이번 포스팅에서는 Generative Model 중에서 최근 활발하게 연구되고 있는 Diffusion Model에 대해 작성하겠습니다.
먼저, Generative Model이 무엇인지에 대해서 부터 알아보겠습니다.
1. Generative Model 이란?
Generative Model 은 입력으로 주어지는 데이터 x로 부터 샘플링된 분포(distribution)를 평가하는 모델을 말합니다. 가장 유명한 것으로 GAN이 있죠! 딥러닝 모델이 분포를 평가한다는 것은 정확히 무슨 의미일까요?
분류 모델의 경우에는 모델의 output이 분류해야 할 class들 중 하나입니다. 하지만 생성 모델에서는 output이 분포를 결정짓는 값입니다. 즉, 주어진 데이터가 나올 확률을 의미합니다. 주어진 데이터의 가능도(likelihood)를 계산할 수 있고, 이를 바탕으로 새로운 데이터를 생성 할 수 있습니다. 정리하자면 학습 데이터들의 분포를 따르는 새로운 데이터를 생성해내는 모델을 의미합니다.
2. Diffusion Model이란?
Diffusion 의 단어 뜻은 "확산"입니다. 특정한 물질이 조금씩 퍼져나가면서 같은 농도로 바뀌는 현상을 말합니다. 이 과정을 거치면 물질들의 특정한 분포가 서서히 와해되어 갑니다.
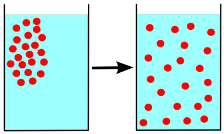
데이터들의 특정한 패턴이 반복적인 과정을 거쳐 서서히 와해되는 과정을 Diffusion Process 라고 합니다.
Diffusioin Model은 새로운 데이터를 생성해내는 Generative Model 중 하나로, data로 부터 noise를 조금씩 더해가며 고의적으로 패턴을 무너뜨리는 Noising 단계와 이를 다시 복원하는 과정(Denoising)을 통해 데이터를 생성하는 모델입니다. 이때 Noising 단계를 Diffusion Process라 하고, Denoising 단계를 Reverse Process라고 합니다. 이를 그림으로 나타내면 아래와 같습니다.

다시 정리하자면, 위 그림의 오른쪽에서 왼쪽으로 noise를 점점 추가하는 process를 학습하고, 이를 반대로 예측하는 reverse process를 학습함으로써 noise로 부터 data를 복원하는 과정을 학습합니다. 역시, 실제 데이터의 분포를 찾아내는 것을 목적으로 학습니다. reverse process가 잘 학습 됐다면 랜덤한 noise로 부터 우리가 원하는 이미지, 텍스트 등을 생성해 낼 수 있습니다.
딥러닝 분야에서는 최근에 비지도학습에 많이 사용되고 있고, 이미지 생성 task에서 높은 성능을 보이고 있습니다.
2.1 Diffusion Process(Noising)
이 단계는 입력 데이터 x에 매 time step마다 gaussian noise를 추가하는 것입니다.

시작인 0 step에서 noise를 추가하면서 마지막 step인 T step으로 가게되고, 각 step에 noise가 추가된 것이 잠재 변수( latent variable) z 입니다. 이를 식으로 표현하면 아래와 같습니다.
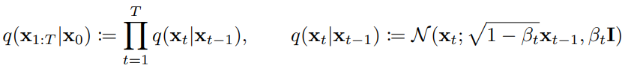
위 식을 풀어서 설명하자면 이전 step의 잠재 변수 z에서 root(1-B_t)만큼 가져오고 B_t 만큼 noise를 추가하여 잠재변수 z_t를 계산하는 것입니다. 여기서 B는 noise의 양으로 직접 지정해 줄 수 있습니다. step이 진행될수록 더 큰 noise가 적용되도록 합니다. B 값을 스케쥴링하는 방법에는 크게 Linear, Sigmoid, Quadratic 방법이 있는데 각각의 방법을 적용하여 noise를 추가하면 아래와 같은 결과를 확인 할 수 있습니다.

