이번 포스팅에서는 자연어처리 분야의 눈부신 성능 향상을 가져온 Self Attention과 Transformer에 대해 알아보겠습니다 :)
참고한 논문은 아래와 같습니다.
[Github] https://github.com/huggingface/transformers
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, a...
github.com
Self Attention과 Transformer 에 대해 설명하기에 앞서 기존에 NLP 분야에서 많이 사용하던 seq2seq 모델에 대해 간략히 설명하겠습니다.
1. Seq2Seq 모델이란 ?
Seq2Seq 모델은 input과 output이 모두 sequence인 RNN 기반의 모델입니다. 번역기를 생각하면 이해가 쉬울 것 같습니다! 아래 그림은 Seq2Seq 모델의 구조도 입니다. Seq2Seq 모델은 sequence 입력 부분과 출력 부분이 분리 된 것이 특징인 모델입니다.
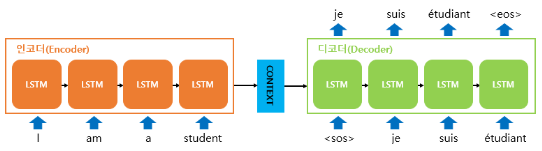
"I am a student." 라는 문장을 입력 받아 번역된 "Je suis étudiant." 문장을 출력했습니다. 인코더(Encoder)는 번역하고싶은 문장을 입력받아 문장을 구성하는 단어들의 정보를 담은 context vector를 생성하고, 디코더(Decoder)는 이 context vector를 받아 번역된 문장을 출력합니다.
Seq2Seq 모델에 많이 쓰이는 LSTM, GRU들은 이전의 input을 고려하는 것이 가능하기는 합니다. 하지만 기본적으로 RNN계열의 신경망들은 Shorter Reference Window를 가지고 있기 때문에 input이 길어지면 높은 성능을 기대하기가 어렵습니다. 이 외의 Seq2Seq 모델의 단점을 설명하면 아래와 같습니다.
- 학습시 병렬화 불가: 순차적인 input을 처리해야하기 때문에 병렬화가 불가능하고, 이로 인해 학습 시간이 과도하게 길어지게 됩니다.
- Long Distance Dependency : Reference Window의 크기가 고정이기 때문에 멀리 떨어진 token들 사이의 관계를 제대로 파악하기가 어렵습니다.
이러한 단점들을 해결하기 위해 Attention 메커니즘이 등장했습니다. 컴퓨터 성능만 따라준다면 무한한 크기의 Reference Window 를 가질 수 있고, 이를 통해 input 문장 길이에 구애받지 않고 전체적인 context를 반영할 수 있습니다. 또한 병렬화가 가능하고, Long Distance Dependency 문제도 해결 할 수 있게 되었습니다.
그럼 이제 Self-Attention에 대해 설명하겠습니다.
2. Transformer
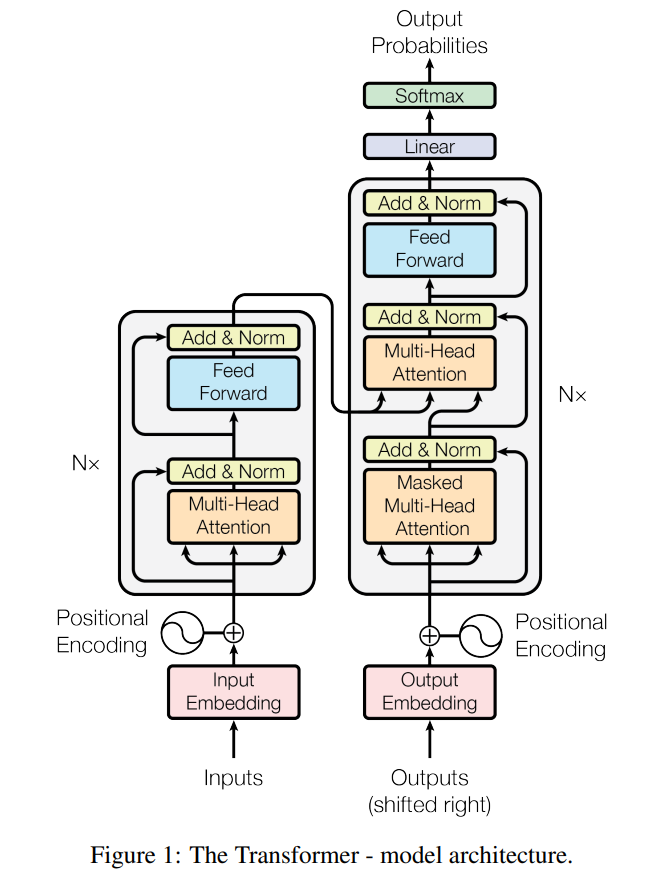
Transformer는 Seq2Seq처럼 RNN의 계열의 신경망은 아니지만, 입출력이 sequence라는 것, encoder-decoder구조를 유지하고 있다는 점에서는 Seq2Seq와 동일합니다. 다만, Seq2Seq에서는 하나의 RNN에 한 time step의 정보만 들어가고 Transformer에서는 encoder-decoder가 N로 구성되는 구조입니다. 참고한 논문에서는 6개를 사용했네요! 아래 그림처럼 구성되어 있다고 생각하시면 됩니다.

