논문 링크 : https://arxiv.org/pdf/1902.09212.pdf
Github : https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
GitHub - leoxiaobin/deep-high-resolution-net.pytorch: The project is an official implementation of our CVPR2019 paper "Deep High
The project is an official implementation of our CVPR2019 paper "Deep High-Resolution Representation Learning for Human Pose Estimation" - GitHub - leoxiaobin/deep-high-resolution-net.pyt...
github.com
<Introduction>
[Human Pose Estimation Task]

- 사람의 특정 pose 에 대한 관절이나 신체 부분을 예측하는 분야
=> 어깨, 팔꿈치 , 무릎 등 (key points)의 (X, Y)좌표 예측(= key points Localization)
Top down vs Bottom up
- Top down: human detection key points detection => pose 추정
- Bottom up: key points detection => key points 관계 분석 => pose 추정
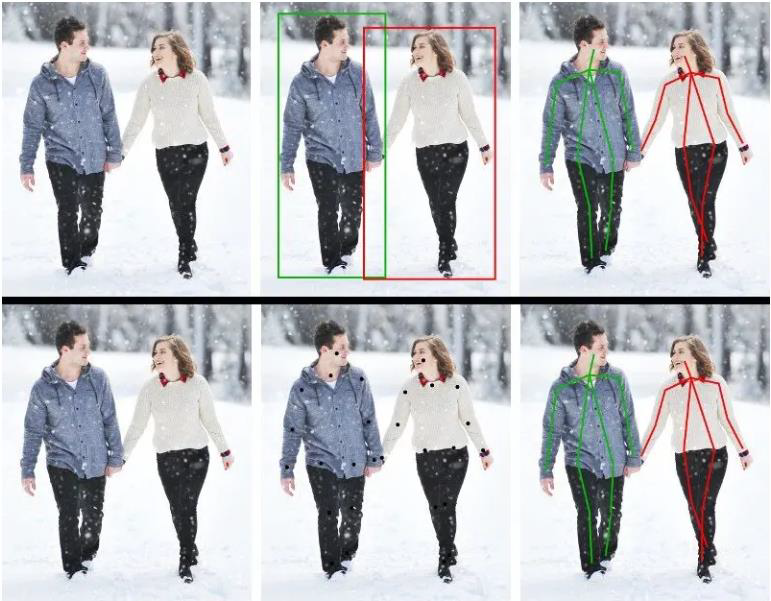
Direct Regression vs Heatmap Regression
- Direct Regression
=> CNNRegressor 를 통해 key points 들의 좌표 값 추정
=> Key points들이 비 선형적이고 적합한 매핑이 어려워 큰 성능 향상을 이루지 못함
- Heatmap Regression
=> Output을 좌표 대신 heatmap 을 이용해 상대적인 확률 값을 취할 수 있게 함
=> 입력 이미지의 다양한 pose 들을 잘 포용하고 Robust 한 모델을 가능하게 함
=> Direct Regression 보다 2 배 이상 높은 성능

[Previous Methods]
High to low low to high framework(sequential subnetwork)
=> 기존의 네트워크들은 high resolution feature로 부터 low resolution feature를 생성하고, 다시 high resolution으로 복구하는 직렬 구조
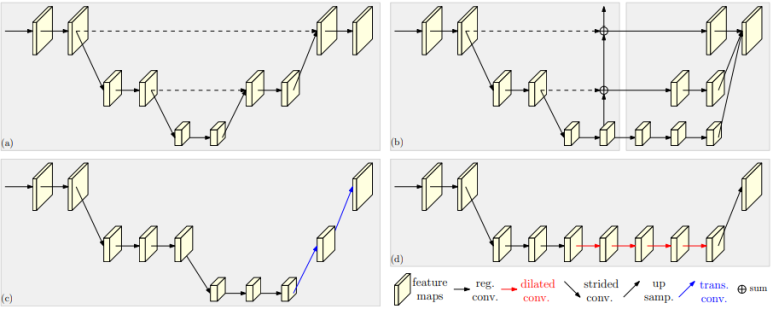
(a): 대칭적인 구조 / (b): bilinear upsampling / (c): Transpose convolution / (d): dilated convolution
(b, c, d) : high to low(heavy), low to high(light)
(a, b) : feature fusion 을 위해 skip connection 적용
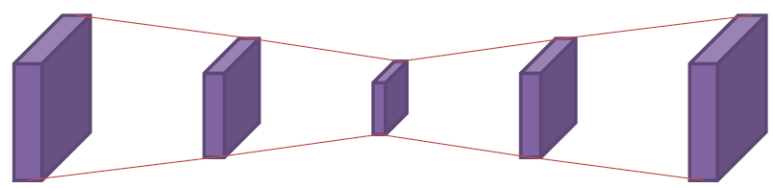
- High to Low : strided convolution, pooling
- Low to High : up-sampling, transposed convolution, dilated convolution
- Feature 추출과 학습이 직렬로 구성되어 있어 up-sampling에 의존
=> 공간 정보 손실 발생
<Model>
