▶ EDA(Exploratory Data Analysis)란?
탐색적 데이터 분석입니다. 데이터 분석에 있어서 매우 중요한 초기 분석 단계입니다. 쉽게 말해서 데이터가 어떤 형태를 띄고 있는지 견적을 내는 일이다라고 할 수 있습니다. 이 단계가 중요한 이유는 데이터의 특성을 알아야 해결하고자 하는 문제의 해결 방법을 탐색해 볼 수 있기 때문입니다.
간단히 설명하자면, EDA란!
- 시각화를 통해 패턴을 발견하고,
- 데이터의 특성을 확인하고,
- 통계와 그래픽을 통해 가설을 검정하는 과정을 통해 데이터에 대해 알아보는 것입니다.
▶ EDA의 목적
EDA의 목적은 아래와 같습니다.
- 시각화와 통계를 사용해 데이터를 이해하고 살펴볼 수 있습니다.
- 도출하고자 하는 결과의 기본이 되는 가설에 접근하고 가설을 검증할 수 있습니다.
- 가설을 세우기 전 데이터를 이해할 수 있습니다.
=> 가장 궁극적인 목적은 데이터가 어떻게 만들어졌는지에 대한 직관적 발전입니다.
▶ EDA의 대상
EDA의 목표라고 할 수 있는 데이터는 두 가지로 분류할 수 있습니다.
1. Univariate(일변량)
EDA를 통해 파악하려는 변수가 1개인 경우를 말합니다. 데이터를 설명하고 그 안에 어떤 패턴이 존재하는지 찾는 것이 주요 목적입니다.
2. Multi-variate(다변량)
EDA를 통해 파악하려는 변수가 여러개인 경우를 말합니다. 여러 변수들이 어떤 관계를 갖는지 살펴 보는 것이 주요 목적입니다. 여러 변수를 동시에 보기 전에 개별 데이터를 먼저 파악해야 오류 발생을 낮출 수 있습니다.
▶ EDA의 종류
크게 두 가지로 분류할 수 있습니다.
1. Graphic(시각화)
그래프, 그림을 이용해 데이터를 확인하는 방법입니다.
2. Non-Graphic(비시각화)
그래픽적 요소를 사용하지 않고, 주로 summary-statistics를 통해 데이터를 확인하는 방법입니다.
=> 데이터를 graphic EDA를 통해 시각화하여 확인하면 한눈에 파악할 수 있습니다. 반면에 non-graphic한 방법을 선택한다면 정확한 값을 확인해볼 수 있습니다.
▶ EDA의 유형
위에서 설명한 대상과 종류에 따라 4가지로 나눌 수 있습니다.
1. Uni-Non Graphic(일변량 비시각화)
주어진 데이터의 분포를 확인하는 것이 주목적입니다. Numeric data 인지, Categorical data인지에 따라 확인할 수 있는 것들이 조금 다릅니다.
- Numeric data
● Center(Mean, Median, Mod),
● Spread(Variance, SD, IQR, Range)
● Modality(Peak)
● Shape(Tail, Skewness, Kurtosis)
● Outliers
- Categorical data
●Occurence
●Frequency
●Tabulation
2. Uni-Graphic(일변량 시각화)
주어진 데이터를 전체적으로 살펴보는 것이 주목적입니다. Histogram, Pie chart, Stem-leaf plot, Boxplot, QQplot(데이터의 실제 분포와 이론상 분포가 일치하는지 확인하는 방법) 등이 있습니다.
3. Multi-Non Graphic(다변량 비시각화)
주어진 둘 이상의 변수 사이의 관계를 확인하는 것이 주 목적입니다. Cross-Tabulation(Categorical data에 사용), Cross-Statistics(Numerical data에 사용, Correlation, Covariance) 등을 사용합니다.
4. Multi-Graphic(다변량 시각화)
주어진 둘 이사의 변수 사이의 관계를 전체적으로 살펴보는 것이 주목적입니다.
- Categorical data와 Numeric data 로 Multi-Graphic 으로 EDA를 한다면, Boxplots, Stacked bar, Parallel Coordinate, Heatmap등으로 나타낼 수 있습니다.
- Numeric data와 Numeric data 로 Multi-Graphic 으로 EDA를 한다면, Scatter Plot등으로 나타낼 수 있습니다.
▶ EDA를 잘 하려면?
- raw data의 description, dictionary를 통해 각 데이터의 행과 열의 의미를 이해해야 합니다.
