이전 포스팅에서는 Transformer의 가장 핵심이라 할 수 있는 Self-Attention에 대해 설명했습니다. 이번 포스팅에서는 Transformer의 전반적인 작동 과정에 대해 알아보겠습니다.
[Github] https://github.com/huggingface/transformers
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com
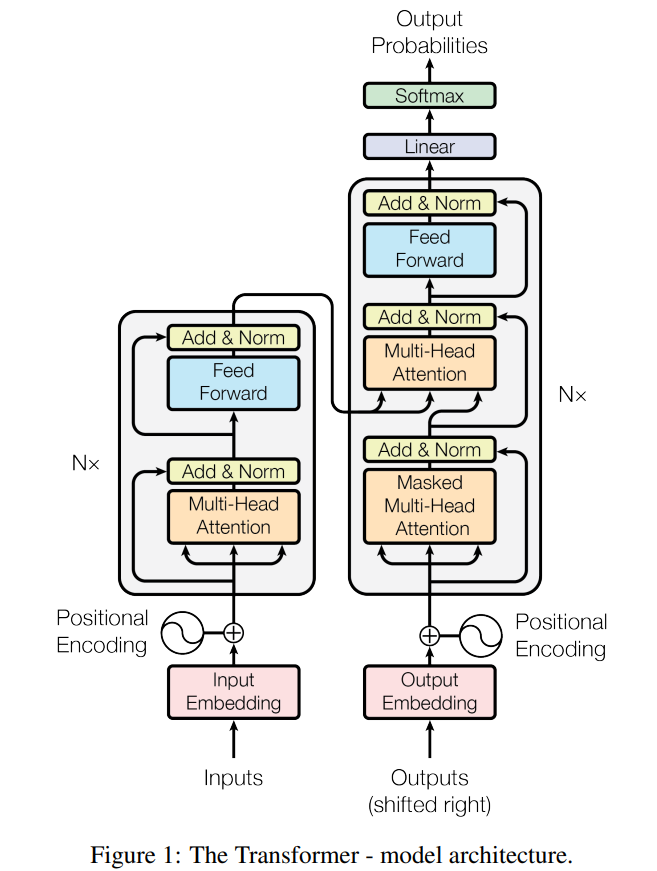
1. Padding Mask
입력 문장이 <PAD> token을 포함하는 경우 attention 과정에서 제외하기 위해 필요한 연산입니다. 아래 예제를 통해 살펴보겠습니다.

<PAD> token은 사실 "I"나 "sam" 처럼 의미를 지닌 단어는 아닙니다. 그렇기 때문에 유사도를 구할 필요도 없어 Masking을 해주는 것입니다. 즉, attention시에 연산에 포함되지 않도록 가리는 것입니다. 보통은 아주 작은 음수 값으로 채워줍니다. softmax 함수를 지나고 value 행렬과 곱해지게 되면 아주 작은 음수 값으로 채워진 masking된 부분들은 0이 되어 반영되지 않게 됩니다.
2. Position-Wise Feed Forward Neural Network (Position-Wise FFNN)
위 구조도에서 확인 할 수 있듯이 encoder와 decoder 모두에서 공통적으로 사용되는 신경망입니다. 아래는 수식입니다.

x는 multi-head attention의 결과로 나온 행렬을 의미합니다.
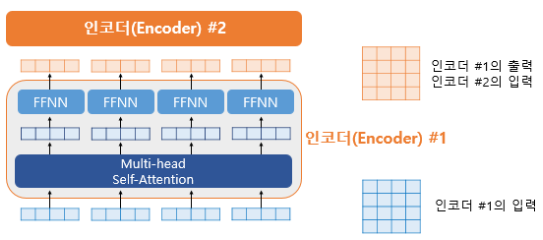
위 그림에서 encoder의 입력을 보면 각 벡터들이 multi-head attention 층을 지나 FFNN층을 통과합니다. 두 층을 통과한 후의 결과물들은 여전히 encoder의 입력 크기와 동일합니다. 그리고 다음 encoder의 입력이 됩니다. 하나의 encoder 층을 지난 행렬은 다음 encoder 층으로 전달되는 과정이 반복되는 것입니다!
3. Residual Connection & Layer Normalization
3.1 Residual Connection

Residual Connection은 ResNet에서 많이 보셨을텐데요! ResNet의 Residual Connection과 동일합니다. 서브층의 입력과 출력을 더해주는 것이죠. 아래 그림은 multi-head attention 층에서의 Residual Connection이 이루어지는 과정입니다.

