728x90
반응형
논문 링크 : https://ojs.aaai.org//index.php/AAAI/article/view/6783
<Introduction>
[15] 논문과 마찬가지로 강화학습 Q-Learning을 이용하여 장면 그래프를 생성하는 모델입니다. 추가로 메세지 패싱을 위해 Graph Neural Network를 사용하였습니다.
▶Deep Generative Probabilistic Graph Neural Networks(DG-PGNN)
▶Q-learning사용(state, action, reward 존재)
=> State: 현재의 그래프 상태
=> Action: 새로운 노드를 선택하는 것
=> Reward: ground truth와 IoU를 비교하여 결정
▶노드수가 고정된 다른 연구들과 달리 매 스텝마다 그래프에 새로운 노드 추가
<Model>

논문에 포함된 알고리즘 순서도를 이용하여 설명하겠습니다.
1) Input

2) 노드가 추가된 이후 각 노드의 상태와 엣지 상태를 업데이트

3) 추가된 노드의 확률 계산
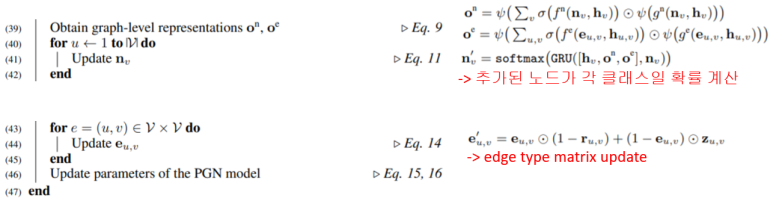
<Result>
Dataset
- Visual Genome
Metrics
- PredCls: relation만 예측
- SGCls: object class와 relation예측
- SGGen: 물체의 영역, class, relation 모두 예측


<결론>
- 강화학습과 GNN을 결합하여 이미지의 캡션과 맥락 정보를 통합하여 정확한 장면 그래프를 구성할 수 있는 모델 제안
728x90
반응형