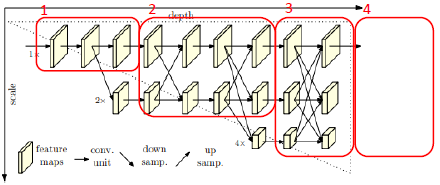
[Approach]
- 직렬구조에서 벗어나 병렬 구조로 subnetwork 구성 (parallel
- Multi scale resolution 유지 , subnetwork 사이의 적절한 fusion
=> 다양한 수준의 공간 정보 학습
- 상단의 high resolution 유지
=> 최종적으로 예측된 heatmap에 한번도 downsample/upsample되지 않은 input해상도 feature map이 영향을 주기 때문에 global, local 정보 학습을 가능하게되어 훨씬 정확
[Parallel multi resolution subnetworks]
- 4개의 stage 로 구성
- 𝑁𝑠𝑟: subnetwork, s: stage, r: resolution index
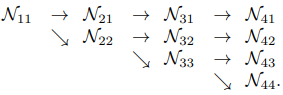
- 하나의 stage 내 두 개 이상의 resolution index
=> Stage 1: 하나의 resolution 유지
=> Stage 2-4: multi scale 간 fusion, resolution scale 을 확장 축소하는 transition
[Repeated multi scale fusion (Exchange Unit)]
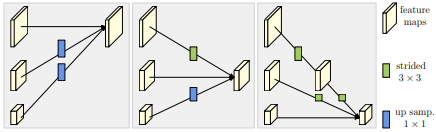
- multi scale fusion을 위해서는 존재하는 대부분의 기법은 low-level and high-level representation을 더하는 방식을 사용
- 병렬 subnetwork 간의 정보 전달
- 서로 다른 resolution fusion 시 적절한 up/down sampling 필요
- 동일한 깊이 , 유사한 수준의 low/high resolution 의 도움을 받음
- Ex) stage 3 를 여러 블록으로 나눈 그래프(𝐶𝑠𝑟𝑏: b(block index), s(stage), r(resolution index),
ε : exchange unit)
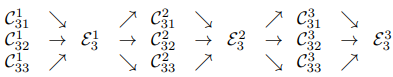
[Heatmap estimation]
- Stage 4 에서 원본 이미지 shape 에 맞게 up sampling
- Ground truth : 2D Gaussian 분포 heatmap
- Loss function: Mean Squared Error(MSE)
<Experiments>
[Dataset]
1. COCO Keypoint Dataset
- 17 keypoints
- 200K images, 250K person instances
- Metrics: OKS(Object Keypoint Similarity), AP
2. MPII Human Pose Dataset
- 16 keypoints
- 25K images, 40K subjects
- Metrics: PCKh (head normalized probability of correct keypoint)
[Metrics]
- OKS(Object Keypoint Similarity)
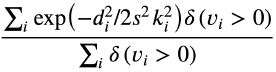
𝑑𝑖: GT 관절과 예측관절의 유클리디안 거리
𝑣𝑖: visibility flag(0: 존재하지 않는 키포인트, 1: 이미지에 존재하지만 보이지는 않는 키포인트, 2: 이미지에 존재하고 겉으로도 보이는 키 포인트)
s: bounding box 의 대각선 길이
𝑘𝑖: 관절 마다 사전 설정된 상수 값