- 결측치를 잘 처리할 수 있어야 하며, 추가적인 데이터 필터링 기술이 필요합니다.(범주형 데이터를 수치형 데이터로 변환)
- 쉽게 시각화 할 수 있는 기술이 있어야 합니다.
▶ EDA 직접 해보기
미국 성인 인구조사 데이터 셋을 이용한 소득 예측 데이터를 이용해 kaggle에서 직접 EDA를 해보았습니다. EDA후 모델 훈련, 예측까지 해보겠습니다. 코드는 이곳에서 확인할 수 있습니다.
- 필요 라이브러리 import 및 데이터 읽어오기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
train = pd.read_csv('train.csv')
- 전체 데이터 살펴 보기
train.head()
- 전체 데이터의 통계치 살펴보기
train.describe()
- Null 데이터 확인하기
import missingno as msno
msno.matrix(train) ##null 데이터 확인
- 'age' 열 밀도 함수로 확인하기
sns.kdeplot(train['age'])
- 'workclass' 확인하기
fig, ax= plt.subplots(1,1,figsize=(12,5))
sns.countplot(data=train, x='workclass', ax=ax)
plt.show()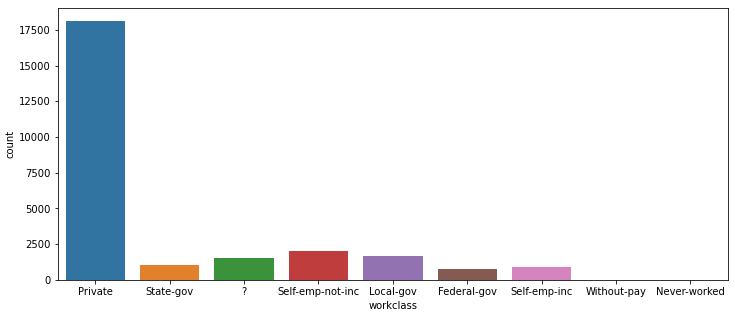
-'race'와 'sex' 사이의 관계 살펴보기
fig, ax= plt.subplots(1,1,figsize=(12,5))
sns.countplot(data=train, x='race', ax=ax, hue='sex')
plt.show()
- 모델에 적합한 input만들기
모델을 통해 예측해야하는 'income' 에 대한 feature는 따로 인코딩하여 저장하겠습니다. '>50K'와 '<=50K'를 각각 1과 0으로 바꿔주겠습니다.
train['income'] = (train['income'] != '<=50K').astype(int)
- 'race'와 'sex'에 따른 income의 평균 피벗 테이블로 나타내기
race로 먼저 묶고, sex로 묶은 다음 평균을 낸것입니다.
train.groupby(['race', 'sex'])[['income']].mean().style.background_gradient(cmap='Purples')
위와 동일한 내용을 pandas를 이용해 해보겠습니다.
pd.pivot_table(train, columns='sex', index='race', values='income',aggfunc='mean')
- 데이터의 분포 확인하기
fig, ax=plt.subplots(1,1, figsize=(10,6))
sns.boxplot(data=train, x='race', y='age', hue='sex')
sns.violinplot(data=train, x='race', y='age')
- numeric data에 대한 상관 계수( 두 변수 사이의 통계적 관계)를 표와 heatmap으로 확인해보기
train.corr() ## 상관계수(숫자형 데이터)
train.corr().style.background_gradient(cmap='coolwarm')
# 다양한 heapmap
sns.heatmap(corr)
sns.heatmap(corr, square=True, linecolor='white', linewidth='0.1', cmap='coolwarm',
vmax=1.0, vmin=-1.0)

- 라벨 인코딩
from category_encoders.ordinal import OrdinalEncoder
LE_encoder = OrdinalEncoder(list(train.columns))# 모든 컬럼에 대해 인코딩 진행
train_le = LE_encoder.fit_transform(train, target)
test_le = LE_encoder.transform(test)
- 모델 학습하기
Decision Tree를 이용해 학습 해보겠습니다.
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier()
dt_clf.fit(train_le, target)
- 테스트 셋을 이용해 예측하기
dt_clf.predict(test_le)
'AI Research > Data Analysis' 카테고리의 다른 글
| [데이터 분석] Feature Engineering (Sklearn) (0) | 2023.03.05 |
|---|---|
| [데이터 분석] Data Preprocessing (Pandas) (0) | 2023.03.05 |
| [데이터 분석] 자주 쓰이는 라이브러리 함수(Pandas) (2) | 2023.03.05 |