이제 Transformer의 전체적인 구조를 세세하게 살펴보겠습니다. 먼저 positional encoding입니다.
2.1 Positional Encoding
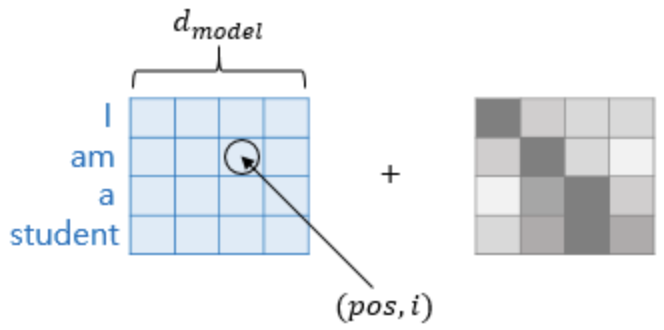
RNN의 경우에는 입력이 순차적으로 들어오기 때문에 따로 위치정보를 추가해줄 필요가 없었습니다. 하지만 Transformer의 경우는 그렇지 않기 때문에 Positional Encoding이라고 불리는 위치 정보를 담고 있는 값을 더해줘야 합니다. "I eat pizza but not eat chicken."라는 문장이 있다고 해봅시다. Positional Encoding이 없다면 Transformer에서는 앞의 eat과 뒤의 eat 은 같은 단어 벡터를 갖게 될 것입니다. 가장 많이 쓰이는 Word2Vec 가 가지는 문제점이기도 하죠. 하지만 Positional Encoding을 이용해 위치 정보를 갖게 한다면 같은 단어라 해도 위치에 따라 다른 벡터 값을 가지도록 해줄 수 있습니다. 단어 벡터에 Positional Encoding을 더해주는 과정을 그림으로 나타내면 아래와 같습니다.

이렇게 단어의 위치 정보를 성공적으로 전달하는 것입니다 :) Positional Encoding은 아래 식을 이용하여 구할 수 있습니다.
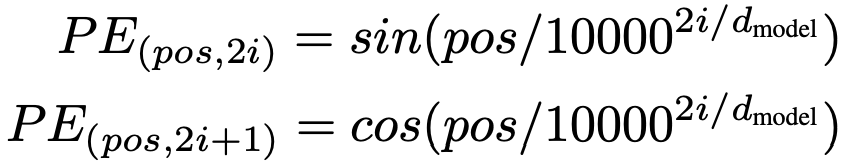
pos는 입력 문장에서 임베딩 벡터의 위치를, i는 임베딩 벡터 내의 차원의 인덱스를, d_model은 임베딩 벡터의 차원을 의미합니다.
임베딩 벡터 내의 각 차원의 index가 짝수면 sin함수를, 홀수면 cos함수를 사용하고 있습니다. 아래 그림은 위 식을 포함하여 다시 시각화 한 것입니다.
2.2 Self-Attention
이제 Self-Attention에 대해 설명하겠습니다. Transformer 에서는 아래 그림과 같이 3가지의 Attention이 사용됩니다.
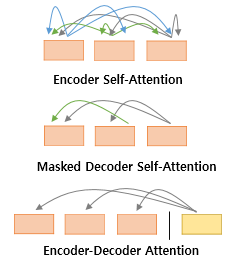
그 중 가장 핵심이 되는 Self-Attention에 대해 설명하겠습니다.
