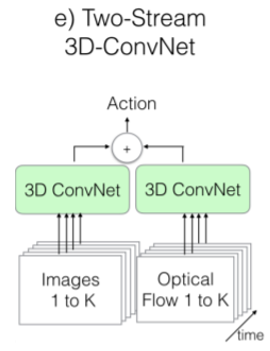
● 3D ConvNet 사용
● RGB stream에서 temporal feature 추출 가능
● Inflating 2D ConvNet into 3D
- 기존의 image classification에서 잘 학습된 2D CNN 모델을 3D CNN으로 확장하여 이용
: N * N => N * N * N 으로 확장
● Bootstrapping 3D filters from 2D filters
- 3D filter는 2D filter에 시간축을 추가한 것
=> 2D filter의 weight 값을 3D filter의 시간축을 따라 복사
● Pacing receptive field growth in space, time and network depth
- Video의 특성상 인접한 frame끼리 유사하기 때문에 frame마다 독립적이라고 보지 않음
- pooling이나 cnn에서 temporal stride를 얼마로 줄 것인지가 매우 중요
=> 실험을 통해 temporal pooling을 수행하지 않는 것이 더 나았음을 확인
(temporal 정보가 손실되지 않기 때문에)
● Two 3D Streams
- RGB와 optical flow모두 사용
<Kinetics Dataset>
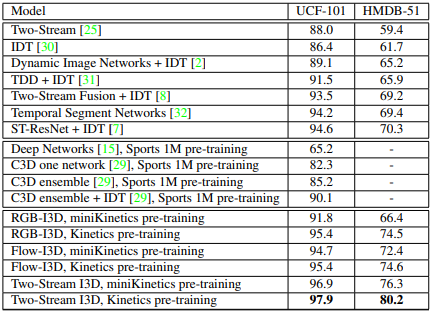
기존의 action recognition 문제에서 가장 많이 사용하던 UCF101 과 HMDB51 같은 데이터셋은 규모가 작았습니다. 이처럼 규모가 작은 데이터셋은 좋은 성능을 내기 어려웠습니다. Introduction에서 설명했듯이 ImageNet처럼 action recognition에도 규모가 큰 데이터셋의 필요성을 느끼고 Kinetics 데이터셋을 만든것입니다. Kinetics 데이터셋은 인간 action에 중점을 둔 데이터 집합으로 Drawing, drinking, laughing 등을 포함한 400개의 클래스가 존재하며, 한 클래스당 400개가 넘는 영상이 존재하는 빅데이터 셋입니다.(현재는 더 확장되어 클래스 700 버전도 존재합니다.) Kinetics 데이터셋을 학습시킨 parameter로 transfer learning을 진행하여 UCF101 과 HMDB51 과 같은 작은 규모의 데이터셋에서도 각각 HMDB51에서는 80.9% UCF101에서는 97.9%로 이전 연구들에서보다 훨씬 좋은 성능을 냈습니다.
'Paper Review > etc' 카테고리의 다른 글
| [6] MobileOne: An Improved One millisecond Mobile Backbone (0) | 2023.08.06 |
|---|---|
| [5] VanillaNet: the Power of Minimalism inDeep Learning (1) | 2023.06.25 |
| [4] ElasticFace: Elastic Margin Loss for Deep Face Recognition (1) | 2023.06.15 |
| [3] ArcFace: Additive Angular Margin Loss for DeepFace Recognition (1) | 2023.05.29 |
| [2] Deep High-Resolution Representation Learning for Human Pose Estimation (0) | 2023.03.09 |