3.2 Layer Normalization
Residual Connection 후에는 정규화가 진행됩니다. Layer Normalization은 입력 tensor의 마지막 차원에 대해 평균과 분산을 구하여 정규화를 하는 것입니다. 아래는 Layer Normalization을 나타내는 그림과 수식입니다.
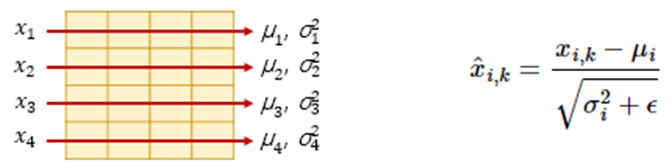
수식을 좀 더 살펴보겠습니다. 먼저 layer 별로 구한 평균과 분산을 통해 정규화 해줍니다. 입력 벡터 x_i의 차원을 k라고 했을 때 각 k차원의 값이 위와 같이 정규화 되는 것입니다. 여기서 ε은 분모가 0이 되는 것을 방지하는 값입니다. 그리고 추가로 아래 수식 처럼 γ와 β도 도입되었는데요,
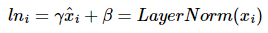
이때, γ와 β는 학습 가능한 파라미터입니다.
여기까지가 encoder의 과정입니다. 가장 위의 구조도에서 확인 할 수 있듯이 encoder의 마지막층의 출력을 decoder의 입력으로 전달합니다. decoder 또한 설정해준 갯수만큼 연산을 진행하는데, 이때마다 encoder에서 전달 된 출력 값을 각 decoder에서 사용하는 것입니다. 이제부터는 decoder에 대한 설명입니다!
4. Decoder 첫 번째 sub-layer: Self-Attention & Look-ahead Mask
encoder와 동일하게 임베딩과 positional encoding을 거친 후의 문장 행렬을 사용합니다. 그리고 decoder는 번역 해야 할 문장을 한번에 입력 받고 이 문장 행렬로 부터 각 time step의 단어를 예측해내도록 학습됩니다.
잠시 Seq2Seq 모델로 넘어가보겠습니다. Seq2Seq모델은 문장의 단어를 매 time step마다 sequential 하게 입력받기 때문에 단어 예측 시 현재 time step의 단어와 이전 time step의 단어들만 참고합니다. 하지만 문장이 한번에 들어오는 Transformer는 미래 time step의 단어까지 참고해버리게 됩니다. 이를 방지하기 위해 decoder에서는 현재 time step보다 미래에 있는 단어들은 보지 못하도록 가리는 Look-ahead Mask를 사용합니다. 아래 그림을 살펴보면 이해가 쉽습니다!

masking 후의 attention score 행렬을 보면 자기 자신보다 뒤에 있는 단어들은 가려진 것을 확인할 수 있습니다. 이 외의 과정은 일반적인 self-attention과정과 동일합니다 :)
5. Decoder 두 번째 sub-layer: Encoder-Decoder Attention
여기 층에서는 self-attention이 아닌 다른 attention이 진행됩니다. self-attention은 Query, Key , Value가 모두 같은 경우지만 Encoder-Decoder Attention은 Key와 Value는 encoder에서 넘어온 행렬입니다. 가장 위 구조도의 두 번째 서브층을 보면 encoder로 부터 두개의 화살표가 넘어오고 있습니다. 이 화살표가 의미하는 바가 바로 Value와 key입니다.

이렇게 셋팅된 Q, K, V 벡터로 attention score 행렬을 구하는 과정은 아래와 같습니다.
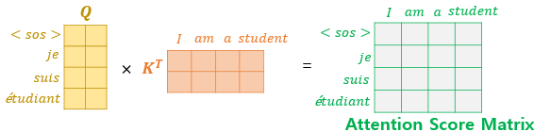
이 외의 과정은 앞서 설명한 attention과정과 동일합니다.
마지막으로 encoder와 decoder의 각 서브층에서의 Q, K, V를 정리해보겠습니다.
encoder 첫번째 서브층 : Q=K=V
decoder 첫번째 서브층 : Q=K=V
decoder 두번째 서브층 : Q => 디코더 행렬 / K=V : 인코더 행렬
여기까지 Transformer의 전반적인 작동과정입니다. 풀고자 하는 task에 맞게 loss function과 learning rate를 정의해주면 됩니다.
이 포스팅은 아래 글을 참고하여 작성하였습니다.
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] Text-to-Image의 원리(Multi-Modal AI) (1) | 2025.01.02 |
|---|---|
| [딥러닝 기본지식] Inductive Bias (1) | 2023.10.01 |
| [딥러닝 기본지식] Self Attention과 Transformer (1) (0) | 2023.08.19 |
| [딥러닝 기본지식] Auto Regressive Models (0) | 2023.05.07 |
| [딥러닝 기본지식] Diffusion Model (0) | 2023.05.01 |