2.2.1 Query, Key, Value ?
Attention에서는 Query(Q), Key(K), Value(V)라는 값들이 존재합니다. 그 중 Self-Attention은 Query, Key, Value가 모두 동일한 경우를 말합니다.(값의 기원이 같다는 것) 이는 무엇을 의미하는 값들일까요? 모르는 내용을 인터넷에 검색하는 경우를 생각해보겠습니다. 검색하고 싶은 단어가 Query, 검색 후 타이틀로 나오는 것이 Key, 그 안의 내용이 Value입니다. Query와 가장 유사한 Key를 찾아야 정확한 Value값도 찾을 수 있겠죠? 그렇기 때문에 Query와 Key 사이에 유사도를 구하는 과정이 추가됩니다. 이때 코사인 유사도(Cosine Similarity)를 사용합니다. 코사인 유사도는 -1 ~ +1 사이의 값을 가집니다.
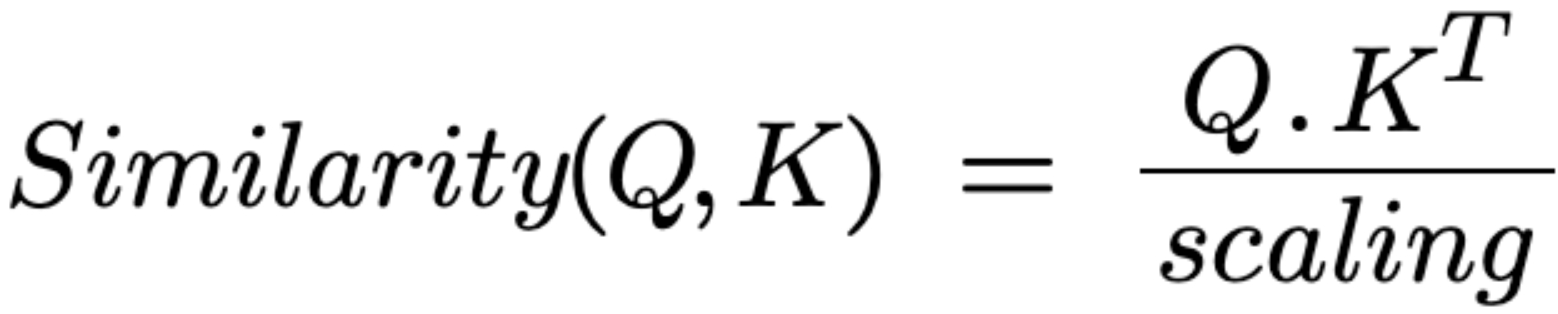
그렇다면 Q, K, V 벡터는 어떻게 얻는 것일까요?? 예문으로 계속 쓰고 있는 "I am a student."에서 "student" 단어 벡터를 Q, K, V 벡터로 변환하는 과정에 대해 알아보겠습니다. 여기서 단어 벡터는 기존의 단어 벡터에 positional encoding을 더해준 후 얻은 값입니다.
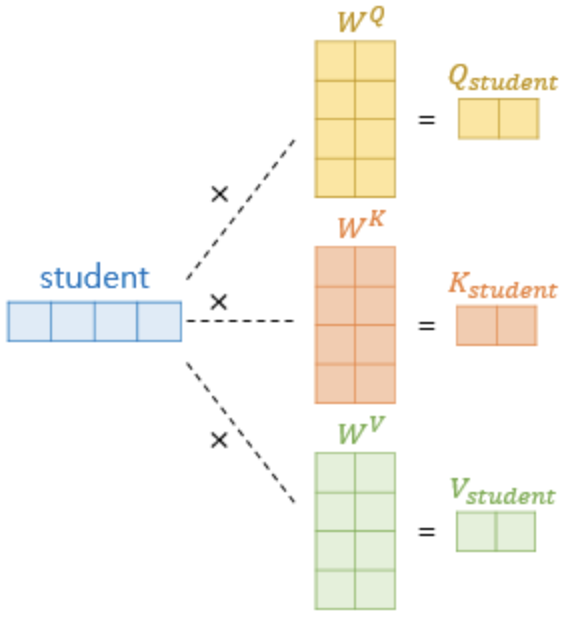
위 그림처럼 기존의 단어 벡터에 Q, K, V를 얻을 수 있는 가중치 행렬을 곱해줌으로써 얻을 수 있습니다. 가중치 행렬은 학습을 통해 계속 업데이트 됩니다. 문장 내의 모든 단어벡터는 위와 같은 과정을 통해 각각의 Q, K, V 벡터를 얻습니다.