2. PCKh (head normalized probability of correct keypoint)
- Keypoint의 추정 좌표와 정답 좌표의 거리가 임계값 보다 작다면 옳게 판단한 것으로 인정
- 인물머리 크기에 따라 결정되는 경우가 많음
- PCKh@0.5 : 머리 사이즈의 0.5 를 임계값으로 설정해 평가한 지표
[Hyper parameter]
- Optimizer: Adam
- Learning rate: 1e-3
- Epochs: 210
[실험 결과]
- COCO
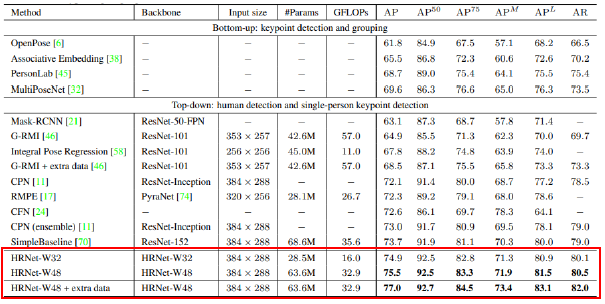
- HR-Net32: 채널수가 좀 더 적어 가볍게 학습된 모델 / HR-Net48: 채널수가 더 많은 모델
- HR-Net48에 random rotation, random scale, flipping, half body data augmentation을 이용해 데이터를 추가한 모델이 가장 높은 성능을 보임
- Bottom up 접근법 보 다 높은 정확도
- Simplebaseline 대비 더 작은 모델과 적은 연산으로 높은 성능 달성
2. MPII
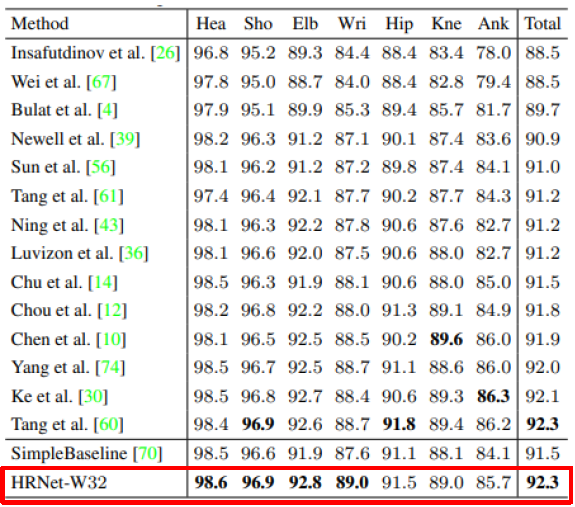
- Head, Sholder, Elbow, Wrist에 대해서 가장 높은 점수를 보임.
- total 점수 또한 제안하는 HR-Net이 가장 높음
[Ablation Study]
- Fusion이 일어나는 exchange unit 을 조절해 fusion 의 역할 실험
(a): fusion 최소화 / (b): 중간 fusion 최소화 / (c): HR-Net

=> Fusion이 늘어날 때마다 성능이 증가는 것을 바탕으로 fusion의 중요성을 알 수 있음
2. Representation 의 resolution 에 따른 모델 성능 비교 실험
- 다양한 resolution 의 heatmap 각각의 성능 실험
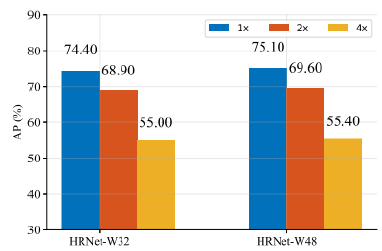
=> Resolution이 커질수록 성능이 높아지는 것을 알 수 있음
- Input size 에 따른 모델 성능 실험
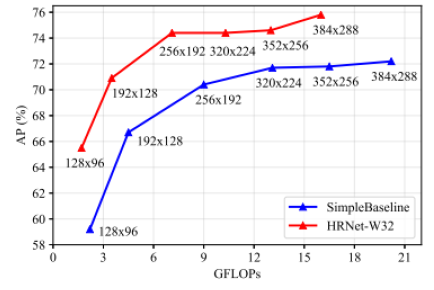
=> Input size가 작을수록 큰 성능 향상이 일어나는 것을 알 수 있음
<Conclusion>
- High resolution을 전체 프로세스에서 유지
- 다양한 resolution 의 representation 을 반복하여 fusion
=> Reliable한 high resolution representation 획득
- Pose tracking 등의 vision task 에서도 높은 성능을 보임
'Paper Review > etc' 카테고리의 다른 글
| [6] MobileOne: An Improved One millisecond Mobile Backbone (0) | 2023.08.06 |
|---|---|
| [5] VanillaNet: the Power of Minimalism inDeep Learning (1) | 2023.06.25 |
| [4] ElasticFace: Elastic Margin Loss for Deep Face Recognition (1) | 2023.06.15 |
| [3] ArcFace: Additive Angular Margin Loss for DeepFace Recognition (1) | 2023.05.29 |
| [1] Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset (0) | 2023.03.09 |