Kaggle의 'Adult Census Income' 데이터를 이용하였습니다.
▶ 인코딩(Encoding)
모델이 이해하기 힘든 형태의 feature 혹은 애매하게 잘못 학습될 가능성이 있는 feature들을 의미적인 관점에서 변화시켜줍니다. 인코딩의 결과에 의해서 알고리즘이 보는 feature의 의미적인 특징이 드러나게 됩니다.
one-hot encoding과 label encoding, Mean encoding 에 대해 설명하겠습니다.
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
1. one-hot encoding
categorical encoding이라고도 하며, 범주형 변수에 대해 각 클래스별 독립적인 feature를 생성합니다.
dataframe내의 'workclass' 열을 인코딩 해보겠습니다.
oe = OneHotEncoder()
oe_result = oe.fit_transform(train['workclass'].values.reshape(-1, 1)).toarray()
oe_result.shape ## (26049, 9)
oe_result를 출력해보면 위와 같습니다. 'workclass' 에는 총 9개의 클래스가 존재하고 각 번호가 어떤 클래스에 해당하는지 알고싶다면 get_feature_name함수를 이용하면 됩니다.
oe.get_feature_names(['workclass'])
인코딩된 값을 기존 dataframe에 추가하는 방법은 아래와 같습니다.
sub=pd.DataFrame(data=oe_result, columns=oe.get_feature_names(['workclass']))
pd.concat([train, sub], axis=1)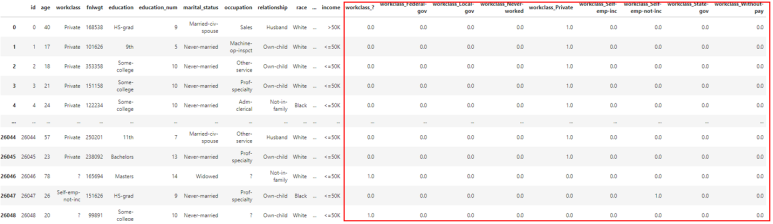
기존 dataframe의 뒤쪽에 원-핫 인코딩 결과물이 추가된 것을 확인할 수 있습니다.
모든 행에 대해 한번에 원-핫 인코딩을 해주고싶다면 pandas의 get_dummies 함수를 사용하면 됩니다!
pd.get_dummies(train)
2. Label encoding
순서가 있는 변수에 대해서 단순 숫자로 넘버링합니다. 라벨의 순서를 정할 수 없고, 느리다는 단점이 있습니다. 이번에도 'workclass'열을 인코딩 해보겠습니다.
le = LabelEncoder()
le_result = le.fit_transform(train['workclass'].values.reshape(-1, 1))
le_result.shape ## (26049,)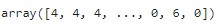
인코딩 결과는 위와 같습니다. 각 행의 'workclass' 열의 클래스가 숫자로 넘버링 되었습니다. 각 번호가 어떤 클래스에 해당하는지 알고싶다면 unique()함수를 이용하면 됩니다.
train['workclass'].unique()
3. Mean edcoding
약간 변칙적인 방법에 속합니다. 해당 feature의 각 클래스 별 target분포를 바탕으로 feature값을 매핑합니다. positive 비율의 정보를 feature로 사용하는 것이 그 예중 하나입니다. 만약 남자의 positive 비율이 60%라면 남자라는 클래스는 0.6으로 인코딩해주면 됩니다. 성능이 좋아질 수는 있지만 오버피팅이 발생할 확률이 높아진다는 단점이 존재합니다. 'income'에 대한 정보를 이용해 'sex'를 인코딩 하겠습니다.
male_positive = train.loc[train['sex']=='Male', "income"]
female_positive = train.loc[train['sex']=='Female', "income"]
male_positive.value_counts()
(male_positive.value_counts() / male_positive.shape[0])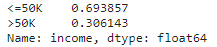
<=50K 인 것의 비율과 >50K인 것의 비율에 맞게 인코딩 되었습니다.
▶ PCA(주성분 분석)
from sklearn.decomposition import PCA
pca = PCA(n_components=60, svd_solver='full')107개의 차원을 60개 차원으로 인코딩해보겠습니다.
먼저 학습에 사용하지 않을 열들을 제거해줍니다. 'income_<=50K' 과 'income_>50K'은 정답 라벨이기 때문에 제거해줍니다.
dummied = dummied.drop(columns=['id', 'income_<=50K', 'income_>50K'])제거 후 shape을 확인해 보면 26049 rows × 107 columns 입니다.
다음은 정규분포로 스케일링 한 후 PCA를 적용해주겠습니다.
X_train_std = st_scaler.fit_transform(dummied)
X_train_pca = pca.fit_transform(X_train_std)
X_train_pca.shapeX_train_pca의 shape을 확인해보면 (26049, 60)입니다. 107개였던 feature의 차원이 PCA를 통해 60으로 줄어들었습니다!
PCA에 사용된 분산과 고유 벡터 등도 확인할 수 있습니다.
pca.explained_variance_ # 60개의 고유값행렬, 가장 큰 분산을 가진 순으로 정렬되어있습니다.
pca.components_ ## 고유 벡터, 107개의 차원이 60으로 나오는 고유값 변환행렬입니다.
'AI Research > Data Analysis' 카테고리의 다른 글
| [데이터 분석] EDA(Exploratory Data Analysis) (0) | 2023.03.05 |
|---|---|
| [데이터 분석] Data Preprocessing (Pandas) (0) | 2023.03.05 |
| [데이터 분석] 자주 쓰이는 라이브러리 함수(Pandas) (2) | 2023.03.05 |