정리하자면 diffusion process 단계에서는 가우시안 분포를 갖는 직접 지정해준 B_t 값 만큼의 noise를 매 step마다 추가합니다.

2.2 Reverse Process(Denoising)
Diffusion Process에서 추가했던 noise 데이터에서 noise를 제거해가며 원래의 데이터로 복원하는 과정입니다. 이 과정이 바로 생성 단계입니다. Diffusion Process의 noise는 직접 Gaussian distribution를 갖도록 정의해주었지만 이를 복원하는 Reverse Process의 distribution은 현재 모르는 상태입니다. 학습을 통해서 이 분포를 학습하는 것입니다. 이를 수식으로 나타내면 아래와 같습니다.
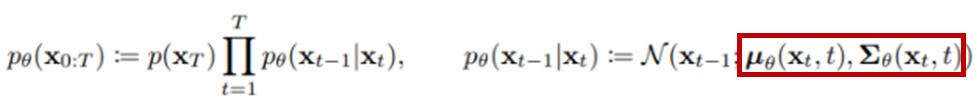
첫번째 식의
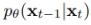
부분은 Reverse Process의 분포를 모델이 추정한 것입니다. 이 분포 역시 가우시안 분포를 따르도록 합니다. 따라서, 모델이 학습하는 것은 이 가우시안 분포의 파라미터인 평균과 분산을 학습하는 것입니다. 식의 붉은 색 박스 부분이 바로 학습하는 변수에 해당합니다.
2.3 Training
그렇다면 diffusion model은 평균과 분산의 추정을 위해 어떻게 학습할까요? 모델을 학습하는 목적은 실제 데이터의 분포인 p_theta를 찾아내는 것입니다. 이를 다시 말하면 이의 likelihood를 최대화 하는 것이 우리의 목적입니다. 이를 바탕으로 하는 loss를 식으로 나타내면 아래와 같습니다.

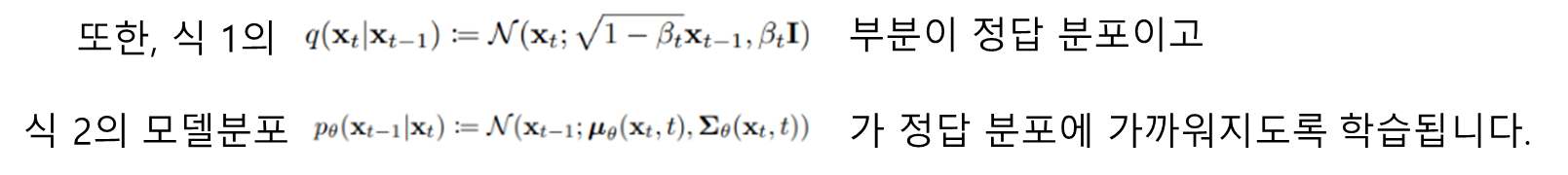
* 아래는 Diffusion Model의 간단한 튜토리얼입니다.
https://github.com/acids-ircam/diffusion_models
이 포스팅은 아래 글들을 참고하여 작성하였습니다 :)
https://www.lgresearch.ai/blog/view?seq=190&page=1&pageSize=12
https://drive.google.com/file/d/17kBC7d3x-GfuEevc9N1fb1FeSKUsZ6vY/view
'AI Research > Deep Learning' 카테고리의 다른 글
| [딥러닝 기본지식] Self Attention과 Transformer (1) (0) | 2023.08.19 |
|---|---|
| [딥러닝 기본지식] Auto Regressive Models (0) | 2023.05.07 |
| [딥러닝 기본지식] 다양한 Convolution 기법_with pytorch (2) (0) | 2023.04.23 |
| [딥러닝 기본지식] 다양한 Convolution 기법_with Pytorch (1) (0) | 2023.04.22 |
| [딥러닝 기본지식] 딥러닝 프레임워크 비교(Tensorflow, Keras, Pytorch) (0) | 2023.03.04 |