이번 포스팅에서는 Text-to-image에서 많이 사용되는 Auto Regressive Model에 대해 작성하겠습니다 :)
1. Auto Regressive(AR) Model 이란?
자기 자신을 입력 데이터로 하여 스스로를 예측하는 모델입니다. 현재 time step까지 생성한 결과를 이용해 다음 시점의 output을 예측합니다. 그렇기 때문에 현재 time step의 데이터는 이전 time step의 모든 데이터에 대해 의존성을 갖게 됩니다. 아래 그림은 개념도와 likelihood식입니다.
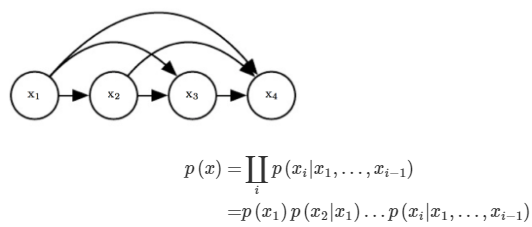
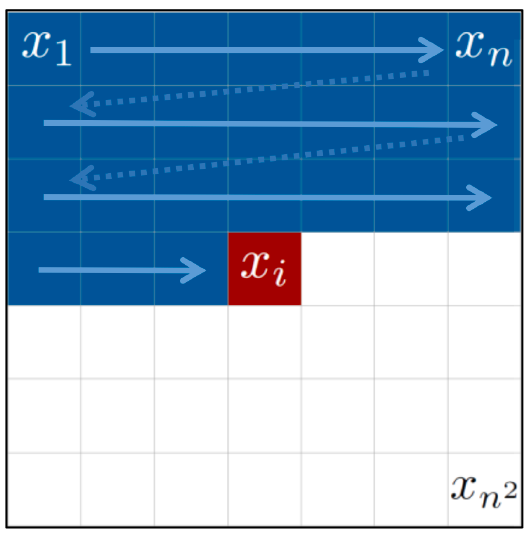
Auto Regressive Generative Model은 데이터를 생성해내는 과정에서 이전 time step까지의 모든 정보에 기반을 두고 생성하는 모델입니다. low resolution 이미지를 high resolution 이미지로 변환하는 작업을 수행하는 모델이 이에 해당합니다. 아래 그림은 output이 될 high resolution의 픽셀 단위 예측 모습입니다. 현재 픽셀 x_i를 예측할 때 이전 픽셀의 결과를 활용합니다.
1.2 Auto Regressive(AR) Model의 장단점
=> 장점
- 정의하기가 쉽습니다.
- Generation 과정이 쉽습니다. 매 time step마다 예측된 결과물을 다음 time step의 새로운 입력으로 넣어주는 것을 반복하면 됩니다.
- 이미지, 오디오, 비디오 생성에서 log-likelihood의 결과가 좋습니다.
=> 단점
- 순서를 정의하는 방법에 따라 결과가 크게 달라질 수 있습니다. 학습과 generation과정 모두에 예측 값이 입력으로 사용되기 때문입니다.
- Generation 과정이 너무 오래 걸립니다. 학습과정에서는 병렬화가 가능하긴 하지만, 그럼에도 sequential generation 특성상 속도가 느릴 수 밖에 없습니다.
2. 다양한 Auto Regressive Model들
2.1 PixelRNN
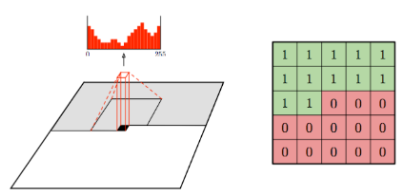
RNN은 sequential한 data 처리에 특화된 딥러닝 모델입니다. 이미지의 픽셀 하나하나를 sequence로 생각합니다. 아래 그림에서 알 수 있듯이 이미지의 임의의 픽셀은 이전 픽셀들(왼쪽 위 픽셀)로 부터 영향을 받습니다.

PixelRNN에 속하는 모델에는 대표적으로 Row LSTM과 Diagonal BiLSTM이 있습니다.
먼저 Row LSTM입니다.