2.2.2 Scaled dot-product Attention
각 Q벡터는 모든 K벡터에 대해 attention score를 구합니다. attention score를 구한 뒤 이를 이용해 모든 V 벡터를 weighted sum하여 context vector를 구합니다. 이는 모든 Q 벡터에 대해 반복됩니다. Transformer에서는 단순히 내적만을 사용하는 것이 아니라 내적값을 특정 값으로 나눠줍니다. 아래는 해당 과정의 식입니다.
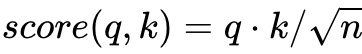
이렇게 값을 scaling하는 과정이 추가되어 이를 Scaled dot-product Attention이라고 합니다. 본 논문에서는 K벡터의 차원을 나타내는 d_k에 루트를 씌운 값을 스케일링 값으로 채택했습니다. 그림을 확인하면 이해가 쉽습니다 :)

이 Attention의 전체적인 과정들은 행렬 연산을 통해 일괄로 처리해줄 수 있습니다. "I am a student."를 이용해 살펴보겠습니다. 먼저, Q, K, V 벡터를 구하는 과정입니다.

다음은 각 단어들에 대해 attention score를 구하는 과정입니다. 결과물로 나오는 행렬에서 student행과 I열의 값은 student의 Q벡터와 I의 K 벡터의 attention score 값입니다.

이제 attention score행렬에 softmax함수를 적용하고 V 행렬을 곱함으로써 모든 단어에 대한 attention 값만 구해주면 됩니다!
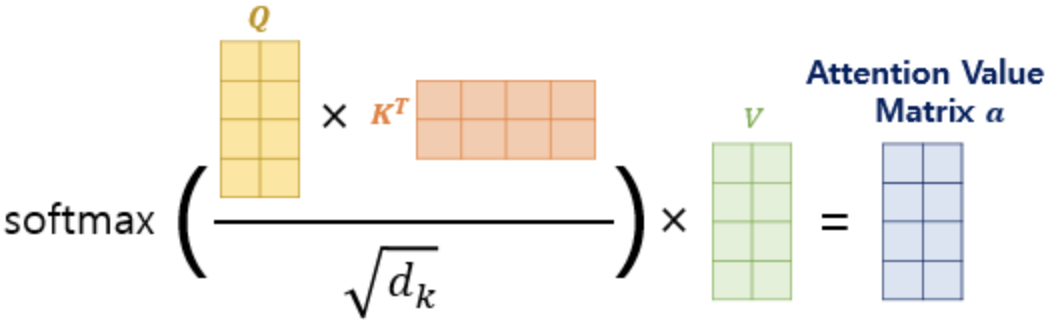
논문에 기재된 수식과 동일하게 진행되는 것을 확인 할 수 있습니다.
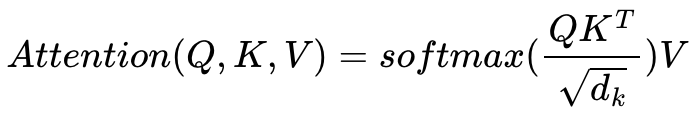
여기까지가 Attention의 전반적인 과정입니다. Self-Attention 은 이러한 과정을 자기 자신에게도 수행하기 때문에 self라는 단어가 붙은 것입니다.

그렇다면 self attention이 일반적인 attention에 비해 가지는 장점은 무엇일까요? "The animal didn't cross the street because it was too tired." 라는 문장에서 "it"은 "animal"을 의미합니다. 인간은 쉽게 알 수 있지만 컴퓨터에게는 좀 어렵습니다. 하지만 self-attention을 이용한다면 문장내의 모든 단어들과 유사도를 구하기 때문에 의미하는 단어를 쉽게 파악할 수 있습니다.
2.2.3 Multi-Head Attention
attention을 한 번 적용하는 것 보다 병렬적으로 여러 번 적용하는 것이 더 효과적이기 때문에 사용하는 방법입니다. 본 논문에서는 총 8개(parameter: num_heads)의 병렬 attention을 적용하게 됩니다.
