Kaggle의 'Adult Census Income' 데이터를 이용하였습니다.
▶ 결측치 찾기(자세한 내용은 링크를 참조해주세요)
-결측치가 있는 행을 찾아주는 코드는 아래와 같습니다.
train[train.apply(lambda x: "?" in list(x), axis=1)] ## 물음표 있는 row만 찾아줍니다.
- 'age'가 30이상이고 'workclass'가 '?'인 행을 찾아 workclass의 값을 'No'로 바꿔줍니다.
train.loc[(train.age >= 30)&(train.workclass=='?'), 'workclass'] = 'No'
train.workclass.value_counts()
▶ 이상치 처리
-이상치 확인해보기
train.describe()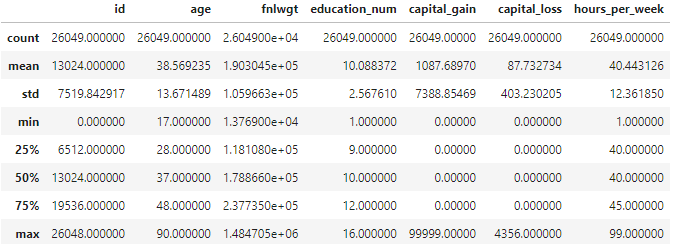
describe()함수로 확인해봤을 떄 capital_gain의 max값이 99999입니다. capital_gain의 의미와 다른 값들을 확인해보았을 때 이 값이 이상치일 가능성이 존재합니다.
- 이상치 확인을 위해 값 정렬 해보기
train.loc[train.capital_gain < 99999].sort_values('capital_gain', ascending=False)capital_gain의 값이 99999보다 작은 행들을 찾아 내림차순으로 정렬합니다.
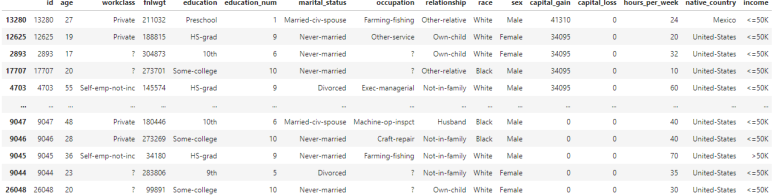
결과는 위와 같습니다. 99999바로 아래 값이 41310임을 확인했고, 99999는 어느정도 이상치일 수 있다고 판단할 수 있습니다.
- log 표현
이상치를 보정하기 위해 capital_gain의 값을 log transformation(로그 변환)을 시켜준 후 log_capital_gain이라는 새로운 열을 만들어 줍니다.
train["log_capital_gain"] = train.capital_gain.map(lambda x: np.log(x, where=(x!=0)))
train[['capital_gain', 'log_capital_gain']].describe()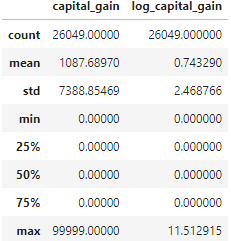
▶ Scaling
- Min-max Scaler : 범위가 정해진 값이 필요할 때 주로 사용합니다. 이상치에 민감하다는 단점이 있습니다.
- Standard Scaler : 평균은 0, 표준 편차는 1이 되는 정규 분포의 성질을 가지도록 만듭니다. Min-max scaler에 비해 이상치에 영향을 덜 받습니다.
아래 코드처럼 scaler를 선언해준 뒤 사용하면 됩니다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mm_scaler = MinMaxScaleraler()
st_scaler = StandardScaler()이제 fit_transform 과 transform 함수로 scaling 해주면 됩니다. 두 함수의 차이는 아래와 같습니다.
- fit_transform() : 학습데이터에 사용하는 함수입니다. 학습 모델은 학습 데이터에 있는 평균과 분산을 학습하게 되는데 이렇게 학습된 Scaler의 parameter는 학습 데이터를 scaler하는데 사용됩니다.
- transform() : 테스트 데이터에 사용하는 함수입니다. 학습 데이터로부터 학습된 평균과 분산 값을 테스트 데이터에 적용해줍니다.
=> 만약 fit_transform 을 테스트 데이터에도 적용하게 되면 테스트 데이터로 부터 새로운 평균과 분산을 얻게 됩니다. 이렇게 되면 테스트 데이터도 학습에 사용해버리게 되는 것입니다. 테스트 데이터는 학습때 한번도 보지 못한 데이터여야 하는데 이 데이터를 학습해버리면 제대로 모델을 평가할 수가 없습니다. 예시를 들어보자면,
train=[2,3,4,5] / test=[2,3,4,6] 이라는 데이터가 있을 때, Min max scaler에 fit_transform을 하면 최솟 값인 2는 0으로, 최댓 값인 5는 1로 매핑됩니다. 그런데 테스트 데이터에는 학습시에 보지 못한 6이라는 데이터가 들어있습니다. 이때는 train과 test를 같은 조건으로 맞춰야 하기 때문에 학습 데이터에 맞게 6을 1.2로 매핑해주어야 합니다.
train['MM_fnlwgt'] = mm_scaler.fit_transform(train['fnlwgt'].values.reshape(-1,1))
test['MM_fnlwgt'] = mm_scaler.transform(test['fnlwgt'].values.reshape(-1,1))
train['ST_fnlwgt'] = st_scaler.fit_transform(train['fnlwgt'].values.reshape(-1,1))
test['ST_fnlwgt'] = st_scaler.transform(test['fnlwgt'].values.reshape(-1,1))처음 fit_transform을 적용하면 'fnlwgt'의 통계치에 관한 정보가 들어있습니다. 때문에 아래와 같은 코드로 통계치 정보를 조회해볼 수 있습니다.
mm_scaler.data_max_ ## array([1484705.])따라서 mm_scaler를 가지고 transformer함수를 적용하면 이 통계치로 test에 적용할 수 있습니다.
train.describe()[['MM_fnlwgt', 'ST_fnlwgt']].round(6)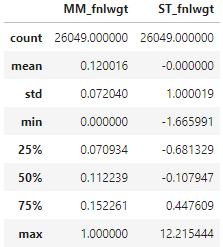
'AI Research > Data Analysis' 카테고리의 다른 글
| [데이터 분석] EDA(Exploratory Data Analysis) (0) | 2023.03.05 |
|---|---|
| [데이터 분석] Feature Engineering (Sklearn) (0) | 2023.03.05 |
| [데이터 분석] 자주 쓰이는 라이브러리 함수(Pandas) (2) | 2023.03.05 |