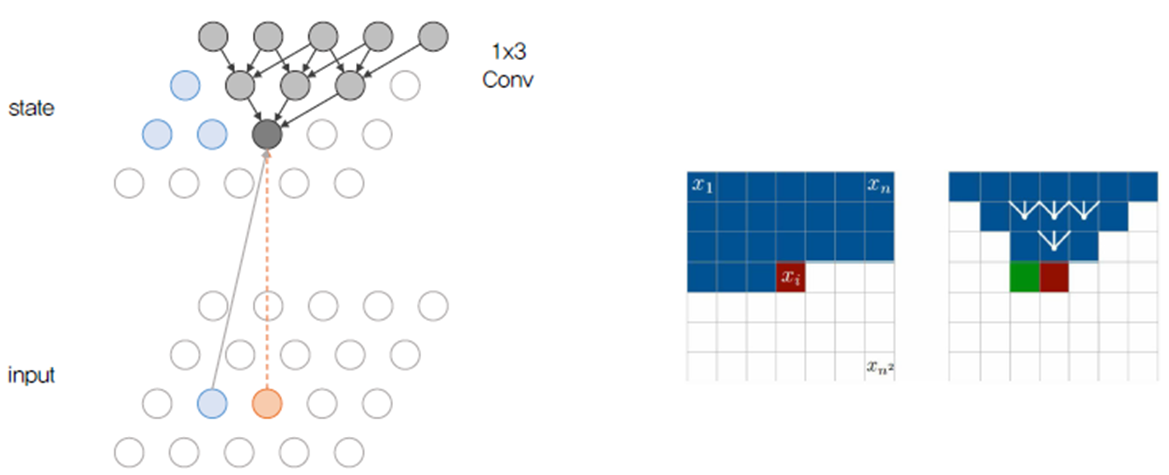
Feature map 상에서 target state보다 위에 존재하는 state의 정보들만 반영합니다. input과 state, output이 모두 같은 크기이고 계산량을 줄이기 위해 Convolution을 사용했습니다. Receptive field는 작아지는 단점이 있지만, 계산의 효율성이 높아집니다.
두 번째로 Diagonal BiLSTM 입니다.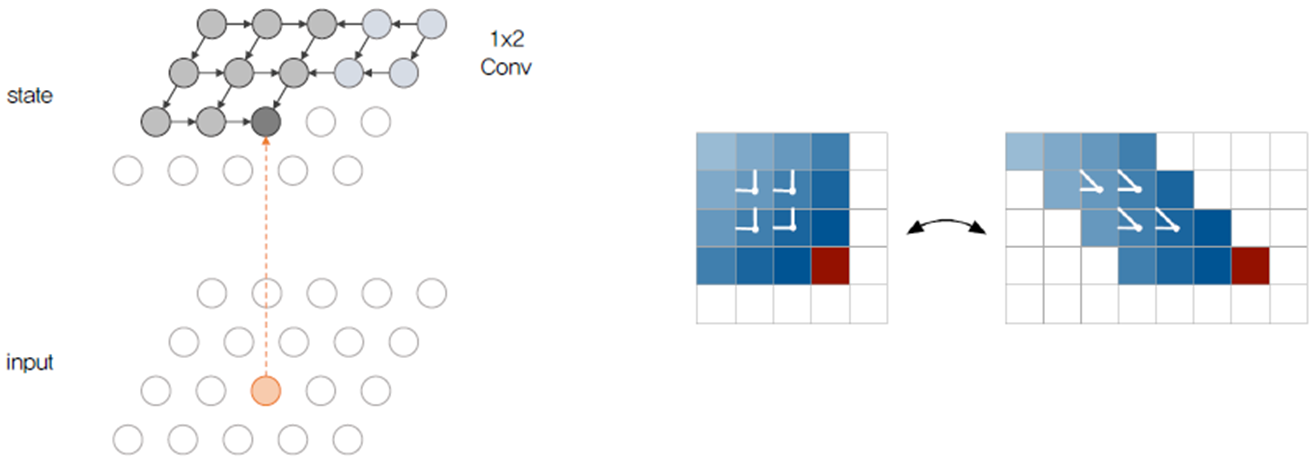
2.2 PixelCNN
CNN 모델 자체는 sequential한 data를 처리하는데 적합하지 않지만 Masked Convolution Filter를 사용하면 가능합니다. 예측해야 하는 time의 픽셀과 아직 예측하지 않은 미래 step의 픽셀은 0으로 셋팅하고 일반적인 Convolution layer처럼 사용하면 Auto Regressive Modeling을 할 수 있습니다.
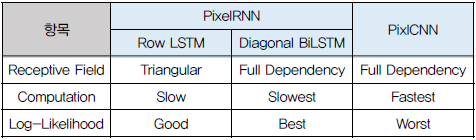
성능면에서 위 3개의 모델을 비교해보면 아래 표와 같습니다!
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] Self Attention과 Transformer (2) (0) | 2023.08.24 |
|---|---|
| [딥러닝 기본지식] Self Attention과 Transformer (1) (0) | 2023.08.19 |
| [딥러닝 기본지식] Diffusion Model (0) | 2023.05.01 |
| [딥러닝 기본지식] 다양한 Convolution 기법_with pytorch (2) (0) | 2023.04.23 |
| [딥러닝 기본지식] 다양한 Convolution 기법_with Pytorch (1) (0) | 2023.04.22 |