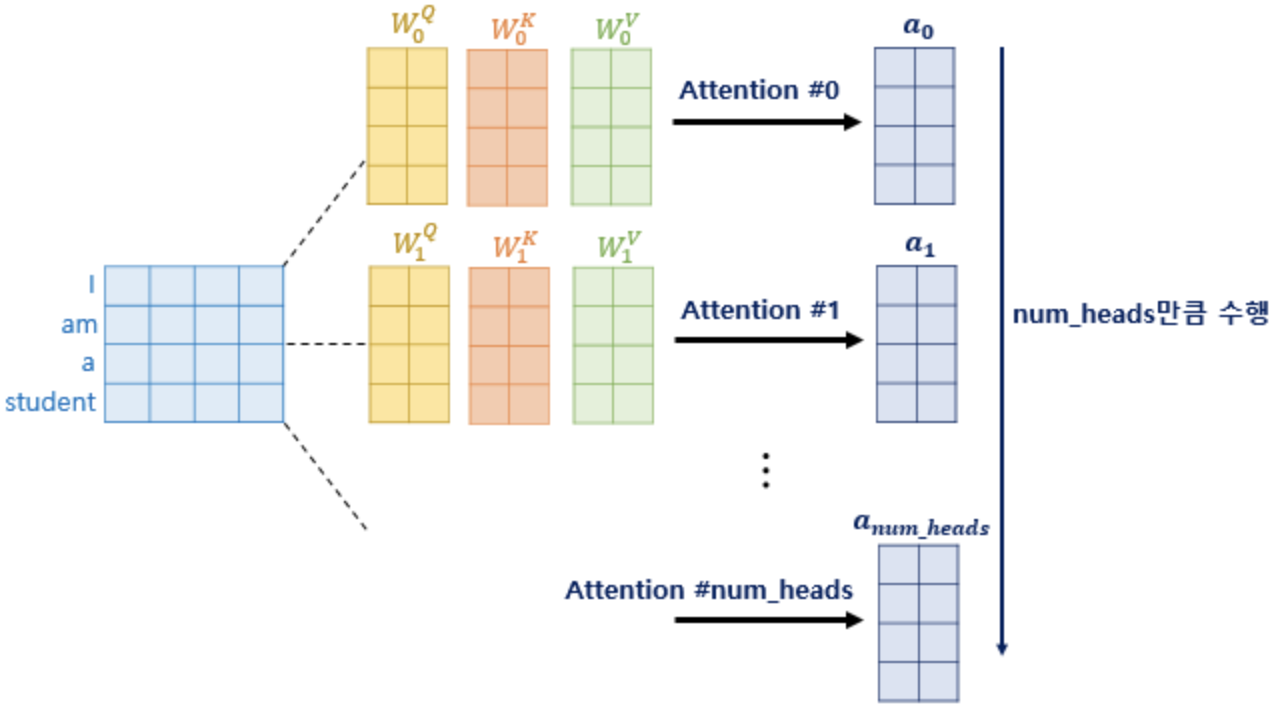
각각의 attention 값 행렬을 attention head라고 하고 각 가중치 행렬은 모두 다른 값을 가지도록 학습됩니다. Multi-Head Attention의 효과에 대해 좀 더 자세하게 알아보겠습니다 :)
가장 큰 장점은 attention을 병렬로 수행함으로써 다양한 시각으로 정보를 수집할 수 있다는 점입니다. 바로 위의 "The animal didn't cross the street because it was too tired." 문장에서 "it"이 query로 주어지는 경우를 생각해보겠습니다. Multi-Head Attention을 이용하면 다른 단어 벡터들과 유사도를 구할 때 첫번째 헤드는 "animal"과 유사도를 높게, 두번째 헤드는 "tired" 와 유사도를 높게 볼 수 있습니다. 이렇게 여러 개의 attention head가 모두 다른 시각으로 정보를 살펴보게 됩니다.
병렬 attention이 끝나면, 모든 head들을 concat 합니다. 그리고 모두 concat 한 행렬은 또 다른 가중치 행렬을 곱해주는데, 이렇게 구해진 행렬이 Multi-Head Attention의 최종 결과 벡터입니다.

여기까지가 Transformer에서 가장 핵심이라고 할 수 있는 self-attention에 대한 설명입니다. 다음 포스팅에서는 Transformer의 전반적인 작동 과정에 대해 포스팅하겠습니다 :)
이 포스팅은 아래 글들을 참고하여 작성하였습니다.
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] Inductive Bias (1) | 2023.10.01 |
|---|---|
| [딥러닝 기본지식] Self Attention과 Transformer (2) (0) | 2023.08.24 |
| [딥러닝 기본지식] Auto Regressive Models (0) | 2023.05.07 |
| [딥러닝 기본지식] Diffusion Model (0) | 2023.05.01 |
| [딥러닝 기본지식] 다양한 Convolution 기법_with pytorch (2) (0) | 2023.04.23 |